Tabla de contenido
- 1. Cadena de estructura de datos subyacente
- Dos, codificación interna de Redis
- Tres, lista enlazada
- Cuarto, el diccionario
1. Cadena de estructura de datos subyacente
Sds (Cadena dinámica simple) es la representación de cadena que se usa
en la parte inferior de Redis, y se usa en casi todos los módulos de Redis.
Las principales funciones de Sds en Redis son las siguientes:
- Implementar objeto de cadena (StringObject);
- Se utiliza como sustituto del tipo char * en el programa Redis;
Ventajas de 1.1sds
En lenguaje C, una cadena de caracteres se puede representar mediante una matriz de caracteres que termina en \ 0.
Por ejemplo, hola mundo se puede expresar como "hola mundo \ 0" en lenguaje C.
Esta representación de cadena simple puede cumplir con los requisitos en la mayoría de los casos, pero no puede soportar de manera eficiente las
dos operaciones de cálculo de longitud y anexar:
- La complejidad de calcular la longitud de la cuerda (strlen (s)) cada vez es θ (N).
- Para que N se anexe a una cadena, se deben realizar N reasignaciones en la cadena.
En Redis, la adición de cadenas y el cálculo de la longitud no son infrecuentes, y APPEND y STRLEN
son el mapeo directo de estas dos operaciones en los comandos de Redis. Estas dos operaciones simples no deberían convertirse en un cuello de botella de rendimiento.
Además, además de procesar cadenas C, Redis también necesita lidiar con matrices de bytes simples, protocolos de servidor y otro contenido,
por lo que , para mayor comodidad, la representación de cadenas de Redis también debe ser segura para los binarios: los programas no deben almacenarse en cadenas
. Los datos pueden ser una cadena C terminada en \ 0, una matriz de bytes simple o
datos en otros formatos.
Teniendo en cuenta estas dos razones, Redis usa el tipo sds para reemplazar la representación de cadena predeterminada del lenguaje C: sds puede
implementar de manera eficiente el cálculo de anexos y longitudes, y también es binario seguro.
1.2 Implementación de sds
En el contenido anterior hemos estado describiendo sds como una estructura de datos abstracta, de hecho, su implementación consta de las siguientes dos
partes:
typedef char *sds;
struct sdshdr {
// buf 已占用长度
int len;
// buf 剩余可用长度
int free;
// 实际保存字符串数据的地方
char buf[];
};
Entre ellos, el tipo sds es el alias de char *, y la estructura sdshdr guarda los tres
atributos de len, free y buf .
A modo de ejemplo, lo siguiente es una estructura sdshdr recién creada que también contiene la cadena hello world:
struct sdshdr {
len = 11;
free = 0;
buf = "hello world\0"; // buf 的实际长度为 len + 1
};
A través del atributo len, sdshdr puede implementar operaciones de cálculo de longitud con una complejidad de θ (1).
Por otro lado, al asignar algo de espacio extra para buf, dimensionar y usar el registro libre de espacio no utilizado, sdshdr puede
hacer que la memoria adicional requerida para realizar la reasignación del número de operaciones se reduzca en gran medida, la siguiente sección lo haremos discuta esto en detalle un poco.
Por supuesto, sds también presenta requisitos para la implementación correcta de la operación: todas las funciones relacionadas con sdshdr deben actualizar correctamente los
atributos len y free, de lo contrario, se producirán errores.
La base de datos de Redis se usa a menudo para ocasiones con requisitos estrictos de velocidad y modificación frecuente de datos. Si es necesario realizar una asignación de memoria cada vez que se modifica la longitud de una cadena, entonces el tiempo para realizar la asignación de memoria solo tomará el tiempo para la modificación de la cadena Una gran parte, si es así, puede tener un impacto en el rendimiento.
Para evitar este defecto de las cadenas C, SDS utiliza el espacio no utilizado para disociar la longitud de la cadena de la capa inferior. En SDS, la longitud de la matriz buf debe ser el número de cadenas más uno, y la matriz puede contener Bytes, el número de estos bytes es el registro de los atributos en libre en la SDS.
Nota: Cuando el espacio asignado es insuficiente, modifique len para que sea menor que 1Mb, el
espacio libre igual al Len siempre se duplica, len es mayor que 1mb, libre equivale a 1MB.
Ejemplo: después de la modificación, la longitud de SDS se convertirá en 13 bytes, luego el programa también asignará 13 bytes de espacio no utilizado, la longitud real de la matriz sds será 13 + 13 + 1 = 27 bytes
Si la longitud de SDS se modifica para que sea mayor o igual a 1 MB, tomando como ejemplo 30 MB, la longitud real de la matriz sds será 30 MB + 1 MB + 1byte.
