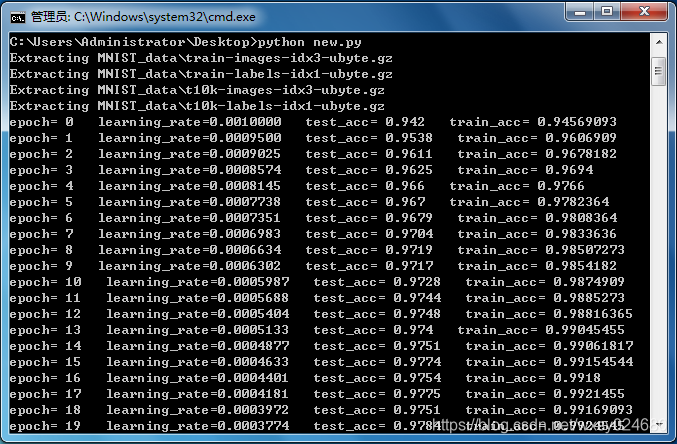
Al crear el modelo, puede elegir el optimizador con la velocidad de convergencia más rápida para aumentar la velocidad de entrenamiento; al generar los resultados, se recomienda que cada optimizador vuelva a intentarlo y, finalmente, elija el optimizador con la mayor precisión. Ningún optimizador es absolutamente bueno, solo lo sabrás si lo pruebas.
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# 获取数据集
# one_hot设置为True,将标签数据转化为0/1,如[1,0,0,0,0,0,0,0,0,0]
mnist=input_data.read_data_sets('MNIST_data',one_hot=True)
# 定义一个批次的大小
batch_size=100
n_batch=mnist.train.num_examples//batch_size
# 定义三个placeholder
# 行数值为None,None可以取任意数,本例中将取值100,即取决于pitch_size
# 列数值为784,因为输入图像尺寸已由28*28转换为1*784
x=tf.placeholder(tf.float32,[None,784])
y=tf.placeholder(tf.float32,[None,10])
keep_prob=tf.placeholder(tf.float32)
# 定义学习率
lr=tf.Variable(0.001,dtype=tf.float32)
# 定义一个神经网络
# 权重初始值为0不是最优的,应该设置为满足截断正态分布的随机数,收敛速度更快
w1=tf.Variable(tf.truncated_normal([784,1000],stddev=0.1))
# 偏置初始值为0不是最优的,可以设置为0.1,收敛速度更快
b1=tf.Variable(tf.zeros([1000])+0.1)
# 引入激活函数
l1=tf.nn.tanh(tf.matmul(x,w1)+b1)
# 引入dropout
l1_drop=tf.nn.dropout(l1,keep_prob)
w2=tf.Variable(tf.truncated_normal([1000,100],stddev=0.1))
b2=tf.Variable(tf.zeros([100])+0.1)
l2=tf.nn.tanh(tf.matmul(l1_drop,w2)+b2)
l2_drop=tf.nn.dropout(l2,keep_prob)
w3=tf.Variable(tf.truncated_normal([100,10],stddev=0.1))
b3=tf.Variable(tf.zeros([10])+0.1)
# softmax的作用是将tf.matmul(l2_drop,w3)+b3的结果转换为概率值,举例如下:
# [9,2,1,1,2,1,1,2,1,1]
# [0.99527,0.00091,0.00033,0.00033,0.00091,0.00033,0.00033,0.00091,0.00033,0.00033]
prediction=tf.nn.softmax(tf.matmul(l2_drop,w3)+b3)
# 定义损失函数
# 由于输出神经元为softmax,交叉熵损失函数比均方误差损失函数收敛速度更快
# loss=tf.reduce_mean(tf.square(y-prediction))
loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=prediction))
# 定义优化器
# AdamOptimizer比GradientDescentOptimizer收敛速度更快
# optimizer=tf.train.GradientDescentOptimizer(0.2)
optimizer=tf.train.AdamOptimizer(lr)
# 定义模型,优化器通过调整loss里的参数,使loss不断减小
train=optimizer.minimize(loss)
# 统计准确率
# tf.argmax返回第一个参数中最大值的下标
# tf.equal比较两个参数是否相等,返回True或False
correct_prediction=tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))
# tf.cast将布尔类型转换为浮点类型
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# epoch为周期数,所有批次训练完为一个周期
for epoch in range(20):
# 调整学习率,输出值越接近真实值,学习率越低,防止优化器调整步伐过大
sess.run(tf.assign(lr,0.001*(0.95**epoch)))
for batch in range(n_batch):
# 每次取出batch_size条数据进行训练
batch_xs,batch_ys=mnist.train.next_batch(batch_size)
sess.run(train,feed_dict={
x:batch_xs,y:batch_ys,keep_prob:0.9})
learning_rate=sess.run(lr)
test_acc = sess.run(accuracy,feed_dict={
x:mnist.test.images,y:mnist.test.labels,keep_prob:0.9})
train_acc = sess.run(accuracy,feed_dict={
x:mnist.train.images,y:mnist.train.labels,keep_prob:0.9})
print('epoch=',epoch,' ','learning_rate=%.7f' % learning_rate,' ','test_acc=',test_acc,' ','train_acc=',train_acc)
resultado de la operación: