Notas de lectura de papel de disección de red
- 1. Introducción
- 2. Análisis de red
- 3. Experimenta
-
- 3.1 Evaluación humana de las interpretaciones
- 3.2 Medición de la Interpretabilidad Alineada al Eje
- 3.3 Comprender los conceptos de capas
- 3.4 Arquitectura y supervisión de la red
- 3.5 Condiciones de Entrenamiento vs Interpretabilidad
- 3.6 Clasificación vs Interpretabilidad de Redes
- 3.7 Ancho de capa frente a interpretabilidad
- 4. Preguntas y respuestas
- referencia
1. Introducción
Este es un artículo en CVPR 2017 sobre la investigación de la interpretabilidad del aprendizaje profundo. El autor cuantifica la interpretabilidad de las representaciones ocultas de CNN al evaluar la correspondencia entre una sola neurona oculta (unidad) y una serie de conceptos semánticos (concepto).
2. Análisis de red
2.1 Medidas de Interpretabilidad de Representaciones Visuales Profundas
- Identificar un conjunto amplio de conceptos visuales etiquetados por humanos.
- Recopile respuestas neuronales ocultas a conceptos conocidos.
- Cuantificar cómo se mapean (neuronas ocultas, conceptos).
2.2 Conjunto de datos
El autor estableció un conjunto de datos de prueba completo llamado Broden (Conjunto de datos etiquetados de forma amplia y densa), cada imagen tiene una calibración de píxeles en la escena, el objeto, el material, la textura, el color y otros niveles. En la siguiente figura se muestra un ejemplo del conjunto de datos de Broden .

2.3 Puntuación de neuronas interpretable
Alimente cada imagen del conjunto de datos a la red que se va a analizar, obtenga los resultados de respuesta en cada mapa de características, analice más a fondo la relación semántica correspondiente al mapa de características de esta capa y resuma los resultados. El proceso general se muestra en la siguiente figura.
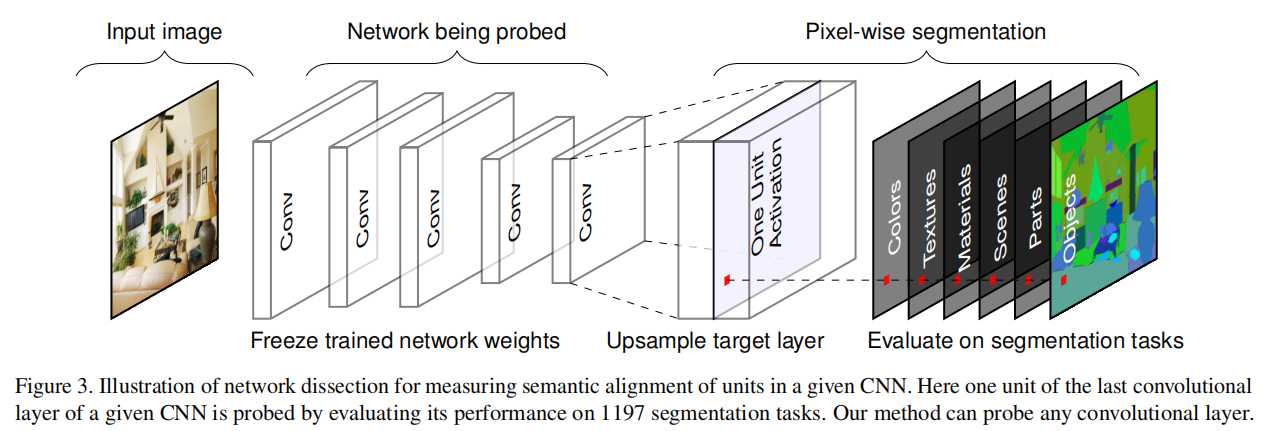
Para cada imagen de entrada xx en el conjunto de datos de Brodenx , recolecta cada kernel de convolución internakkEl mapa de activación de k A k ( x ) A_k (x)Ak( X ) . Luego se calculaak a_kak. Para cada unidad kkk , en cada ubicación espacial del mapa de activación en el conjunto de datos, porP ( ak > T k ) = 0,005 P(a_k>T_k)=0,005P ( unk>Tk)=0.005 determina el cuantil superiorT k T_kTk.
