1. Introducción
Redis es una base de datos KV no relacional basada en la memoria. Debido a la rápida respuesta de lectura y escritura, operaciones atómicas y varios tipos de datos String, List, Hash, Set, Sorted Set, que se usan ampliamente en proyectos, hoy analizaremos cómo se implementa la estructura de datos de Redis.
2 almacenamiento de datos
2.1 Redis DB
Redis almacena datos en redisDb, con un total de 16 dbs de 0 a 15 por defecto. Cada biblioteca es un espacio independiente, por lo que no tiene que preocuparse por los conflictos de teclas. Puede cambiar db a través del comando de selección. El modo de clúster utiliza db0
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
...
} redisDb;- dict: espacio clave de la base de datos, guarda todos los pares clave-valor en la base de datos
- expira: el tiempo de vencimiento de la clave, la clave del diccionario es la clave y el valor del diccionario es la marca de tiempo UNIX del evento de vencimiento
2.2 Implementación de la tabla hash de Redis
2.2.1 Dict de diccionario hash
Lo primero que pensamos para el almacenamiento de KV es map, que se implementa en Redis a través de dict. La estructura de datos es la siguiente:
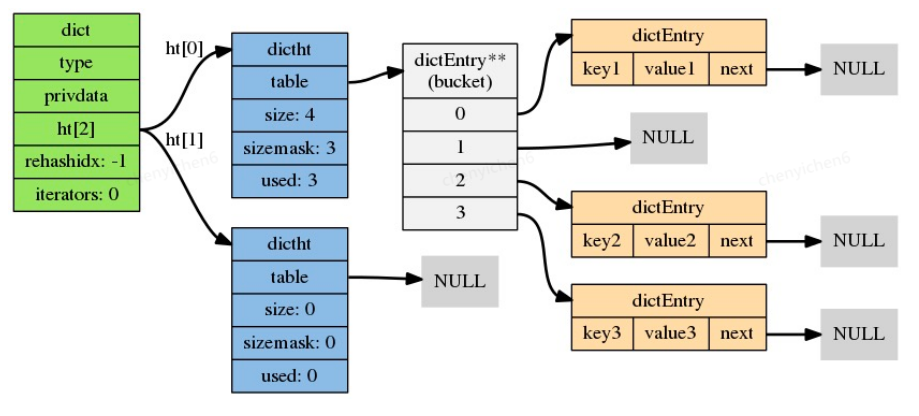
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;- type: la función específica de tipo es un puntero a una estructura dictType. Cada estructura dictType almacena un conjunto de funciones para manipular pares clave-valor de un tipo específico. Redis establecerá diferentes funciones específicas de tipo para diccionarios con diferentes propósitos.
- privdata: los datos privados contienen parámetros opcionales que deben pasarse a esas funciones específicas del tipo
- ht[2]: tabla hash Una matriz que contiene dos elementos, cada elemento de la matriz es una tabla hash dictht, en general, el diccionario solo usa la tabla hash ht[0], ht[1] ha La tabla hash solo será se usa cuando se repite la tabla hash ht[0]
- rehashidx: índice de repetición, cuando la repetición no está en progreso, el valor es -1
Hay dos características de los datos hash:
- Cualquier entrada idéntica debe producir los mismos datos.
- Diferentes entradas, es posible obtener la misma salida
De acuerdo con las características de los datos hash, existe un problema de colisión hash, dict puede resolver este problema a través de la función en dictType
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
...
} dictType;- hashFunction: el método utilizado para calcular el valor hash de la clave
- keyCompare: método de comparación de valores clave
2.2.2 Dicttht de tabla hash
dict.h/dicttht representa una tabla hash con la siguiente estructura:
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;- table: puntero de matriz, cada elemento de la matriz es un puntero a una estructura dict.h/dictEntry, y cada estructura dictEntry contiene un par clave-valor.
- tamaño: registra el tamaño de la tabla hash, es decir, el tamaño del arreglo de la tabla, el tamaño siempre es 2^n
- máscara de tamaño: siempre igual a tamaño - 1, esta propiedad, junto con el valor hash, determina en qué índice de la matriz de la tabla debe colocarse una clave.
