Editor de shell-awk
Uno, descripción general de awk
1. Principio de funcionamiento
Lea el texto línea por línea, separado por espacio o tabulación de forma predeterminada, guarde los campos separados en variables integradas y ejecute comandos de edición de acuerdo con el modo o condición.
El comando sed se usa a menudo para procesar una línea completa, mientras que awk tiende a dividir una línea en múltiples "campos" y luego procesarla. La lectura de la información de awk también se lee línea por línea, y el resultado de la ejecución se puede imprimir y mostrar con los datos de campo a través de la función de impresión. En el proceso de usar el comando awk, puede usar los operadores lógicos "&&" para significar "y", "||" para significar "o", y "!" Para significar "no"; también puede realizar operaciones matemáticas simples operaciones, como +, -, *, /,%, ^ representan suma, resta, multiplicación, división, resto y potencia, respectivamente.
2. Formato de comando
awk opción 'modo o condición {operación}' archivo 1 archivo 2 ...
awk -f archivo de secuencia de comandos archivo 1 archivo 2 ...
3. Las variables integradas comunes de awk (se pueden usar directamente) son las siguientes:
| mando | sentido |
|---|---|
| FS | Separador de columnas. Especifique el separador de campo para cada línea de texto, el valor predeterminado es un espacio o una tabulación. Igual que "-F" |
| NF | El número de campos en la fila que se está procesando actualmente. |
| NO | El número de fila (número ordinal) de la fila que se está procesando actualmente |
| $ 0 | Todo el contenido de la línea procesada actualmente |
| $ n | El enésimo campo (columna n) de la fila procesada actualmente |
| NOMBRE DEL ARCHIVO | Nombre de archivo que se está procesando |
