
Visión general
La explicación en este libro es general, principalmente para explicar
缓冲区
通道
选择器
正则表达式
字符集
Explica principalmente el uso de api y algunos conocimientos del sistema, que es de nivel relativamente bajo, y la mayoría de ellos son la explicación del código fuente del código, o la explicación del uso de api, que es demasiado detallada.
Puedes echarle un vistazo a esto antes de aprender netty, o los dos pueden compensarse.
La sugerencia es que si no usa Netty, no lo aprenda, es de un nivel relativamente bajo y lo olvidará después de leerlo.
Muerdo la bala y lo leo toscamente, y si tengo tiempo, veámoslo por segunda vez.
1. Introducción
La diferencia entre java io y system io
En la mayoría de los casos, las aplicaciones Java no están realmente limitadas por E / S. No es que el sistema operativo no pueda transferir
datos rápidamente para que Java tenga algo que hacer; por el contrario, la JVM en sí no es eficiente en términos de E / S. El sistema operativo
no coincide con el modelo de E / S basado en flujo de Java . Lo que el sistema operativo quiere mover es un gran bloque de datos (búfer), lo que a menudo se
hace con la ayuda de acceso directo a memoria (DMA) por hardware . A la clase de E / S de JVM le gusta manipular pequeños fragmentos de datos: un solo byte, unas pocas líneas de texto. Como resultado, el
sistema operativo envía los datos en todo el búfer y la clase de datos de flujo de java.io pasa mucho tiempo dividiéndolos en partes pequeñas, a menudo copiando una parte
pequeña hacia y desde varias capas de objetos. Al sistema operativo le gusta transportar los datos en camiones completos, y a la clase java.io le gusta
procesar los datos de una sola vez . Con NIO, puede realizar fácilmente una copia de seguridad de una gran cantidad de datos en un lugar donde pueda usarlos directamente (
objeto ByteBuffer ).
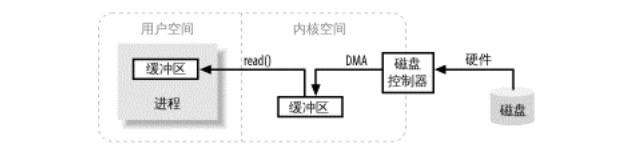
Simplemente apéguese a los métodos read () y write () basados en matrices. Estos métodos están bastante cerca de las llamadas al sistema operativo subyacente, aunque se debe mantener al menos una copia del búfer.
El búfer, y cómo funciona, es la base de todas las E / S. La llamada "entrada / salida" no es más que mover datos dentro o fuera del búfer.
Diagrama de funcionamiento del búfer de E / S
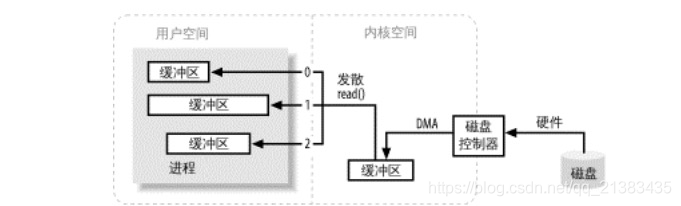
Operación de lectura divergente de tres búferes
Mapeo múltiple del espacio de memoria
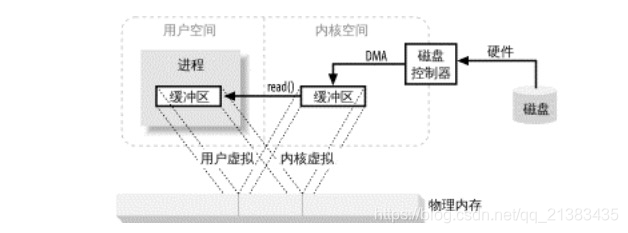
El requisito previo es que el núcleo y los búferes de usuario deben usar la misma alineación de página, y el tamaño del búfer también debe ser un múltiplo del tamaño del bloque del controlador de disco (por lo general, sectores de disco de 512 bytes). El sistema operativo divide el espacio de direcciones de la memoria en páginas, que son grupos de bytes de tamaño fijo. El tamaño de la página de memoria es siempre un múltiplo del tamaño del bloque del disco, generalmente a la potencia de 2 (esto simplifica la operación de direccionamiento).