Para comparar el mapa de activación de la unidad de baja resolución con la máscara de anotación de resolución de entrada L c L_cLdoalgunos conceptos de ccc , utilice la interpolación bilineal para activar el mapa de característicasA k ( x ) A_k(x)Ak( x ) escala hasta la resolución de la máscara de entradaS k ( x ) S_k(x)Sk( x ) para fijar la interpolación en el centro del campo receptivo de cada celda.
EntoncesS k ( x ) S_k(x)Sk( x ) Realizar una segmentación de valores binarios según el umbral:M k ( x ) ≡ S k ( x ) ≥ T k M_k(x)≡S_k(x)≥T_kMETROk( X )≡Sk( X )≥Tk, seleccione el mapa de funciones de activación sobre el umbral T k T_kTktodas las áreas de . Para cada par ( k , c ) (k,c)( k ,c ) Calcular la intersecciónM k ( x ) ∩ L c ( x ) M_k(x) ∩ L_c(x)METROk( X )∩Ldo( x ) , para cada concepto ccen el conjunto de datosc para la evaluación. kk
por unidadk como conceptoccLa puntuación de segmentación de c se calcula mediante la siguiente IoU
k , c = ∑ ∣ M k ( x ) ∩ L c ( x ) ∣ ∑ ∣ M k ( x ) ∪ L c ( x ) ∣ IoU_{k ,c} = \frac{\sum|M_k(x) ∩ L_c(x)|}{\sum|M_k(x) ∪ L_c(x)|}yo o tuk , c=∑∣ Mk( X )∪Ldo( X ) ∣∑∣ Mk( X )∩Ldo( X ) ∣
Aquí∣ ⋅ ∣ |\cdot|∣⋅∣ es la cardinalidad de un conjunto. Debido a que el conjunto de datos contiene algunos tipos de etiquetas, estas etiquetas no existen en algunos subconjuntos de entrada, sino solo en el subconjunto de imágenes con al menos uno conccCalcule la suma cuando c tiene la misma etiqueta de concepto. I o U k , c IoU_{k,c}yo o tuk , cEl valor de es la unidad kkconcepto de detección k ccPrecisión de c ; siI o U k , c IoU_{k,c}yo o tuk , csupera un umbral (establecido en 0,04 en el texto), consideramos una unidad kkk como conceptoccdetector c . Tenga en cuenta que una unidad puede ser un detector de múltiples conceptos (y un concepto puede ser detectado por múltiples unidades); para el análisis, seleccionamos las etiquetas mejor clasificadas. Para cuantificar la interpretabilidad de una capa, contamos el número de unidades que detectan conceptos únicos, denominado número de detectores únicos.
3. Experimenta
3.1 Evaluación humana de las interpretaciones
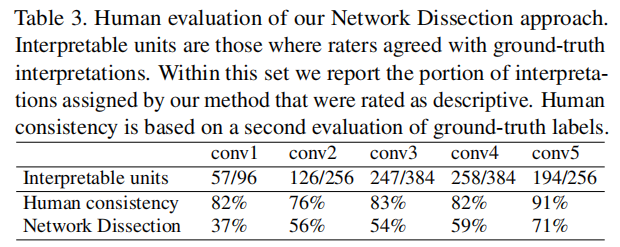
En el nivel más bajo, los conceptos de color y textura de bajo nivel disponibles en Broden solo son lo suficientemente buenos para igualar algunas unidades de buena interpretación. El acuerdo humano también es más alto en conv5, lo que sugiere que los humanos son mejores para reconocer y estar de acuerdo con conceptos visuales de alto nivel, como objetos y partes, en lugar de formas y texturas que aparecen en capas inferiores.