- used: registra el número de nodos existentes (pares clave-valor) en la tabla hash.
par clave-valor dict.h/dictEntry
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;- clave: contiene la clave en el par clave-valor (objeto de tipo SDS)
- val: contiene el valor en el par clave-valor, que puede ser un entero uint64_t, un entero int64_t o un puntero a un valor envuelto por redisObject
- siguiente: apunta al siguiente nodo de la tabla hash, formando un puntero a otro nodo de la tabla hash en la lista vinculada. Este puntero puede conectar varios pares clave-valor con el mismo valor hash a la vez, para resolver el problema de la colisión de claves (colisión) pregunta
Al usar una tabla hash, habrá un problema de colisión hash. Después de la colisión hash, se forma una lista enlazada en el nodo de matriz actual. Cuando la cantidad de datos exceda la longitud de la tabla hash, habrá un gran número de nodos llamados listas enlazadas. En casos extremos, la complejidad del tiempo será de O(1) a O(n); si los datos en la tabla hash continúan disminuyendo, causará una pérdida de espacio. Redis se expandirá y contraerá según el factor de carga para estas dos situaciones:
- Factor de carga: número de nodos guardados en la tabla hash/tamaño de la tabla hash, load_factor = ht[0].used/ht[0].size
- Operación extendida:
- El servidor no está ejecutando actualmente el comando BGSAVE o el comando BGREWRITEAOF, y el factor de carga de la tabla hash es mayor o igual a 1;
- El servidor está ejecutando actualmente el comando BGSAVE o el comando BGREWRITEAOF, y el factor de carga de la tabla hash es mayor o igual a 5;
Operación de contracción:
- Cuando el factor de carga de la tabla hash es inferior a 0,1, el programa automáticamente comienza a reducir la tabla hash.
Si Redis se expande por completo durante la expansión, la operación del cliente no se puede procesar en poco tiempo debido al problema del volumen de datos. Por lo tanto, se utiliza una repetición incremental para expandir la capacidad. Los pasos son los siguientes:
- Sostiene 2 tablas hash al mismo tiempo
- Establezca el valor de rehashidx en 0, lo que significa que el trabajo de repetición comienza oficialmente
- Durante la repetición, cada vez que se agrega, elimina, busca o actualiza el diccionario, el programa no solo realizará las operaciones especificadas, sino que también repetirá todos los pares clave-valor en el índice rehashidx de la tabla hash ht[0] al rehash.ht[1] , cuando se completa el trabajo de repetición, el programa incrementa el valor del atributo rehashidx en uno
- En un momento determinado, todos los pares clave-valor de ht[0] se repetirán en ht[1]. En ese momento, el programa establece el valor del atributo rehashidx en -1, lo que indica que la operación de repetición se ha realizado. terminado.
Durante el refrito progresivo, las operaciones como eliminar, buscar, actualizar, etc. del diccionario se realizarán en dos tablas hash; si se busca una clave en el diccionario, el programa primero realizará operaciones en ht[0] para buscar, si no se encuentra, continuará buscando en ht[1]; los pares clave-valor recién agregados al diccionario se guardarán en ht[1], y ht[0] no se buscará más Cualquier operación adicional: Esta La medida asegura que el número de pares clave-valor contenidos en ht[0] solo disminuirá y no aumentará (si no se realiza ninguna operación durante mucho tiempo, el sondeo de eventos realizará esta operación), y se actualizará con la ejecución de la operación de refrito Eventualmente se convierte en una mesa vacía.