En este punto, debe prestar atención a los comandos en String
APPEND key value
如果 key 已经存在并且是一个字符串, APPEND 命令将 value 追加到 key 原来的值的末尾。
如果 key 不存在, APPEND 就简单地将给定 key 设为 value ,就像执行 SET key value 一样。
Si se realizan operaciones de expansión de cadenas frecuentes y a gran escala, preste atención a la situación de la memoria del servidor Redis
Esta idea es utilizar el espacio a cambio de tiempo, y prestar atención al tiempo y al espacio al analizar problemas en línea.
A través de esta estrategia de preasignación , SDS reduce la cantidad de asignaciones de memoria necesarias para el crecimiento continuo N veces desde un cierto N veces hasta un máximo de N veces
Análisis de código:
Versión de código 6.0.8
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {sdshdr
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
Puede ver que la capacidad se ha duplicado y el comentario explica que nunca se usa sdshdr5.
- len: la longitud de la cadena (la longitud realmente utilizada)
- alloc: el tamaño de la memoria asignada
- banderas: bits de bandera, los tres bits inferiores indican el tipo y los cinco bits restantes no se utilizan
- buf: matriz de caracteres
1.3 Liberación de espacio inerte
La liberación de espacio diferido se usa para optimizar la operación de acortamiento de cadenas de SDS: cuando la API de SDS necesita acortar la cadena guardada por SDS, el programa no usa inmediatamente la reasignación de memoria para recuperar los bytes acortados, sino que usa el atributo libre para guardarlos. cadenas. El número de bytes se registra y se espera para su uso futuro.
SDS proporciona las API correspondientes, lo que nos permite liberar realmente el espacio no utilizado de SDS cuando sea necesario.
1.4 Seguridad binaria
Los caracteres de la cadena C deben ajustarse a una determinada codificación y, aparte del final de la cadena, la cadena no puede contener una cadena vacía; de lo contrario, la cadena vacía que lea el programa primero se confundirá con el final de la cadena, y Solo C Puede guardar datos de texto. No puede guardar datos binarios como imágenes, audios, videos y archivos comprimidos.
Las API de SDS son binarias seguras binzry-safe
, todas las API de SDS procesarán los datos en la matriz de búfer de SDS de forma binaria
1.5 Compatible con algunas funciones de cadena C
Dos, codificación interna de Redis
Para los cinco tipos de datos de Redis de uso común (cadena, hash, lista, conjunto, conjunto ordenado), cada tipo de datos proporciona al menos dos formatos de codificación interna, y la elección de la codificación interna para cada tipo de datos es completamente para los usuarios. Transparente, Redis lo hará. seleccione de forma adaptativa un formato de codificación interno más optimizado de acuerdo con la cantidad de datos.
Si desea ver el formato de codificación interno de una clave, puede utilizar el comando de nombre de clave OBJECT ENCODING, como por ejemplo:
127.0.0.1:6379>
127.0.0.1:6379> set foo bar
OK
127.0.0.1:6379>
127.0.0.1:6379> object encoding foo // 查看某个Redis键值的编码
"embstr"
127.0.0.1:6379>
127.0.0.1:6379>
Cada valor clave de Redis se almacena internamente utilizando una estructura de lenguaje C llamada redisObject. El código es el siguiente:
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
La explicación es la siguiente:
- tipo: indica el tipo de datos del valor de la clave, incluidos String, List, Set, ZSet, Hash
- codificación: representa el método de codificación interno del valor de la clave. A partir del código fuente de Redis, los valores actuales son los siguientes:
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
#define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
refcount: indica el número de referencias a la clave, es decir, una clave puede ser referenciada por múltiples claves
Formato de codificación INT
Ejemplo de comando: set foo 123
Cuando el contenido del valor de la clave de cadena se puede representar mediante un entero de 64 bits con signo, Redis convertirá el valor de la clave en un tipo largo para almacenamiento, que corresponde al tipo de codificación OBJ_ENCODING_INT.
La estructura de la memoria interna del tipo de codificación OBJ_ENCODING_INT se puede expresar visualmente de la siguiente manera:
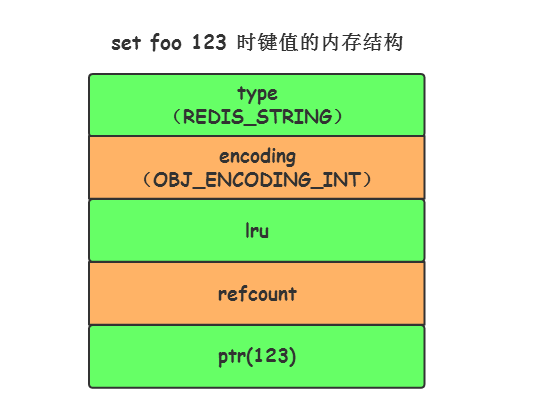
La estructura de memoria del valor de la clave cuando se establece foo 123 está configurada y cuando se
inicia Redis, creará previamente 10000 variables de redisObject almacenando 0 ~ 9999 como objetos compartidos. Esto significa que si el valor de la clave de la cadena establecida está entre 0 ~ 10000 , a continuación, puede apuntar directamente al objeto compartido sin crear un nuevo objeto. En este momento, el valor clave no ocupa espacio.
Por tanto, cuando se ejecutan las siguientes instrucciones:
set key1 100
set key2 100
De hecho, los dos valores clave de key1 y key2 se refieren directamente a un objeto redisObject compartido que Redis ha creado de antemano, como el siguiente: Antes del código fuente del
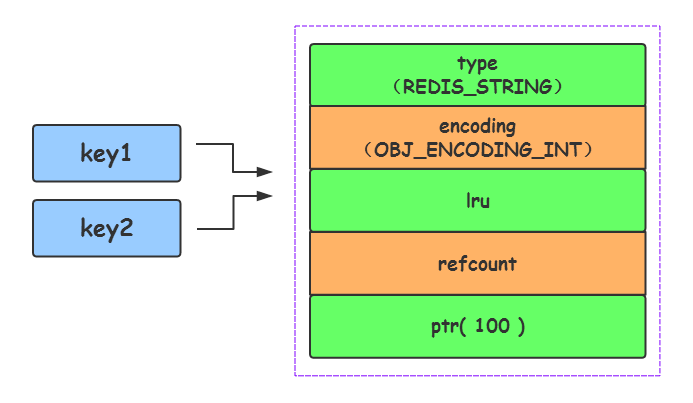
objeto compartido
, no hay ningún secreto, comparemos el código fuente a continuación con comprender el proceso anterior
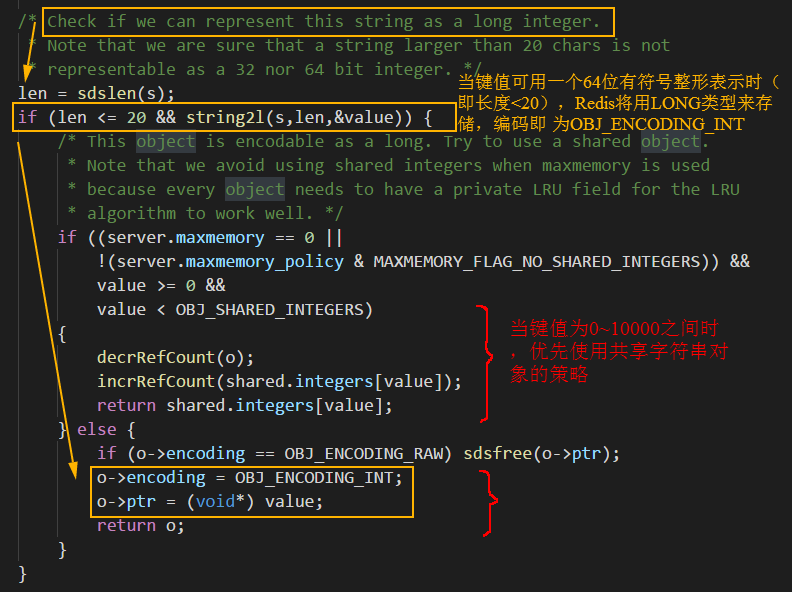
código fuente codificado INT
Formato de codificación EMBSTR
Ejemplo de comando: set foo abc
Redis utilizará el método de codificación OBJ_ENCODING_EMBSTR al guardar cadenas con una longitud de menos de 44 bytes. No hay pruebas, echemos un vistazo al código fuente:
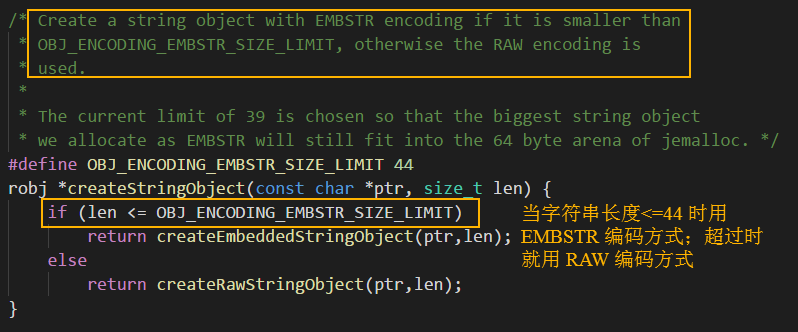
la condición de juicio de la codificación EMBSTR
es fácil de ver en el código anterior. Para cadenas con una longitud menor que 44, Redis adopta el método OBJ_ENCODING_EMBSTR para el valor de la clave. EMBSTR, como su nombre lo indica, es: cadena incrustada, que significa cadena incrustada. En términos de estructura de memoria, la estructura de cadena sds y su objeto redisObject correspondiente se asignan en el mismo espacio de memoria continuo, que es como si la cadena sds estuviera incrustada en el objeto redisObject, todo lo cual se puede ver claramente en el siguiente código Para :
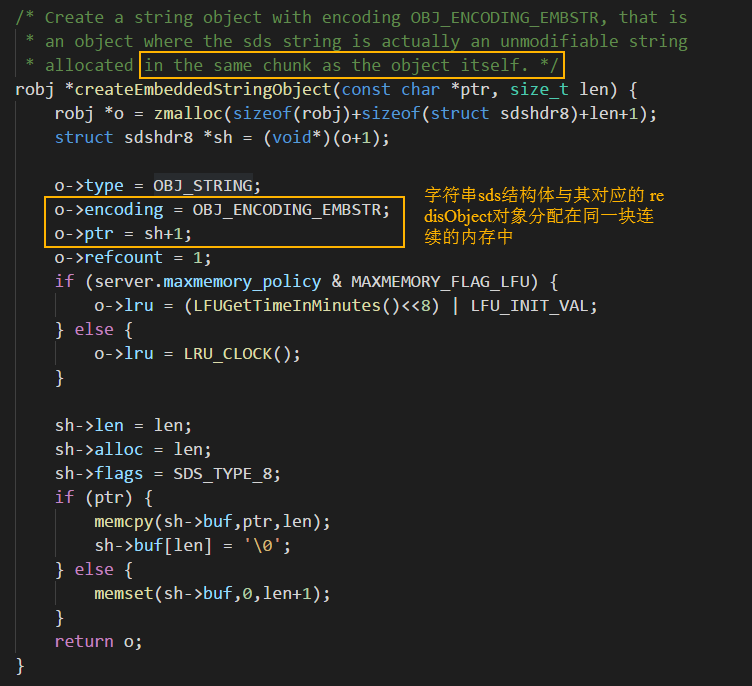
cadena incrustada
Por lo tanto, para el valor clave establecido por el conjunto de instrucciones foo abc, el diagrama de la estructura de la memoria es el siguiente:
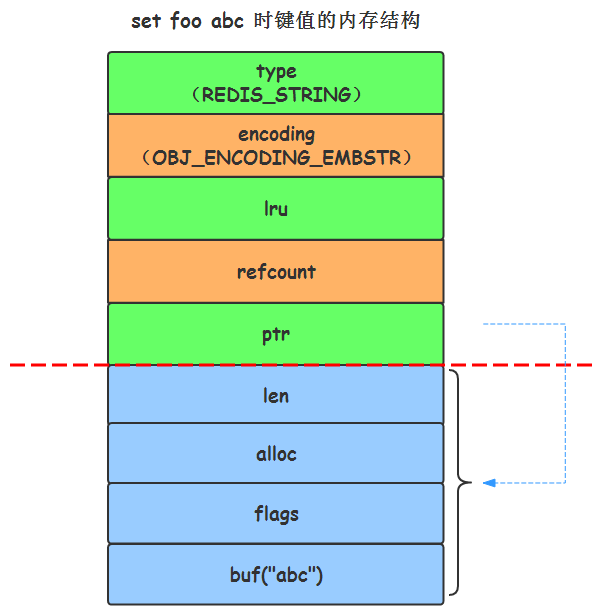
La estructura de la memoria del valor clave cuando se establece foo abc
Formato de codificación RAW
Instrucción de ejemplo: set foo abcdefghijklmnopqrstuvwxyzabcdeffasdffsdaadsx
Al igual que en el ejemplo de instrucción, cuando el valor clave de la cadena es una cadena muy larga con una longitud superior a 44, Redis cambiará la codificación interna del valor clave al formato OBJ_ENCODING_RAW, que es diferente del método de codificación OBJ_ENCODING_EMBSTR anterior en esta vez sus sds secuencia en la memoria dinámica redisObject memoria dependiente ya no es un proceso continuo, con el fin de conjunto foo abcdefghijklmnopqrstuvwxyzabcdeffasdffsdaadsx ejemplo, la estructura de memoria clave se muestra a continuación:
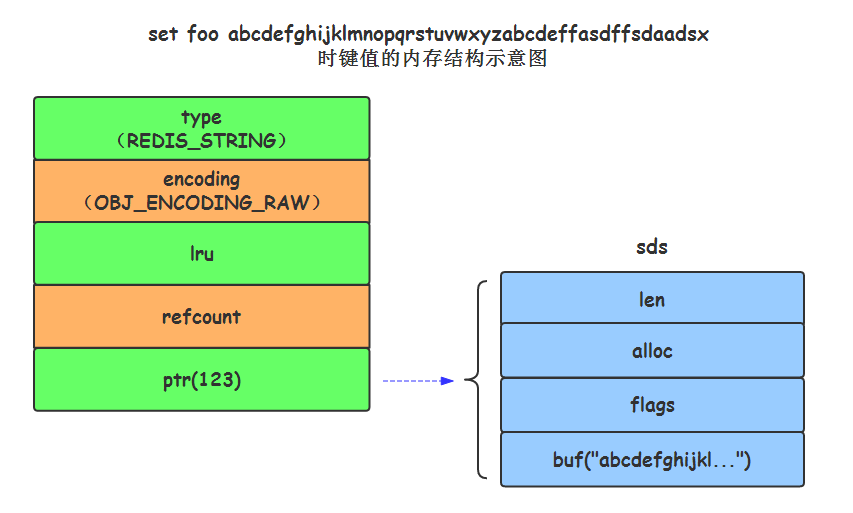
foo clave-set abcdefghijklmnopqrstuvwxyzabcdeffasdffsdaadsx estructuras de memoria cuando
esto sería terminado básica ¿Qué hay de la codificación interna de el tipo de datos String? ¡Es bastante fácil de entender!
Posteriormente, continuaremos analizando el formato de codificación interno del tipo de datos Hash en Redis.
Materiales de referencia: https://www.jianshu.com/p/666452a22855
Tres, lista enlazada
La lista enlazada, como una abstracción de secuencia común distinta de la matriz, es el tipo de datos básico de la mayoría de los lenguajes de alto nivel. Debido a que el lenguaje C en sí
no admite el tipo de lista enlazada, la mayoría de los programas C implementarán un tipo de lista enlazada por sí mismos. Redis no es excepción-it Se realiza
una estructura de lista enlazada de dos extremos.
/* Node, List, and Iterator are the only data structures used currently. */
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
typedef struct listIter {
listNode *next;
int direction;
} listIter;
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
Lenguaje C en la escuela, el código fuente de redis no se puede depurar temporalmente
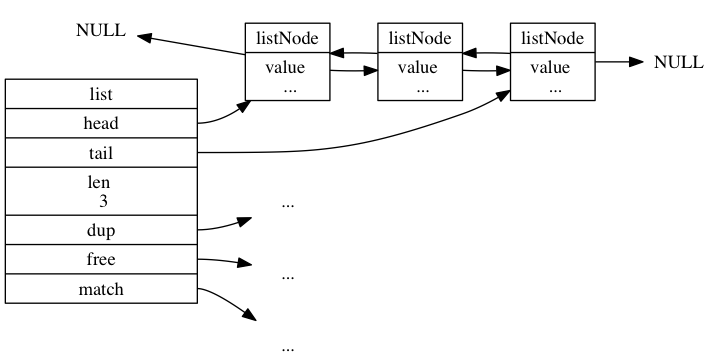
- Como una de las implementaciones subyacentes de la clave de lista: cuando una clave de lista contiene una gran cantidad de elementos, o los elementos contenidos en la lista son cadenas relativamente largas, Redis utilizará la lista vinculada como la implementación subyacente de la clave de lista.
- Además, funciones como publicar y suscribirse, consulta lenta y supervisar también usan listas vinculadas. El servidor de Redis también usa listas vinculadas para almacenar la información de estado de varios clientes y usa listas vinculadas para crear búferes de salida de clientes.
-
La lista doblemente enlazada
se puede ver en la estructura de listNode, incluyendo el punto directo y el nodo post. Por lo tanto, el desplazamiento hacia adelante y hacia atrás se puede realizar de manera muy conveniente. -
El
puntero anterior de los nodos de encabezado de la lista acíclica y la tabla del puntero de cola el siguiente nodo apunta a nulo, es una lista de la cadena acíclica de Redis. -
Con punteros de cabeza y cola
En la estructura de la lista, se guardan los punteros de cabeza y cola de la lista enlazada actual, por lo que se puede recorrer rápidamente desde el principio o desde el final. -
La longitud de
la lista enlazada actual se almacena en la estructura de la lista con un contador de longitud , por lo que la complejidad temporal estadística de la longitud de la lista enlazada es O (1).
Cuarto, el diccionario
Diccionario (Diccionario), también conocido mapa (Mapa) o matriz asociativa (matriz asociativa), que es una estructura de datos abstracta
configurada por una composición de pares clave-valor (pares clave-valor), cada clave de cada clave no es similar, el programa puede agregar nuevos pares clave-valor
al diccionario o realizar operaciones como buscar, actualizar o eliminar según la clave.
El lenguaje C no tiene este tipo de estructura de datos incorporada, Redis implementa su propio diccionario.
Los principales propósitos del diccionario son los siguientes:
- Darse cuenta del espacio clave de la base de datos (espacio clave);
- Se utiliza como una de las implementaciones subyacentes de claves de tipo Hash;
4.1 darse cuenta del espacio clave del espacio clave de la base de datos
Redis es una base de datos de pares clave-valor. Los pares clave-valor de la base de datos se almacenan en un diccionario: cada base de datos tiene un
diccionario correspondiente , y este diccionario se denomina espacio clave.
Cuando un usuario agrega un par clave-valor a la base de datos (independientemente del tipo de pares clave-valor), el programa agregará los pares clave-valor para generar una clave en una
habitación vacía ; cuando un usuario elimina un par clave de la base de datos, este programa eliminará el par clave-valor del espacio de claves; etc.
Por ejemplo, la ejecución de FLUSHDB puede borrar todos los datos de pares clave-valor en el espacio clave:
redis> FLUSHDB
OK
La ejecución de DBSIZE devuelve los pares clave-valor existentes en el espacio clave:
redis> DBSIZE
(integer) 0
También puede usar SET para establecer una clave de cadena en el espacio de clave y usar GET para obtener el valor de la clave de cadena del espacio de clave:
redis> SET number 10086
OK
redis> GET number
"10086"
redis> DBSIZE
(integer) 1
4.2 Una de las implementaciones subyacentes utilizadas como claves de tipo Hash
La clave de tipo Hash de Redis utiliza las siguientes dos estructuras de datos como implementación subyacente:
- diccionario;
- Lista comprimida
Debido a que la lista comprimida ahorra más memoria que el diccionario, el programa usa la lista comprimida como la
implementación subyacente de forma predeterminada al crear una nueva clave Hash . Cuando sea necesario, el programa convertirá la implementación subyacente de la lista comprimida al diccionario.
Cuando el usuario manipula una clave Hash, el valor de la clave puede ser una tabla hash en la parte inferior:
redis> HSET book name "The design and implementation of Redis"
(integer) 1
redis> HSET book type "source code analysis"
(integer) 1
redis> HSET book release-date "2013.3.8"
(integer) 1
redis> HGETALL book
1) "name"
2) "The design and implementation of Redis"
3) "type"
4) "source code analysis"
5) "release-date"
6) "2013.3.8"
El capítulo "Tabla hash" ofrece más información sobre las claves de tipo hash e introduce las condiciones de conversión entre listas comprimidas y diccionarios.
Habiendo introducido el propósito del diccionario, veamos ahora la definición de la estructura de datos del diccionario.
4.3 Definición de diccionario
Implementación de diccionario
Hay muchas formas de implementar un diccionario:
- • La forma más sencilla es utilizar una lista enlazada o una matriz, pero este método solo es adecuado cuando el número de elementos es pequeño.
• Para equilibrar la eficiencia y la simplicidad, puede utilizar una tabla hash;
• Si busca características de rendimiento más estables. Y si desea implementar eficientemente la operación de clasificación, puede usar un
árbol balanceado más complejo ;
entre muchas implementaciones posibles, Redis ha elegido una tabla hash eficiente y simple como la implementación subyacente del diccionario.
dict.h / dict da la definición de este diccionario
/*
*字典
*/
typedef struct dict {
dictType *type;
void *privdata;
//hash表个数
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
El atributo ht es una matriz que contiene dos elementos. Cada elemento de la matriz es una
tabla hash dictht . Generalmente, el diccionario solo usa la tabla hash ht [0], y la tabla hash ht [1] solo está en la tabla ht [0] ] La tabla hash se usa cuando se repite.
rehashidx registra el progreso del refrito, si no se hace, el valor es -1
Implementación de tabla hash
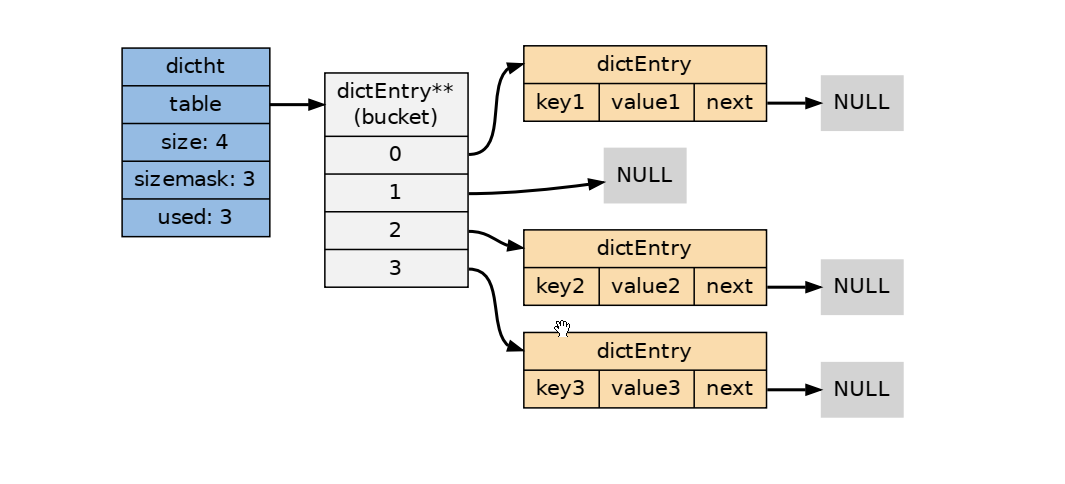
La implementación de la tabla hash utilizada por el diccionario está definida por el tipo dict.h / dictht:
/*
* 哈希表
*/
typedef struct dictht {
// 哈希表节点指针数组(俗称桶, bucket)
dictEntry **table;
// 指针数组的大小
unsigned long size;
// 指针数组的长度掩码,用于计算索引值
unsigned long sizemask;
// 哈希表现有的节点数量
unsigned long used;
} dictht;
El atributo de la tabla es una matriz y cada elemento de la matriz es un puntero a la estructura dictEntry.
