1. Definiciones básicas
Comparación de RL con el aprendizaje supervisado y el aprendizaje no supervisado:
(1) El aprendizaje supervisado es aprender de un conjunto de entrenamiento etiquetado. Las características de cada muestra en el conjunto de entrenamiento pueden considerarse como una descripción de la situación, y su etiqueta puede considerarse como la acción correcta que se debe ejecutar, pero el aprendizaje supervisado no puede aprender situaciones interactivas, porque es muy poco práctico obtener muestras del comportamiento esperado en problemas interactivos, y el agente solo puede aprender de su propia experiencia (experiencia) Aprendizaje en la experiencia, y el comportamiento tomado en la experiencia no es necesariamente óptimo. En este momento, es muy apropiado usar RL, porque RL no usa el comportamiento correcto para guiar, sino que usa la información de entrenamiento existente para evaluar el comportamiento .
(2) Debido a que RL no usa la experiencia de tomar acciones correctas, de hecho es un poco similar al aprendizaje no supervisado desde este punto de vista, pero aún es diferente. Se puede decir que el propósito del aprendizaje no supervisado es de un montón de muestras sin etiquetar La estructura oculta se encuentra en , y el propósito de RL es maximizar la señal de recompensa .
(3) En general, RL es diferente de otros algoritmos de aprendizaje automático en que: no hay supervisor, solo una señal de recompensa; la retroalimentación se demora, no se genera de inmediato; el tiempo es de gran importancia en RL; el comportamiento del agente afectará la serie posterior de datos.
Los elementos clave del aprendizaje por refuerzo son: entorno, recompensa, acción y estado. Con estos elementos podemos construir un modelo de aprendizaje por refuerzo.
El problema que resuelve el aprendizaje por refuerzo es obtener una política óptima para un problema específico, de modo que la recompensa obtenida bajo esta política sea la mayor. La llamada política es en realidad una serie de acciones, es decir, datos secuenciales.
El aprendizaje por refuerzo se puede describir con la siguiente figura: es necesario extraer un entorno de la tarea a completar y abstraer el estado (estado), la acción (acción) y la recompensa instantánea (recompensa) por realizar la acción.
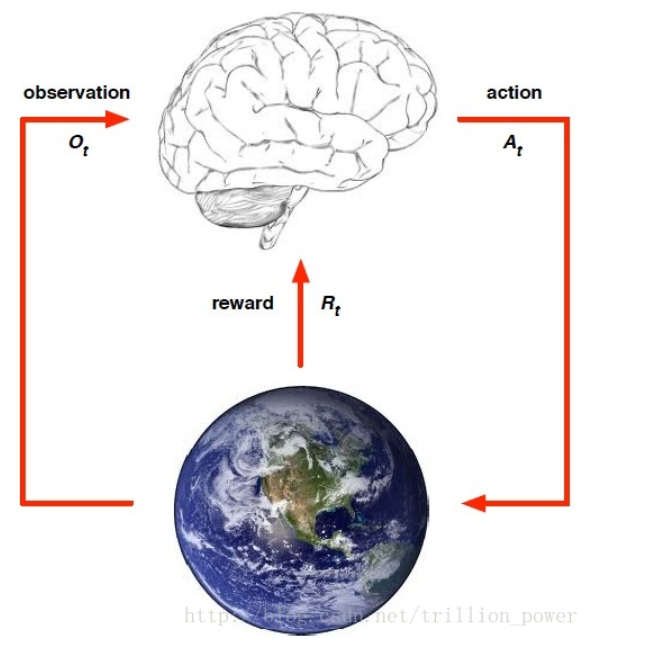
- recompensa recompensa
generalmente se registra como, lo que indica el valor de recompensa de retorno del t-ésimo paso de tiempo. Todo el aprendizaje por refuerzo se basa en la suposición de la recompensa, y la recompensa es un escalar. - Acción
La acción proviene del espacio de acción, y el agente usa el estado en el que se encuentra cada vez y la recompensa del estado anterior para determinar qué acción ejecutar en ese momento. Para ejecutar una acción para maximizar la recompensa esperada hasta que el algoritmo final converja, la política resultante son los datos secuenciales de una serie de acciones. - estado
se refiere al estado actual del agente - política
La política es solo el comportamiento del agente, que es el mapeo del estado a la acción. Se divide en estrategia definida y estrategia aleatoria. La estrategia definida es la acción definida en un cierto estado, y la estrategia aleatoria se describe por probabilidad, que es decir, la puesta en práctica de esta estrategia en un determinado estado de probabilidad de acción.
- función de valor
Porque el aprendizaje por refuerzo se puede resumir básicamente en obtener una estrategia óptima maximizando la recompensa. Pero si solo la recompensa instantánea es la más grande, solo elegirá la acción con la recompensa más grande del espacio de acción cada vez, lo que se convierte en la política codiciosa más simple (Política codiciosa), por lo que para describirlo bien, incluye la actual recompensa en el futuro El valor es el más grande (incluso si la recompensa total desde el momento actual hasta que el estado alcanza la meta es la más grande). Por lo tanto, se construye una función de valor para describir esta variable. La expresión es la siguiente
: Error de análisis de KaTeX: {ecuación} solo se puede usar en el modo de visualización.
Es un coeficiente de descuento, que sirve para reducir el impacto de las recompensas futuras en la acción actual y luego maximizar la función de valor seleccionando un política apropiada. La famosa ecuación de Bellman es la fuente de los algoritmos de aprendizaje por refuerzo (por ejemplo, iteración de valor, iteración de estrategia, Q-learning).
- modelo
El modelo se utiliza para predecir qué hará el entorno a continuación, es decir, qué estado se logrará al realizar una acción en este estado y qué recompensa se obtendrá por esta acción. Entonces, describir un modelo es usar la probabilidad de transición de acción y la recompensa del estado de acción. La fórmula específica es la siguiente: En el aprendizaje por refuerzo, el agente (agente) se coloca en un determinado entorno (ambiente). En correspondencia con el ejemplo de Go, el jugador es el agente y el entorno es el tablero. En cualquier momento, el entorno siempre está en algún estado (estado), que proviene de un conjunto de estados posibles, y para Go, el estado se refiere al estado de diseño del tablero. El decisor puede realizar un conjunto de acciones posibles (movimientos legales de piezas). Una vez que se selecciona y realiza una acción, el estado cambia en consecuencia. La resolución de problemas requiere la ejecución de una secuencia de acciones, seguida de una retroalimentación en forma de recompensa que rara vez ocurre, generalmente solo después de que se haya realizado la secuencia completa de acciones.
2. Procesos de decisión de Markov finitos
Los MDP son simplemente un proceso cíclico en el que un agente (Agente) realiza una acción (Acción), cambia su estado (Estado) para obtener una recompensa (Recompensa) e interactúa con el entorno (Entorno).
La estrategia de MDP depende completamente del estado actual (Solo asuntos presentes), que también es una manifestación de la naturaleza markoviana.
2.1. La interfaz agente-entorno
El problema de aprendizaje por refuerzo es un marco simple para aprender de las interacciones para lograr un objetivo deseado. Los aprendices y los que toman decisiones se denominan agentes, y aquellos que interactúan con los agentes se denominan entornos. La interacción está en curso, el agente elige realizar acciones y el entorno reacciona a las acciones realizadas por el agente, convirtiendo al agente en otro entorno nuevo. Al mismo tiempo, el entorno genera recompensas y el agente trata de maximizar estas recompensas con el tiempo.
En instantes de tiempo, el agente observa información sobre el entorno, donde se encuentra el conjunto de todos los estados posibles. En este entorno, el agente elige una acción, que representa el conjunto de todas las acciones que se pueden realizar en el estado. En el momento siguiente, debido a la acción, el agente obtiene una recompensa numérica y, al mismo tiempo, el agente se encuentra en un nuevo estado. La siguiente figura muestra el proceso de interacción entre el agente y el entorno.
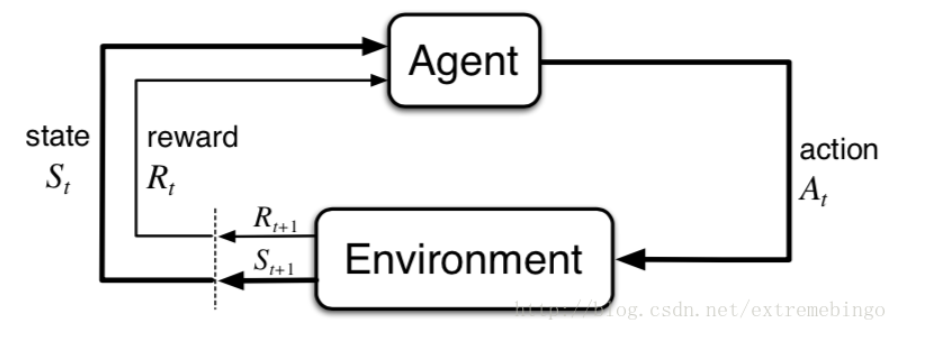
Bajo la acción conjunta de MDP y el agente, se genera una secuencia, también conocida como
error de análisis KaTeX de trayectoria: {ecuación} solo se puede usar en modo de visualización.