| RS | Separador de líneas. Cuando awk lee datos de un archivo, cortará los datos en muchos registros de acuerdo con la definición de RS, mientras que awk solo lee un registro a la vez para su procesamiento. El valor predeterminado es '\ n' |
4. Comandos relacionados
① Salida de texto por línea
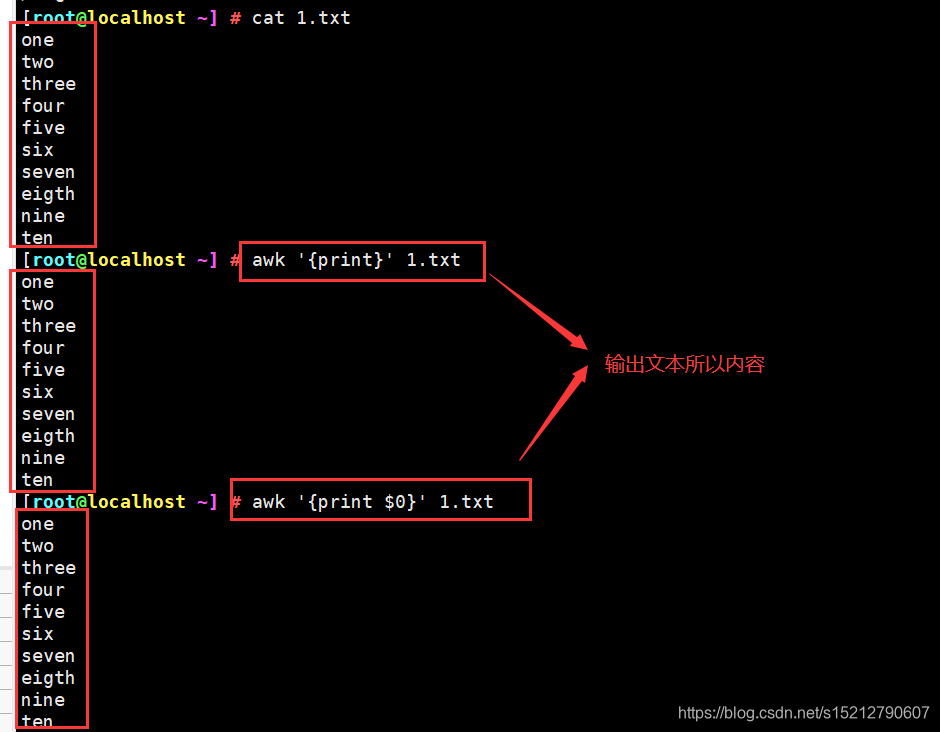
awk '{print}' 1.txt #输出所有内容
awk '{print $0}' 1.txt #输出所有内容
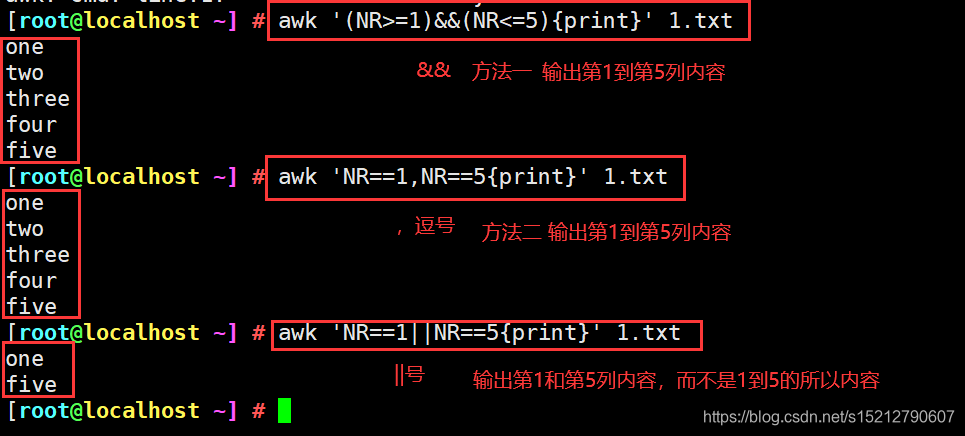
awk '(NR>=1)&&(NR<=5){print}' #输出1到5列内容
awk 'NR==1,NR==5{print}' 1.txt #输出1到5列内容
awk 'NR==1||NR==5{print}' 1.txt #输出第1和第5列内容
awk '(NR%2)==1{print}' 1.txt #输出奇数行内容
awk '(NR%2)==0{print}' 1.txt #输出偶数行内容
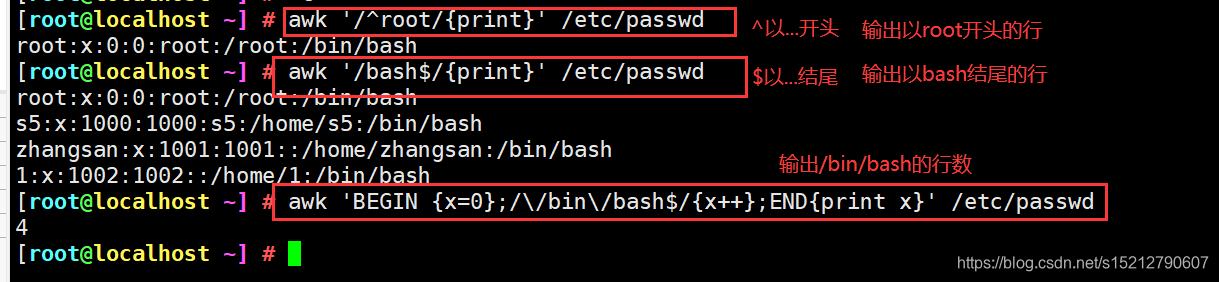
awk '/^root/{print}' /etc/passwd #输出以root开头的行
awk '/bash$/{print}' /etc/passwd #输出以bash结尾的行
awk 'BEGIN {x=0};/\/bin\/bash$/{x++};END{print x}' /etc/passwd #统计/bin/bash结尾的的行数,等同于grep -c "/bin/bash$"
El modo BEGIN significa que antes de procesar el texto especificado, debe realizar la acción especificada en el modo BBGIN: awk luego procesa el texto especificado y luego ejecuta la acción especificada en el modo ENoD. END {} bloque de instrucciones, a menudo pone la resultado Esperando sentencia