Cada dictEntry contiene un par clave-valor y un puntero a otra estructura dictEntry:
/*
*哈希节点
*/
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
[Error en la transferencia de la imagen del enlace externo. Es posible que el sitio de origen tenga un mecanismo de enlace anti-sanguijuela. Se recomienda guardar la imagen y subirla directamente (img-e6II8y7a-1601172888918) (https://i.imgrpost.com/imgr/ 2020/09/26 / FoxitReader_VIM1v3M0Nt .png)]
4.4 algoritmo hash
Actualmente, Redis usa dos algoritmos hash diferentes:
- Algoritmo MurmurHash2 de 32 bits: la tasa de distribución y la velocidad de este algoritmo son muy buenas. Para obtener información específica, consulte la página de inicio de MurmurHash: http://code.google.com/p/smhasher/.
- Un algoritmo hash independiente de mayúsculas y minúsculas basado en el algoritmo djb: consulte la información específica
Este método se implementa en dictGenHashFunction
unsigned int dictGenHashFunction(const void *key, int len) { //用于计算字符串的哈希值的哈希函数
/* 'm' and 'r' are mixing constants generated offline.
They're not really 'magic', they just happen to work well. */
//m和r这两个值用于计算哈希值,只是因为效果好。
uint32_t seed = dict_hash_function_seed;
const uint32_t m = 0x5bd1e995;
const int r = 24;
/* Initialize the hash to a 'random' value */
uint32_t h = seed ^ len; //初始化
/* Mix 4 bytes at a time into the hash */
const unsigned char *data = (const unsigned char *)key;
//将字符串key每四个一组看成uint32_t类型,进行运算的到h
while(len >= 4) {
uint32_t k = *(uint32_t*)data;
k *= m;
k ^= k >> r;
k *= m;
h *= m;
h ^= k;
data += 4;
len -= 4;
}
/* Handle the last few bytes of the input array */
switch(len) {
case 3: h ^= data[2] << 16;
case 2: h ^= data[1] << 8;
case 1: h ^= data[0]; h *= m;
};
/* Do a few final mixes of the hash to ensure the last few
* bytes are well-incorporated. */
h ^= h >> 13;
h *= m;
h ^= h >> 15;
return (unsigned int)h;
}
http://www.cse.yorku.ca/~oz/hash.html.
El algoritmo que se utilice depende de los datos procesados por la aplicación específica:
• El algoritmo 2 se utiliza tanto en la tabla de comandos como en la caché de scripts de Lua.
• El algoritmo 1 se usa más ampliamente: funciones como bases de datos, clústeres, claves hash y operaciones de bloqueo utilizan este algoritmo.
En la implementación de la tabla hash, cuando dos claves diferentes tienen el mismo valor hash, llamamos colisión a las dos claves,
y la implementación de la tabla hash debe encontrar una manera de lidiar con la colisión.
El método de resolución de colisiones utilizado por la tabla hash del diccionario se denomina método de dirección en cadena: este método utiliza una lista enlazada para conectar varios
nodos con el mismo valor hash en serie para resolver el problema del conflicto.
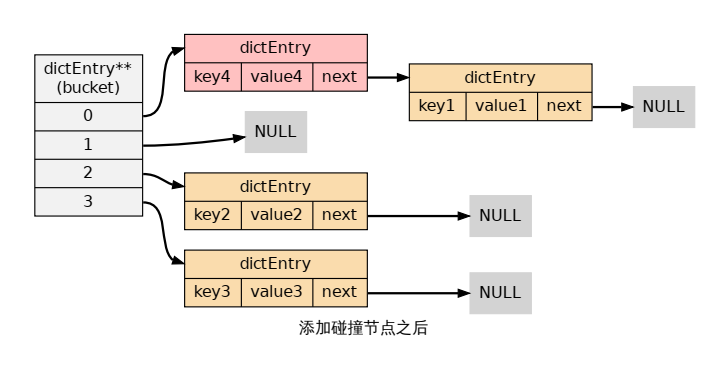
Teniendo en cuenta la velocidad, el nodo siempre se agrega a la posición de la cabeza de la lista vinculada, y la complejidad es O (1)
Aquí puede comparar el hashMap de Java y comparar la memoria.