Por el momento, dado el estado y la acción, el estado y la recompensa del momento aparece La probabilidad de
error de análisis de KaTeX: {ecuación} solo se puede usar en el modo de visualización
La probabilidad de transición de estado es
error de análisis de KaTeX: {ecuación} solo se puede usar en el modo de visualización
La recompensa esperada de la acción de estado es
el análisis de KaTeX error: {ecuación} solo se puede usar en modo de visualización
Valor esperado de state-action-next_state tuple
KaTeX parse error: {ecuación} solo se puede usar en modo de visualización.
Ejemplo:
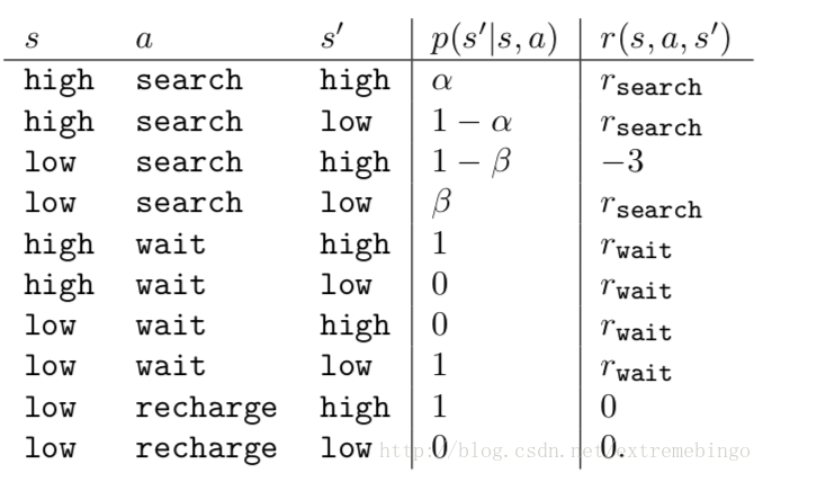
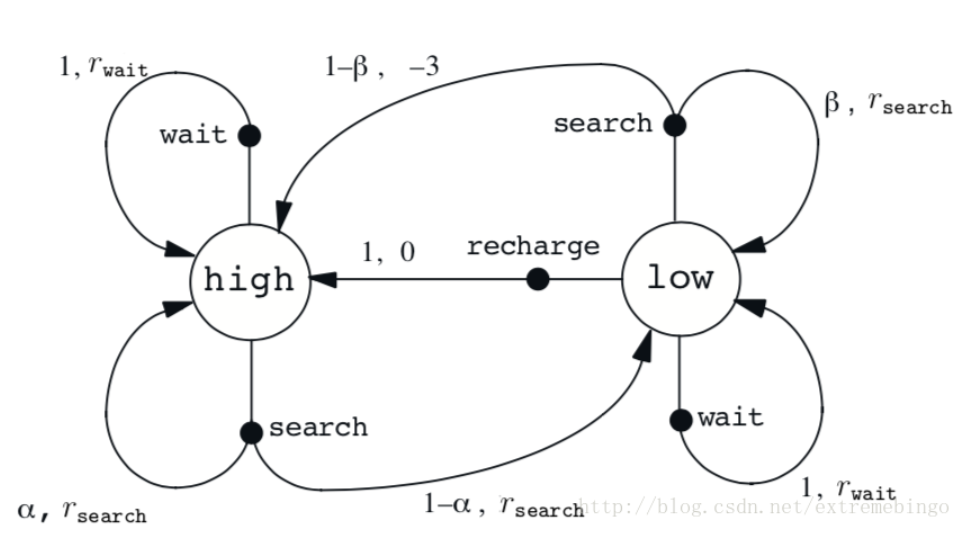
Un robot de reciclaje, utilizado para recolectar latas de refresco en las oficinas, funciona con baterías recargables e incluye sensores para detectar latas y pinzas para recogerlas y recolectarlas. La estrategia de cómo buscar frascos la realiza un agente de aprendizaje por refuerzo basado en el nivel actual de la batería. El agente puede hacer que el robot haga las siguientes cosas
- (1) Buscar activamente durante un período de tiempo;
- (2) Esperar por un período de tiempo, esperando que alguien traiga el frasco;
- (3) Vuelve y carga. Por lo tanto, el agente tiene tres acciones. El estado está determinado por el estado de la batería. Cuando el robot obtiene el frasco, obtiene una recompensa positiva, y cuando se agota la batería, obtiene una gran recompensa negativa. Suponga que la regla de cambio del estado es: la mejor manera de obtener el frasco es buscar activamente, pero esto consumirá energía, pero esperar en el lugar no consumirá energía. Cuando la batería está baja, realizar una búsqueda puede agotar la batería, en cuyo caso el robot debe apagarse y esperar el rescate.
