DRLib : una biblioteca de aprendizaje por refuerzo conciso que integra HER y PER
Mi biblioteca DRL con tensorflow1.14 y pytorch, agregue HER y PER, códigos centrales basados en spinning
Prefacio:
Por favor asterisco, ¡bienvenido a abrir ediciones!
El marco principal se basa en spinningup.
En la actualidad, los principales algoritmos de mejora fuera de la política de las versiones tf1 y antorcha son compartidos, DDPG, SAC, TD3, y se han agregado paquetes HER y PER muy concisos a cada algoritmo , lo cual es conveniente para llamar.
Todavía es un proceso único y se está aprendiendo multiproceso.
El PPO de la serie sobre políticas aún no se ha resuelto, por lo que lo agregaré esta semana.
El DQN de acción discreta también tiene códigos prefabricados, que no están bien empaquetados.
DRLib: una biblioteca de aprendizaje de refuerzo profundo conciso, que integra HER y PER para algoritmos de RL casi fuera de la política
Una biblioteca concisa de aprendizaje por refuerzo profundo, que integra HER y PER para algoritmos de RL casi fuera de las políticas.
Con tensorflow1.14 y pytorch, agregue HER y PER, códigos centrales basados en https://github.com/openai/spinningup
En comparación con el giro, elimino el contenedor de cuadrícula experimental y multiproceso, y nuestra ventaja es que es conveniente depurar con pycharm ~
Características del proyecto:
-
Hay dos versiones de tf1 y pytorch, la primera es rápida, la última es nueva, puede elegir;
-
Sobre la base del spinup, se encapsulan los algoritmos de mejora convencionales como DDPG, TD3, SAC. En comparación con la encapsulación de la función original, es más conveniente llamar y se agrega la llamada GPU de pytorch ;
-
Se agregaron funciones HER y PER , que son muy adecuadas para estudiantes que realizan tareas relacionadas con robots;
-
Se eliminaron las partes de ajuste automático de parámetros (ExperimentGrid) y multiproceso (MPI_fork), adecuadas para que los principiantes depuren en pycharm, el primero a menudo informará errores cuando se ejecute directamente ~ Cuando sea
competente en estos dos, los agregaré y adjuntaré un tutorial detallado; -
Por último, ¡el tutorial de configuración del entorno más detallado de toda la red! ¡Dentro de las dos horas posteriores a la prueba profesional, un conjunto completo de entornos desde cero configuración!
-
¡Pide tres veces consecutivas, no una estrella!
1. Instalación
-
Clone el repositorio y cd en él:
git clone https://github.com/kaixindelele/DRLib.git cd DRLib -
Crear anaconda DRLib_env env:
conda create -n DRLib_env python=3.6.9 source activate DRLib_env -
Instale pip_requirement.txt:
pip install -r pip_requirement.txtSi la instalación de mpi4py falla, intente el siguiente comando (¡solo este se puede instalar correctamente!):
conda install mpi4py -
Instalar tensorflow-gpu = 1.14.0
conda install tensorflow-gpu==1.14.0 # if you have a CUDA-compatible gpu and proper drivers -
Instalar antorcha antorcha
# CUDA 9.2 conda install pytorch==1.6.0 torchvision==0.7.0 cudatoolkit=9.2 -c pytorch # CUDA 10.1 conda install pytorch==1.6.0 torchvision==0.7.0 cudatoolkit=10.1 -c pytorch # CUDA 10.2 conda install pytorch==1.6.0 torchvision==0.7.0 cudatoolkit=10.2 -c pytorch # CPU Only conda install pytorch==1.6.0 torchvision==0.7.0 cpuonly -c pytorch # or pip install pip --default-timeout=100 install torch -i http://pypi.douban.com/simple --trusted-host pypi.douban.com [pip install torch 在线安装!非离线!](https://blog.csdn.net/hehedadaq/article/details/111480313) -
Instalar mujoco y mujoco-py
refer to: https://blog.csdn.net/hehedadaq/article/details/109012048 -
Instalar gimnasio [todos]
refer to https://blog.csdn.net/hehedadaq/article/details/110423154
2. Modelos de formación
- Ejemplo 1. SAC-tf1-HER-PER con FetchPush-v1:
- modifique los parámetros en argumentos.py, elija env, algoritmo RL, use PER y HER o no, gpu-id, y así sucesivamente.