La falla de la página genera inmediatamente una trampa (similar a una llamada al sistema), que transfiere el control al kernel con información sobre la dirección virtual que causó el error, y luego el kernel toma medidas para verificar la validez de la página.
1.4.1 Archivo IO
- Los discos son dispositivos de hardware y no saben nada sobre archivos.
- El sistema de archivos es un nivel más alto de abstracción, una forma única de organizar e interpretar datos en un disco (u otro dispositivo de bloqueo de acceso aleatorio).
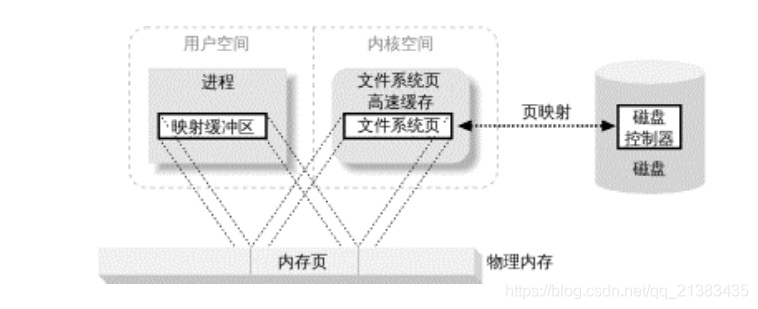
Mapeo de la memoria del usuario a la página del sistema de archivos
Bloqueo de archivos
- El mecanismo de bloqueo de archivos permite que un proceso evite que otros procesos accedan a un archivo o restrinjan sus métodos de acceso. El uso habitual es controlar el método de actualización de la información compartida o para el aislamiento de transacciones. El bloqueo de archivos es esencial para controlar el acceso simultáneo a recursos comunes por parte de múltiples entidades.
数据库等复杂应用严重信赖于文件锁定
Hay dos formas de bloquear archivos: compartidos y exclusivos. Múltiples bloqueos compartidos pueden actuar en la misma área de archivo al mismo tiempo; los bloqueos exclusivos son diferentes, requiere que el área relacionada no pueda tener otros bloqueos en vigor.
2. Tampón
- El búfer es una matriz de elementos de datos básicos envueltos en un objeto.
2.1 Propiedades
Todos los búferes tienen cuatro atributos para proporcionar información sobre los elementos de datos que contienen. Son:
Capacidad
El número máximo de elementos de datos que puede contener el búfer. Esta capacidad se establece cuando se crea el búfer y nunca se puede cambiar.
Límite superior (límite)
El primer elemento del búfer que no se puede leer ni escribir. En otras palabras, el recuento de elementos existentes en el búfer.
Posición
El índice del siguiente elemento que se va a leer o escribir. La posición se actualiza automáticamente mediante las funciones correspondientes get () y put ().
Marcos
Una ubicación de memo. Llame a mark () para establecer mark = postion. Llame a reset () para establecer la posición = marca. La marca no está definida antes de establecerse.
Los cuatro atributos siempre siguen la siguiente relación:
0 <= mark <= position <= limit <= capacity

Este capítulo presenta principalmente varios búferes.
2.2 voltear
La función Flip () voltea un búfer que puede continuar agregando elementos de datos en un estado lleno a un estado liberado que está listo para leer elementos.
Similar al código a continuación
buffer.limit(buffer.position()).position(0);
2.3 claro
La función Clear () restablece el búfer a un estado vacío. No cambia ningún elemento de datos en el búfer, solo establece el límite superior al valor de la capacidad y vuelve a establecer la posición en 0.
2.4 marca
Marque para que el búfer pueda recordar una posición y devolverla más tarde. La marca del búfer no está definida antes de que se llame a la función mark (), y la marca se establece en el valor de la posición actual cuando se llama. La función reset () establece la posición en el valor de marca actual. Si el valor de la marca no está definido, llamar a reset () provocará una excepción InvalidMarkException. Algunas funciones de búfer descartan las banderas que se han establecido (rewind (), clear () y flip () siempre descartan las marcas). Si el valor recién establecido es menor que la marca actual, llamar a limit () o position () con un parámetro de índice descartará la marca.