La acción realizada por el agente solo depende de la energía, por lo tanto, el estado establecido es, y las acciones del agente incluyen esperar, buscar y recargar. Por lo tanto, el conjunto de acciones del agente es: si la potencia es alta, una búsqueda generalmente no agotará la batería, y la probabilidad de alta potencia después de la búsqueda es α \alphaα , la probabilidad de batería baja es1 − α 1-\alpha1−α _ Cuando la batería está baja, la probabilidad de que aún esté baja después de realizar una búsqueda es1 − β 1-\beta1−β , la probabilidad de agotar la batería esβ \betaβ , entonces el robot debe cargarse, por lo que el estado cambiará a alto. Cada búsqueda activa será recompensada y la espera será recompensada,rwait r_{wait}respera _ _. Cuando el robot necesita ser rescatado, la recompensa es rsearch r_{search}rbuscar _ _ _。
2.2. Objetivos y recompensas
En el aprendizaje por refuerzo, el objetivo del agente es obtener la recompensa que le pasa el entorno. En cada momento, la recompensa es un valor específico, y el objetivo del agente es maximizar su recompensa esperada. Esto significa no maximizar las recompensas inmediatas, sino las recompensas acumulativas a lo largo del tiempo.
2.3. Devoluciones y episodios
2.2 describe el objetivo del aprendizaje por refuerzo, expresado en forma matemática a continuación. Después del instante de tiempo, la secuencia de recompensas obtenida es G t G_{t}GRAMOt. Por lo general, buscamos el rendimiento máximo esperado. La recompensa puede considerarse como una función de la secuencia de recompensas. La forma más simple de recompensa es sumar directamente las recompensas
G t ≐ R t + 1 + R t + 2 + R t + 3 + ⋯ + RT G_{t} \doteq R_ {t+1}+R_{t+2}+R_{t+3}+\cdots+R_{T}GRAMOt≐Rt + 1+Rt + 2+Rt + 3+⋯+RT
Entre ellos, T.T.T es el momento de la parada final. En particular, llamamos a un experimento con un número limitado de pasos un solo episodio, es decir, después de un número limitado de pasos, eventualmente entrará en un estado terminal.Este tipo de tarea también se denomina tareas episódicas, como jugar juegos.
En algunos casos, la interacción entre el agente y el entorno no se detendrá. Tales tareas se denominan tareas continuas, como tareas de control. En este momento, en este caso, el retorno puede tender a infinito. Por ejemplo, en cada paso, la recompensa que obtiene el agente es +1.
En este momento, apareció el concepto de descuento. El agente elige una serie de acciones para maximizar la suma de futuras recompensas con descuento. Es decir, elegir la expectativa que maximiza el rendimiento descontado
G t ≐ R t + 1 + γ R t + 2 + γ 2 R t + 3 + ⋯ = ∑ k = 0 ∞ γ k R t + k + 1 G_ {t} \doteq R_{t+1}+\gamma R_{t+2}+\gamma^{2} R_{t+3}+\cdots=\sum_{k=0}^{\infty} \ gamma^{ k} R_{t+k+1}GRAMOt≐Rt + 1+γ Rt + 2+C2R _t + 3+⋯=∑k = 0∞Ck Rt + k + 1
2.4.Políticas y funciones de valor
Casi todo el aprendizaje por refuerzo necesita calcular la función de valor -una función sobre el estado o una función sobre el estado- acción para estimar el valor del agente en un estado determinado (o realizar una acción en un estado determinado), es decir, el recompensa futura. Obviamente, las recompensas futuras dependen de las acciones realizadas, por lo tanto, las funciones de valor se definen para estrategias específicas.Para el mismo problema de aprendizaje por refuerzo, diferentes estrategias tendrán diferentes funciones de valor.
Usos: aprendizaje por refuerzo para resolver la programación dinámica, la teoría de las máquinas de aprendizaje extremo (investigación sobre la selección de puntos de medición) y el aprendizaje por refuerzo como método de selección de características.