- ejecutar con train_tf.py o train_torch.py
python train_tf.py - exp resultados a local: https://blog.csdn.net/hehedadaq/article/details/114045615
- resultados de la trama: https://blog.csdn.net/hehedadaq/article/details/114044217
3. Árbol de archivos e introducción:
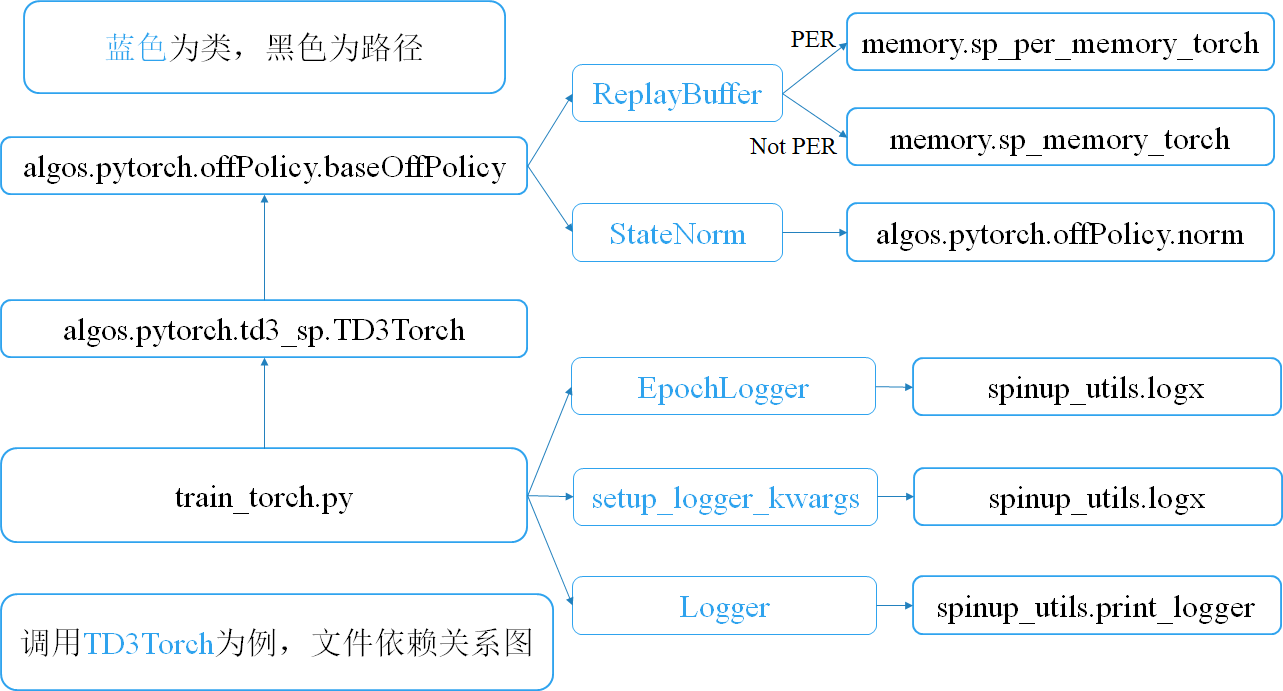
.
├── algos
│ ├── pytorch
│ │ ├── ddpg_sp
│ │ │ ├── core.py-------------It's copied directly from spinup, and modified some details.
│ │ │ ├── ddpg_per_her.py-----inherits from offPolicy.baseOffPolicy, can choose whether or not HER and PER
│ │ │ ├── ddpg.py-------------It's copied directly from spinup
│ │ │ ├── __init__.py
│ │ ├── __init__.py
│ │ ├── offPolicy
│ │ │ ├── baseOffPolicy.py----baseOffPolicy, can be used to DDPG/TD3/SAC and so on.