3.2 Medición de la Interpretabilidad Alineada al Eje
Para explorar si la interpretabilidad (Interpretability) de la red está relacionada con la disposición y distribución de las unidades (unidades), el autor realiza una combinación lineal aleatoria (Q en la figura a continuación) para todas las unidades de una determinada capa, es decir, interrumpe el arreglo, y luego se restaura el orden desordenado ( Q − 1 Q^{-1} en la figura a continuaciónq− 1 ), observe el cambio de concepto para obtener el resultado. Específicamente, como se muestra en la siguiente figura:
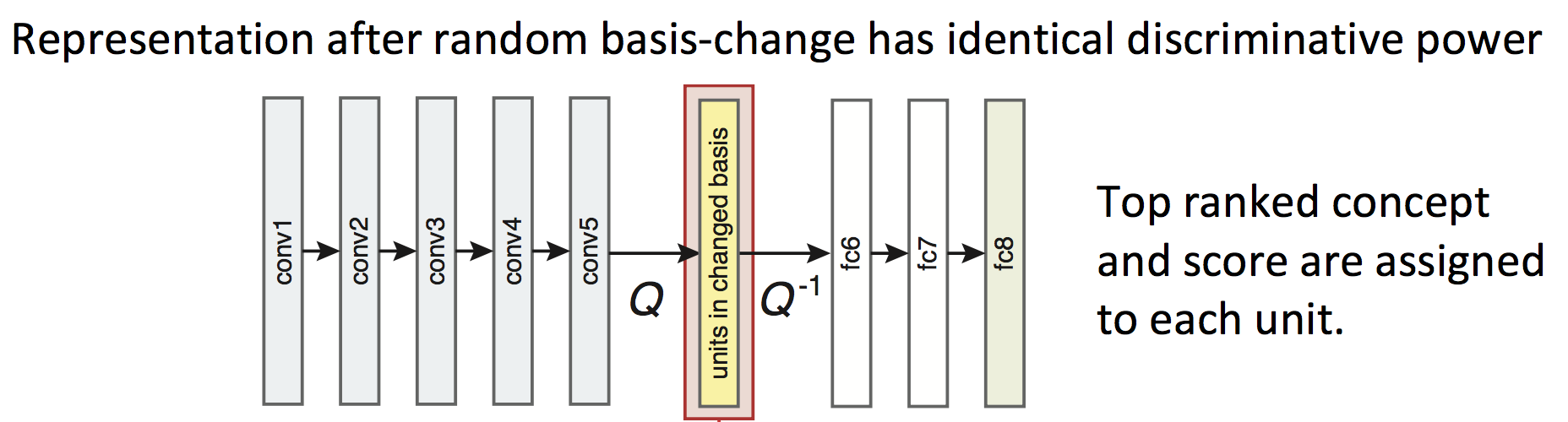
entre ellos, el tamaño de la rotación representa el grado de Q aleatorio, y la interrupción de la disposición de estas unidades no afectará el resultado final de la red y no cambiará la capacidad expresiva de la red ( poder discriminatorio).
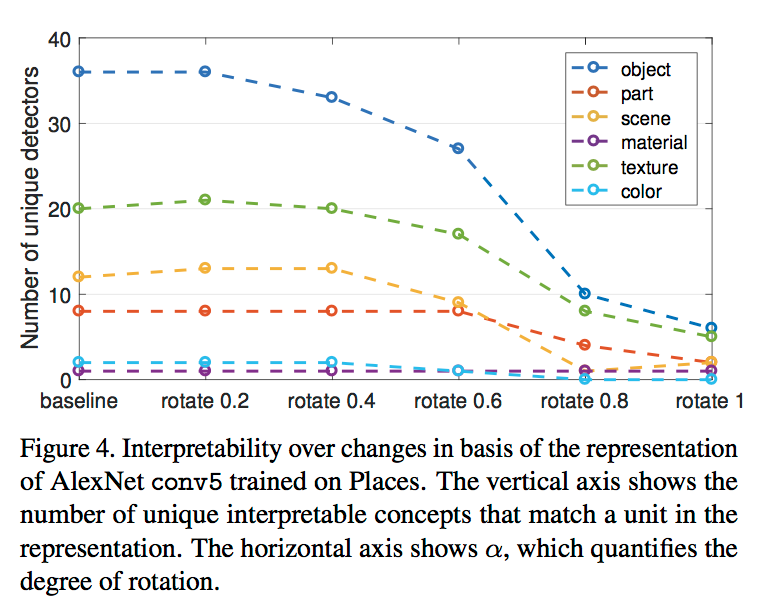
Se puede encontrar a partir de los resultados que a medida que la rotación aumenta gradualmente, el número de detectores únicos comienza a disminuir drásticamente, por lo que la interpretabilidad de la red CNN se ve afectada por el ordenamiento de la unidad.