4.5 refrito
Cuando el tamaño de la tabla hash no puede satisfacer la demanda, puede haber dos o más claves asignadas al mismo índice en la matriz de la tabla hash, por lo que se produce una colisión.
La forma de resolver conflictos en Redis es el encadenamiento por separado. Sin embargo, los conflictos deben evitarse tanto como sea posible, y si el factor de carga de la tabla hash se mantiene dentro de un rango razonable, la tabla hash debe expandirse o contraerse.
Expansión: cuando el número de elementos de la tabla hash es igual a la longitud de la matriz de primera dimensión, comenzará la expansión. La nueva matriz expandida tiene el doble del tamaño de la matriz original. Pero si Redis está haciendo bgsave, para reducir la separación excesiva de las páginas de memoria (Copy On Write), Redis intenta no expandirse (dict_can_resize), pero si la tabla hash ya está muy llena, el número de elementos ha llegado al primero -matriz dimensional La longitud es 5 veces (dict_force_resize_ratio), lo que indica que la tabla hash ya está demasiado llena y, en este momento, se verá obligada a expandirse.
Contracción: cuando la tabla hash se vuelve más dispersa debido a la eliminación gradual de elementos, Redis encogerá la tabla hash para reducir el espacio ocupado por la matriz de primera dimensión de la tabla hash. La condición para la reducción es que el número de elementos sea inferior al 10% de la longitud de la matriz. La escala no tiene en cuenta si Redis está haciendo bgsave.
La expansión de un diccionario grande requiere mucho tiempo. Es necesario volver a solicitar una nueva matriz y luego volver a adjuntar todos los elementos de la lista vinculada del diccionario antiguo a la nueva matriz. Esta es una operación de nivel O (n).
Código de expansión:
static int _dictExpandIfNeeded(dict *d) //扩展d字典,并初始化
{
if (dictIsRehashing(d)) return DICT_OK; //正在进行rehash,直接返回
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE); //如果字典(的 0 号哈希表)为空,那么创建并返回初始化大小的 0 号哈希表
//1. 字典的总元素个数和字典的数组大小之间的比率接近 1:1
//2. 能够扩展的标志为真
//3. 已使用节点数和字典大小之间的比率超过 dict_force_resize_ratio
if (d->ht[0].used >= d->ht[0].size && (dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2); //扩展为节点个数的2倍
}
return DICT_OK;
}
Reducir el código:
int dictResize(dict *d) //缩小字典d
{
int minimal;
//如果dict_can_resize被设置成0,表示不能进行rehash,或正在进行rehash,返回出错标志DICT_ERR
if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;
minimal = d->ht[0].used; //获得已经有的节点数量作为最小限度minimal
if (minimal < DICT_HT_INITIAL_SIZE)//但是minimal不能小于最低值DICT_HT_INITIAL_SIZE(4)
minimal = DICT_HT_INITIAL_SIZE;
return dictExpand(d, minimal); //用minimal调整字典d的大小
}
Enlace de referencia: https://www.jianshu.com/p/7f53f5e683cf
Pasos detallados de refrito progresivo :
-
Asigne espacio para ht [1], deje que el diccionario contenga dos tablas hash ht [0] y ht [1] al mismo tiempo
-
Mantenga una variable de contador de índice rehashidx en el diccionario y establezca su valor en 0, lo que marca el inicio oficial del trabajo de refrito.
-
Durante el refrito, cada vez que se agrega, borra, busca o actualiza el diccionario, además de realizar la operación especificada, el programa también repetirá todos los pares clave-valor de la tabla hash ht [0] en el índice rehashidx a ht [ 1], cuando se complete el trabajo de refrito, aumente el valor del atributo rehashidx en uno.
-
Con la ejecución continua de la operación del diccionario, finalmente en un momento determinado, todos los pares clave-valor de ht [0] se volverán a convertir en ht [1], luego el programa establecerá el valor del árbol de rehashidx en -1, lo que significa refrito La operación se ha completado.
La ventaja del refrito progresivo es divide y vencerás. El trabajo de cálculo requerido para el valor de la clave de refrito se asigna a cada operación de adición, eliminación, búsqueda y actualización del diccionario, evitando así la enorme cantidad de cálculos causados por el refrito centralizado.
Durante el refrito progresivo, use ht [0] y ht [1] dos tablas hash, primero busque ht [0], luego busque ht [1]
Agregado recientemente al diccionario de pares clave-valor, se guardará en ht [1]
dentro
Este artículo prohíbe cualquier forma de reimpresión y el contenido se refiere al "Diseño e implementación de Redis".
Si hay algún error en la versión 6.0.8 de Redis en el artículo, comuníquese.