2.5 Comparación
Las condiciones necesarias y suficientes para que dos búferes se consideren iguales son: 32
- Los dos objetos son del mismo tipo. Los búferes que contienen diferentes tipos de datos nunca son iguales y los búferes nunca son iguales a los objetos que no son búfer.
- Ambos objetos tienen el mismo número de elementos restantes. No es necesario que la capacidad del búfer sea la misma y el índice de los datos restantes en el búfer no tiene que ser el mismo. Pero el número de elementos restantes en cada búfer (desde la posición hasta el límite superior) debe ser el mismo.
- La secuencia de los elementos de datos restantes que debe devolver la función Get () en cada búfer debe ser coherente.
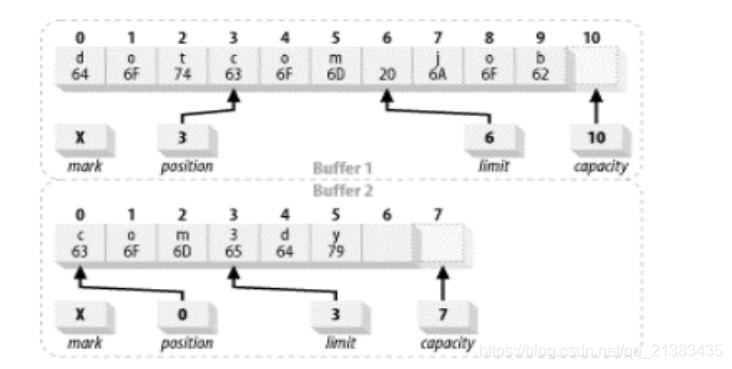
Dos búferes considerados iguales
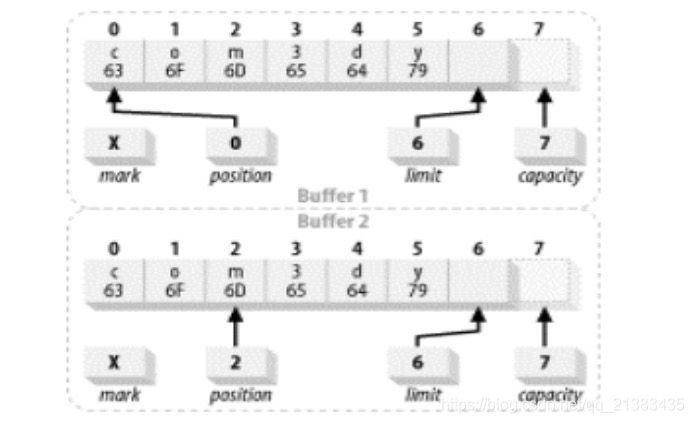
Dos búferes que se consideran desiguales
3.6 Orden de bytes
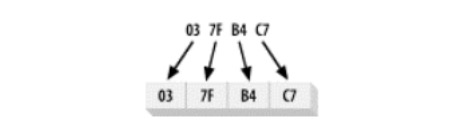
Orden de bytes big-endian
Orden de bytes little-endian
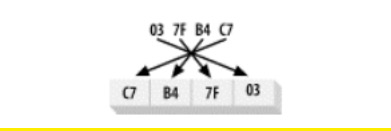
La forma en que los valores multibyte se almacenan en la memoria generalmente se denomina endianidad (orden de bytes). Si el byte más alto del extremo grande del valor digital (extremo grande) se encuentra en la dirección baja, entonces el sistema está en el orden de bytes del big endian. Si el byte más bajo se almacena primero en la memoria, luego el orden de bytes little-endian.
La clase ByteOrder define constantes que determinan qué orden de bytes usar al almacenar o recuperar valores multibyte del búfer.
La clase ByteBuffer es diferente: el orden de bytes predeterminado es siempre ByteBuffer.BIG_ENDIAN, independientemente del orden de bytes inherente del sistema. El orden de bytes predeterminado de Java es el orden de bytes big-endian.