│ │ │ ├── norm.py-------------state normalizer, update mean/std with training process.
│ │ ├── sac_auto
│ │ ├── sac_sp
│ │ │ ├── core.py-------------likely as before.
│ │ │ ├── __init__.py
│ │ │ ├── sac_per_her.py
│ │ │ └── sac.py
│ │ └── td3_sp
│ │ ├── core.py
│ │ ├── __init__.py
│ │ ├── td3_gpu_class.py----td3_class modified from spinup
│ │ └── td3_per_her.py
│ └── tf1
│ ├── ddpg_sp
│ │ ├── core.py
│ │ ├── DDPG_class.py------------It's copied directly from spinup, and wrap algorithm from function to class.
│ │ ├── DDPG_per_class.py--------Add PER.
│ │ ├── DDPG_per_her_class.py----DDPG with HER and PER without inheriting from offPolicy.
│ │ ├── DDPG_per_her.py----------Add HER and PER.
│ │ ├── DDPG_sp.py---------------It's copied directly from spinup, and modified some details.
│ │ ├── __init__.py
│ ├── __init__.py
│ ├── offPolicy
│ │ ├── baseOffPolicy.py
│ │ ├── core.py
│ │ ├── norm.py
│ ├── sac_auto--------------------SAC with auto adjust alpha parameter version.
│ │ ├── core.py
│ │ ├── __init__.py
│ │ ├── sac_auto_class.py
│ │ ├── sac_auto_per_class.py
│ │ └── sac_auto_per_her.py
│ ├── sac_sp--------------------SAC with alpha=0.2 version.
│ │ ├── core.py
│ │ ├── __init__.py
│ │ ├── SAC_class.py
│ │ ├── SAC_per_class.py
│ │ ├── SAC_per_her.py
│ │ ├── SAC_sp.py
│ └── td3_sp
│ ├── core.py
│ ├── __init__.py
│ ├── TD3_class.py
│ ├── TD3_per_class.py
│ ├── TD3_per_her_class.py
│ ├── TD3_per_her.py
│ ├── TD3_sp.py
├── arguments.py-----------------------hyperparams scripts
├── drlib_tree.txt
├── HER_DRLib_exps---------------------demo exp logs
│ ├── 2021-02-21_HER_TD3_FetchPush-v1
│ │ ├── 2021-02-21_18-26-08-HER_TD3_FetchPush-v1_s123
│ │ │ ├── checkpoint
│ │ │ ├── config.json
│ │ │ ├── params.data-00000-of-00001
│ │ │ ├── params.index
│ │ │ ├── progress.txt
│ │ │ └── Script_backup.py
├── memory
│ ├── __init__.py
│ ├── per_memory.py--------------mofan version
│ ├── simple_memory.py-----------mofan version
│ ├── sp_memory.py---------------spinningup tf1 version, simple uniform buffer memory class.
│ ├── sp_memory_torch.py---------spinningup torch-gpu version, simple uniform buffer memory class.
│ ├── sp_per_memory.py-----------spinningup tf1 version, PER buffer memory class.
│ └── sp_per_memory_torch.py
├── pip_requirement.txt------------pip install requirement, exclude mujoco-py,gym,tf,torch.
├── spinup_utils-------------------some utils from spinningup, about ploting results, logging, and so on.
│ ├── delete_no_checkpoint.py----delete the folder where the experiment did not complete.
│ ├── __init__.py
│ ├── logx.py
│ ├── mpi_tf.py
│ ├── mpi_tools.py
│ ├── plot.py
│ ├── print_logger.py------------save the information printed by the terminal to the local log file。
│ ├── run_utils.py---------------now I haven't used it. I have to learn how to multi-process.
│ ├── serialization_utils.py
│ └── user_config.py
├── train_tf1.py--------------main.py for tf1
└── train_torch.py------------main.py for torch
4. SU introducción:
Consulte estas bases de códigos:
-
Puede converger, pero este código es demasiado difícil. https://github.com/openai/baselines
-
También puede converger, pero solo para DDPG-torch-cpu. https://github.com/sush1996/DDPG_Fetch
-
No se puede converger, pero este código es más simple. https://github.com/Stable-Baselines-Team/stable-baselines
4.1. Mi comprensión y video:
Plantar melones para obtener frijoles para explicarle: El
primer paso es cultivar frijoles en primavera (origen-meta) para obtener frijoles. A través de ELLA, cambia el objetivo a sembrar frijoles. De acuerdo con la operación anterior, puedes aprender a cultivar frijoles y conseguir frijoles en primavera.; El
segundo paso es plantar melones y aprender a cultivar melones;
es decir, siempre que sea el estado vivido en medio del agente, se puede utilizar como objetivo y aprender.
Es decir, si el cuerpo inteligente puede atravesar todos los espacios de estados, entonces puede aprender a llegar a todo el espacio de estados.
https://www.bilibili.com/video/BV1BA411x7Wm
4.2. Trucos clave para ELLA:
- state-normalize: tasa de éxito de 0 a 1 para la tarea FetchPush-v1.
- Q-clip: tasa de éxito de 0.5 a 0.7 para la tarea FetchPickAndPlace-v1.
- action_l2: poco efecto para la tarea Push.
4.3. Rendimiento sobre HER-DDPG con FetchPush-v1:
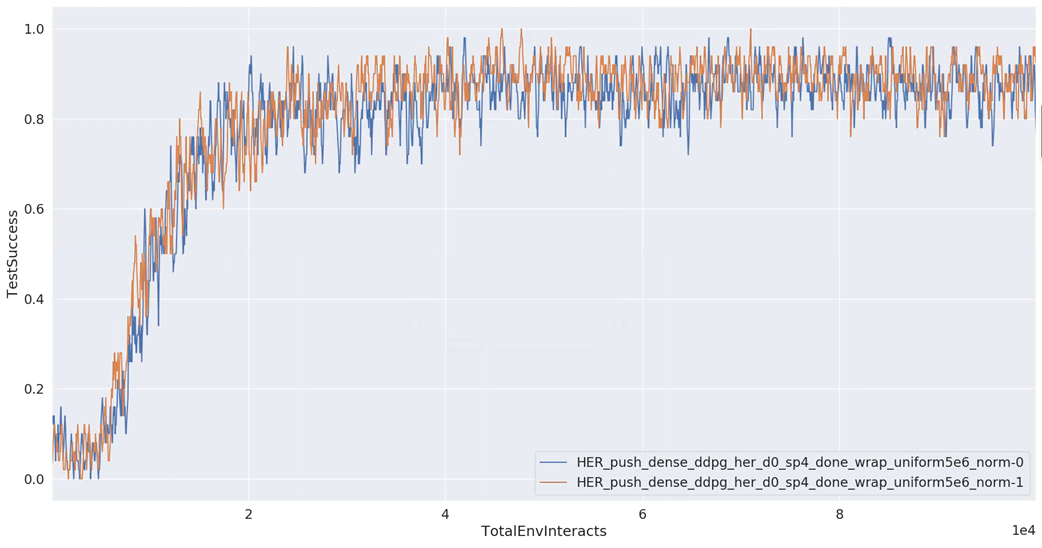
5. POR introducción:
6. Resumen:
He encapsulado esta biblioteca durante mucho tiempo. Toda la biblioteca de código es simple, conveniente y tiene funciones relativamente completas. La configuración del entorno es casi un tutorial práctico. Espero ahorrarle algo de tiempo ~
Comenzando desde cero, tomó menos de dos horas, desde la descarga del código base hasta la configuración del entorno y la ejecución del entorno, todo el proceso fue muy fluido.
6.1. Funciones que se agregarán en el siguiente paso:
-
Envases PPO;
-
Paquete DQN;
-
Encapsulación multiproceso;
-
Encapsulación de ExperimentGrid;
7. Contacto:
Aprendizaje de refuerzo profundo-DRL: 799378128
Bienvenido a seguir la cuenta de Zhihu: aprendices de alquimia que aún no han comenzado
Cuenta CSDN: https://blog.csdn.net/hehedadaq