dict.h/redisObjeto
Typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS;
int refcount;
void *ptr;
}- type: 4: restringe el tipo de datos almacenados en las operaciones del cliente, los datos existentes no se pueden modificar, 4 bits
- codificación: 4: el modo de codificación del valor en la parte inferior de redis, 4 bits
- lru:LRU_BITS: estrategia de eliminación de memoria
- refcount: Administrar la memoria por método de conteo de referencia, 4 bytes
- ptr: la dirección que apunta al valor de almacenamiento real, 8 bytes
El esquema completo de la estructura es el siguiente:
Tipo de 3 cuerdas
3.1 Escenarios de uso de tipo de cadena
Cadena Las cadenas existen en tres tipos: cadena, entero, flotante. Existen principalmente los siguientes escenarios de uso
1) Caché dinámico de página Por
ejemplo, cuando se genera una página dinámica, los datos de fondo se pueden generar por primera vez y almacenar en la cadena redis. Acceda nuevamente, no más solicitudes de base de datos, y lea la página directamente desde redis. Las características son: el primer acceso es relativamente lento y el acceso posterior es rápido.
2) Caché de datos
En la parte delantera y trasera del desarrollo separados, aunque algunos datos se almacenan en la base de datos, los cambios son muy pequeños. Por ejemplo, hay una mesa nacional. Cuando el front-end inicia una solicitud, si el back-end lee la base de datos relacional cada vez, afectará el rendimiento general del sitio web.
Podemos almacenar toda la información de la región en la cadena redis en la primera visita, solicitar nuevamente, leer la cadena json de la región directamente desde la base de datos y devolverla al front-end.
3) Las estadísticas de datos Los
números enteros de Redis se pueden usar para registrar las visitas al sitio web y las descargas de un determinado archivo. (incrementos y decrementos atómicos)
4) Limite el número de solicitudes dentro de un tiempo.
Por ejemplo, un usuario registrado solicita un código de verificación por SMS y el código de verificación es válido dentro de los 5 minutos. Cuando el usuario solicita la interfaz de SMS por primera vez, la identificación del usuario se almacena en la cadena que redis ha enviado el SMS y el tiempo de vencimiento se establece en 5 minutos. Cuando el usuario vuelve a solicitar la interfaz de mensajes cortos y descubre que ya existe un registro del usuario enviando mensajes cortos, el mensaje corto no se volverá a enviar.
5) Sesión distribuida
Cuando usamos nginx para equilibrar la carga, si cada uno almacena su propia sesión del servidor, cuando se cambia el servidor, la información de la sesión se perderá porque no se comparte, tenemos que considerar La tercera aplicación es utilizado para almacenar la sesión. A través de nuestro uso de bases de datos relacionales o bases de datos no relacionales como redis. El rendimiento de almacenamiento y lectura de las bases de datos relacionales está lejos del de las bases de datos no relacionales como redis.
3.2 Implementación del tipo String - estructura SDS
Redis no usa cadenas C directamente para implementar el tipo String, sino que se implementó a través de SDS antes de Redis 3.2.
Typedef struct sdshdr {
int len;
int free;
char buf[];
};- len: asignar espacio de memoria
- libre: el espacio asignado gratuito restante
- char[]: valor datos reales
3.3 Diferencias entre cadenas SDS y C
3.3.1 Complejidad del tiempo de consulta
La complejidad de C para obtener la longitud de una cadena es O(N). Y SDS registra la longitud por len, cambiando de O(n) de C a O(1).
3.3.2 Desbordamiento de búfer
Las cadenas C no registran su propia longitud, lo que puede provocar fácilmente un desbordamiento del búfer (desbordamiento del búfer). La estrategia de asignación de espacio de SDS elimina por completo la posibilidad de desbordamiento del búfer. Cuando sea necesario modificar el SDS, primero verificará si el espacio del SDS cumple con los requisitos para la modificación. De lo contrario, el espacio del SDS se ampliará a el lugar donde se realiza la modificación El tamaño requerido, y luego se realiza la operación de modificación real, por lo que el uso de SDS no requiere la modificación manual del tamaño del espacio del SDS, y no habrá problemas de desbordamiento de búfer.