②Salida por campo
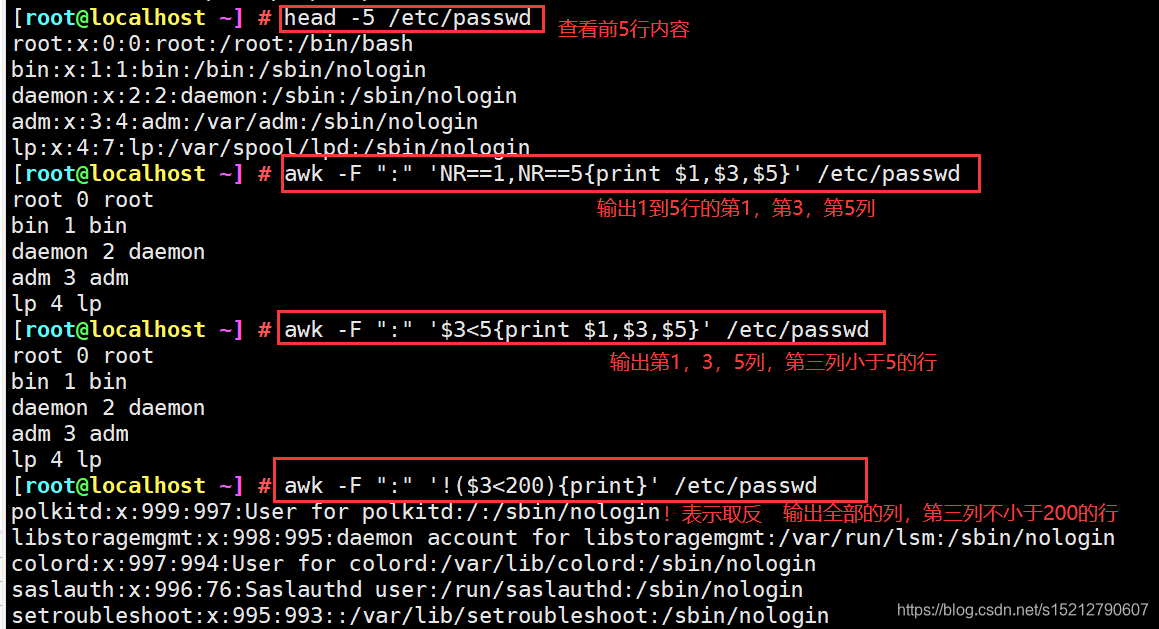
awk -F ":" 'NR==1,NR==5{print $1,$3,$5}' /etc/passwd #输出1到5行的1,3,5列
awk -F ":" '$3<5{print $1,$3,$5}' /etc/passwd #输出1,3,5列,第三列小于5的行
awk -F ":" '!($3<200){print}' /etc/passwd #输出全部列,第三列不小于200的行
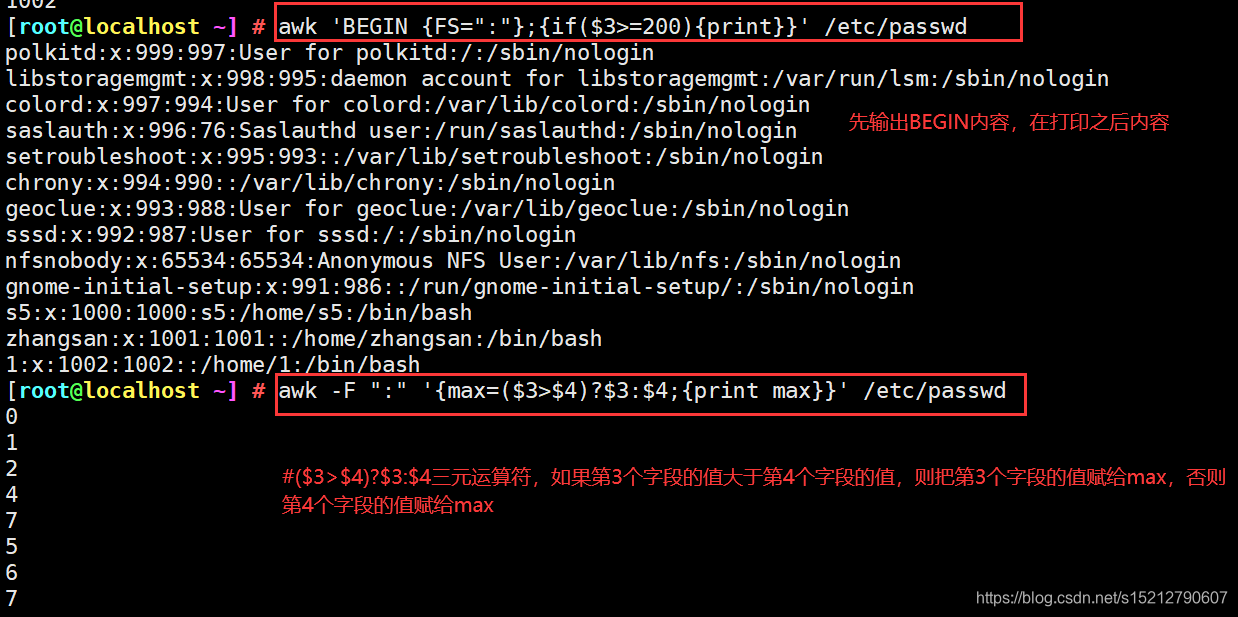
awk 'BEGIN {FS=":"};{if($3>=200){print}}' /etc/passwd #先处理完BEGIN的内容,再打印文本里面的内容
awk -F ":" '{max=($3>$4)?$3:$4;{print max}}' /etc/passwd
#($3>$4)?$3:$4三元运算符,如果第3个字段的值大于第4个字段的值,则把第3个字段的值赋给max,否则第4个字段的值赋给max
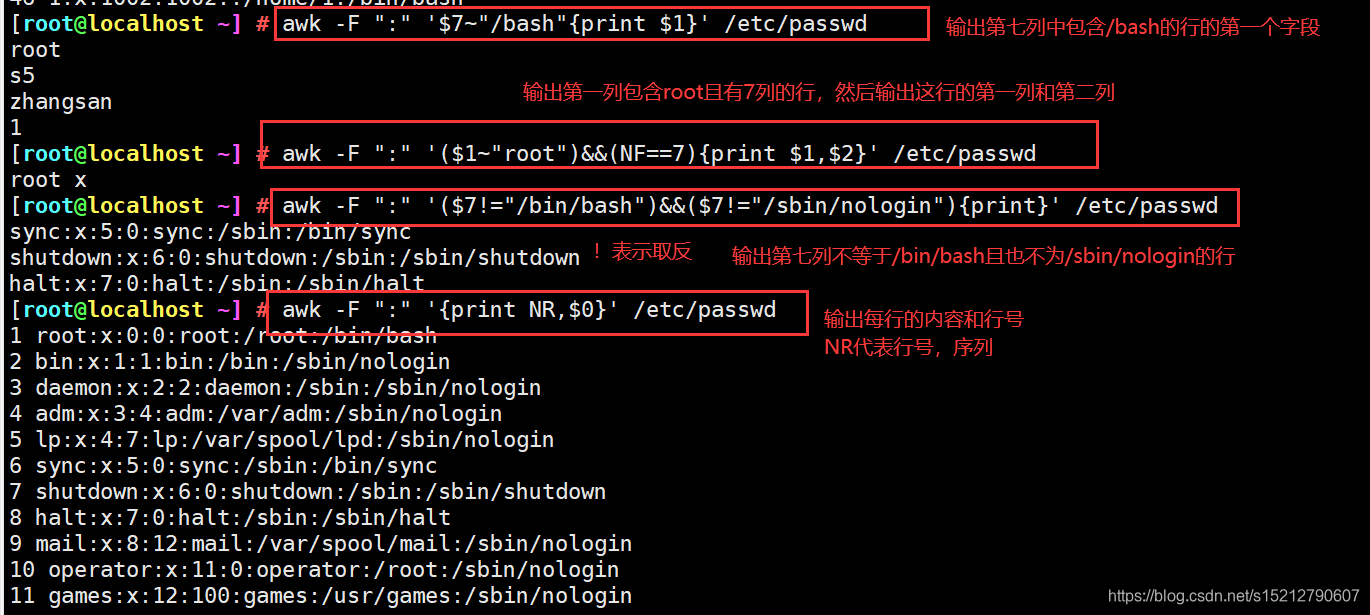
awk -F ":" '$7~"/bash"{print $1}' /etc/passwd #输出以冒号分隔且第7个字段中包含/bash的行的第1个字段
awk -F ":" '($1~"root")&&(NF==7){print $1,$2}' /etc/passwd #输出第1个字段中包含root且有7个字段的行的第1、2个字段
awk -F ":" '($7!="/bin/bash")&&($7!="/sbin/nologin"){print}' /etc/passwd
#输出第7个字段既不为/bin/bash,也不为/sbin/nologin的所有行
awk -F ":" '{print NR,$0}' /etc/passwd #输出每行内容和行号,每处理完一条记录,NR值加1
③ Llamar a los comandos de Shell a través de tuberías y comillas dobles
echo $PATH | awk 'BEGIN{RS=":"};END{print NR}' #统计以冒号分隔的文本段落数,END{}语句块中,往往会放入打印结果等语句
awk -F: '/bash$/{print | "wc -l"}' /etc/passwd #调用wc -l命令统计bash的用户个数,等同于grep -c "bash$"
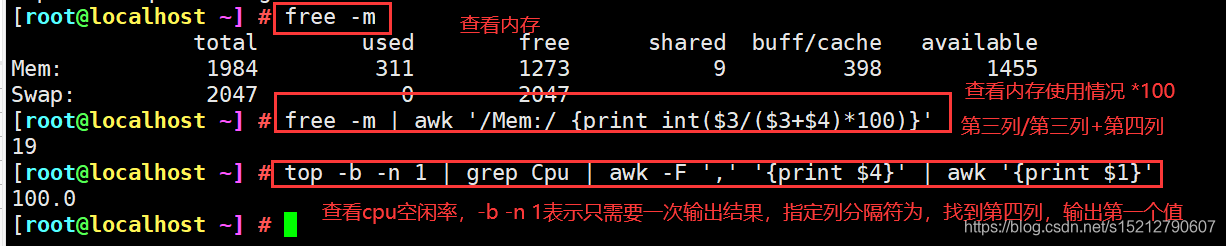
free -m | awk '/Mem:/ {print int($3/($3+$4)*100)}' #查看当前内存使用百分比
top -b -n 1 | grep Cpu | awk -F ',' '{print $4}' | awk '{print $1}' #查看当前CPU空闲率(-b -n 1 表示只需要1次的输出结果)
date -d "$(awk -F "." '{print $1}' /proc/uptime) second ago" +"%F %H:%M:%S"
#显示上次系统重启时间,等同于uptime;second ago为显示多少秒前的时间,+"%F %H:%M:%S"等同于+"%Y-%m-%d %H:%M:%S"的时间格式
awk 'BEGIN {while ("w" | getline) n++ ; {print n-2}"%"}' #调用w命令,并用来统计在线用户数
awk 'BEGIN {"hostname" | getline ; {print $0}}' #调用 hostname,并输出当前的主机名
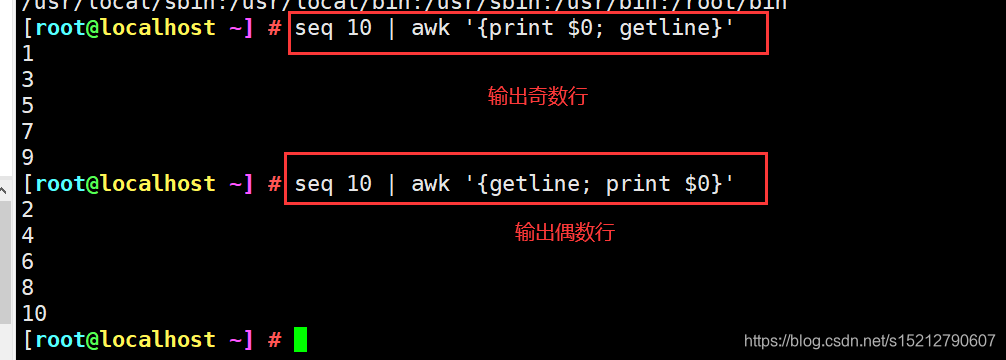
seq 10 | awk '{print $0; getline}'
seq 10 | awk '{getline; print $0}'