En SDS, la longitud de la matriz buf no es necesariamente el número de caracteres más uno, la matriz puede contener bytes no utilizados y el número de estos bytes se registra mediante el atributo libre de SDS. A través del espacio no utilizado, SDS implementa dos estrategias de optimización: asignación previa de espacio y liberación de espacio diferido:
- Preasignación de espacio: cuando se modifica una SDS y es necesario ampliarla, el programa no solo asignará el espacio necesario para la modificación de la SDS, sino que también asignará espacio adicional no utilizado para la SDS. Antes de expandir el espacio SDS, verificará si el espacio no utilizado es suficiente. Si hay suficiente, el espacio no utilizado se utilizará directamente sin realizar una reasignación de memoria. Si no es suficiente expandirse de acuerdo con el método de (len + addlen (nuevo byte)) * 2, cuando sea mayor a 1M, solo aumentará el tamaño en 1M cada vez. A través de esta estrategia de asignación previa, SDS reduce la cantidad de reasignaciones de memoria requeridas para hacer crecer continuamente una cadena N veces desde una cierta cantidad de veces hasta un máximo de N veces.
- Lazy space release: Lazy space release se usa para optimizar la operación de acortamiento de cadenas de SDS: cuando la cadena guardada por SDS necesita acortarse, el programa no usa inmediatamente la reasignación de memoria para recuperar los bytes adicionales después del acortamiento, sino que usa el atributo libre Registre el número de estos bytes y espere su uso futuro.
3.3.3 Seguridad binaria
Los caracteres en la cadena C deben ajustarse a una determinada codificación (como ASCII, y la cadena no puede contener caracteres nulos excepto al final de la cadena; de lo contrario, el primer carácter nulo leído por el programa se confundirá con el final de la cadena. .
Todas las API de SDS son binarias seguras: los datos almacenados en la matriz buf por SDS se procesarán de manera binaria, y el programa no hará restricciones, filtros ni suposiciones sobre los datos: los datos están en el aspecto que tenían. cuándo fue escrito, qué aspecto tenía cuando se leyó. En lugar de usar esta matriz para contener caracteres, redis la usa para contener una serie de datos binarios.
3.4 Optimización de la estructura SDS
Los datos almacenados en el tipo String pueden contener una gran cantidad de datos de este tipo en varios bytes, pero el tipo int de los atributos len y free ocupará 4 bytes y un total de 8 bytes de almacenamiento.Después de 3.2, sdshdr5, sdshdr8 Los datos , sdshdr16, sdshdr32 y sdshdr64 se utilizarán de acuerdo con el tamaño de la cadena. Estructura de almacenamiento, la estructura específica es la siguiente:
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};- unsign char flags: 3 bits indica tipo, 5 bits indica longitud no utilizada
- len: indica la longitud utilizada
- alloc: indica el tamaño del espacio asignado, y el espacio restante se puede obtener usando alloc - len
3.5 Codificación del juego de caracteres
RedisObject ajusta el valor del valor almacenado y optimiza el almacenamiento de datos a través de la codificación del conjunto de caracteres. Existen tres métodos de codificación para el tipo de cadena de la siguiente manera:
- embstr: la
CPU lee datos de acuerdo con la línea de caché 64 bytes cada vez. Un objeto redisObject tiene 16 bytes. Para llenar el tamaño de 64 bytes, leerá 48 bytes de datos hacia atrás. Sin embargo, al obtener los datos reales, es necesario leer los datos correspondientes a la dirección de memoria a través del puntero *ptr. La información de un atributo sdshdr8 ocupa 4 bytes, y los 44 bytes restantes se pueden usar para almacenar datos. Si el valor es inferior a 44, el byte puede obtener datos leyendo la línea de caché una vez.

- int:
si el SDS tiene menos de 20 bits y se puede convertir a un número entero, el puntero *ptr de redisObject se almacenará directamente.

- crudo:
SDS

4 Resumen
Redis se usa como almacenamiento de datos kv, porque la complejidad temporal de la búsqueda y la operación es O(1) y la optimización de tipos de datos y estructuras de datos enriquecidos, comprender estos tipos y estructuras de datos es más propicio para nuestro uso habitual de redis. El próximo número presentará ZipList, QuickList y SkipList utilizados por otros tipos de datos de uso común Lista, Hash, Conjunto y Conjunto ordenado. Para los lugares poco claros e inexactos en el artículo, puede discutir e intercambiar.
Autor: Sheng Xu