3.3 Comprender los conceptos de capas
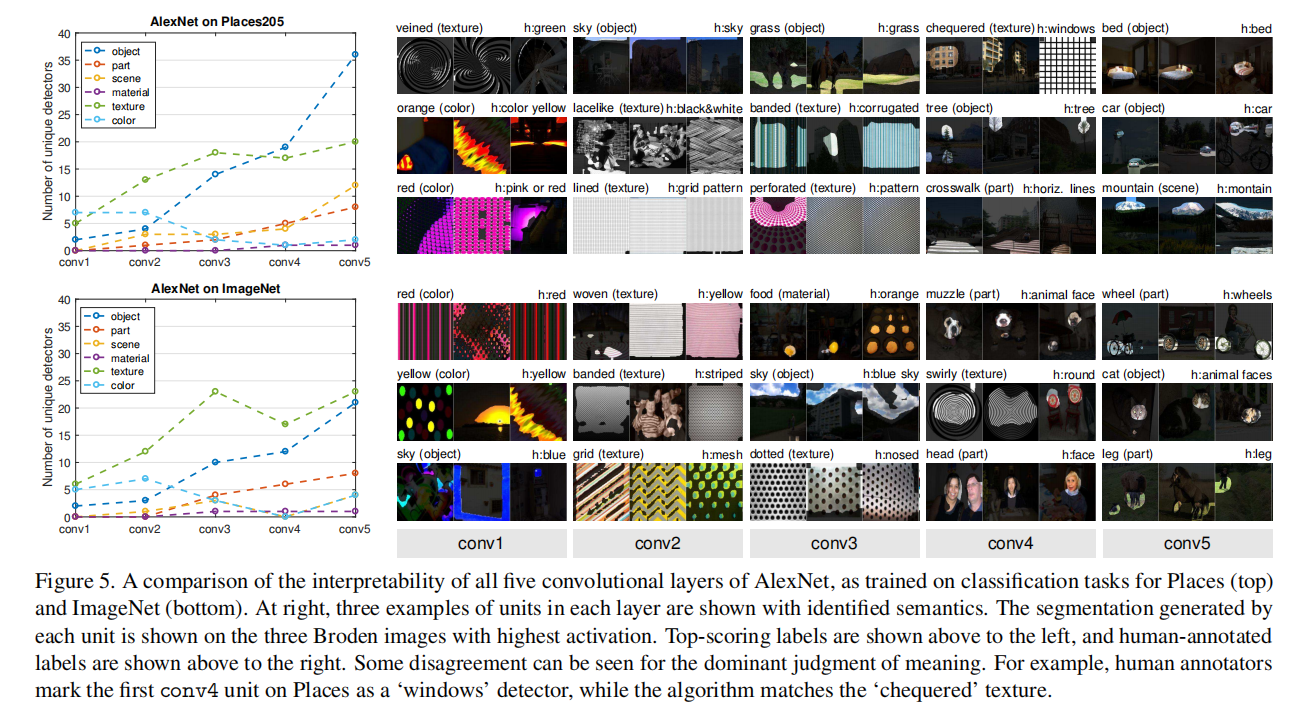
Confirmando la intuición, los conceptos de color y textura son dominantes en los conv1 y conv2 inferiores, mientras que aparecen más detectores de objetos y partes en conv5.
3.4 Arquitectura y supervisión de la red
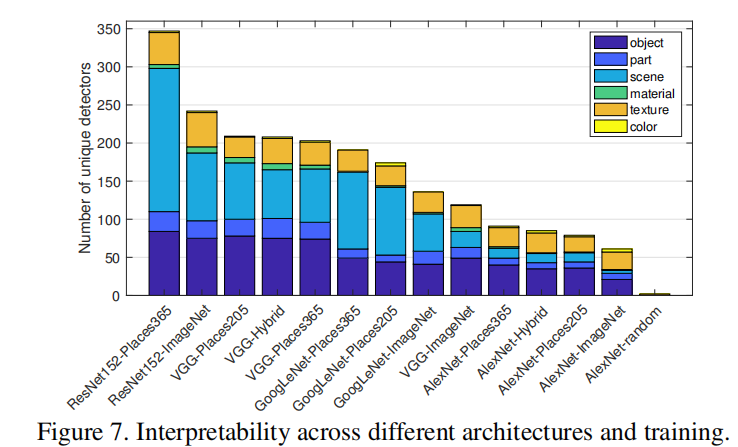
En términos de arquitectura de red, encontramos interpretabilidad ResNet > VGG > GoogLeNet > AlexNet. Las arquitecturas más profundas parecen permitir una mayor interpretabilidad.
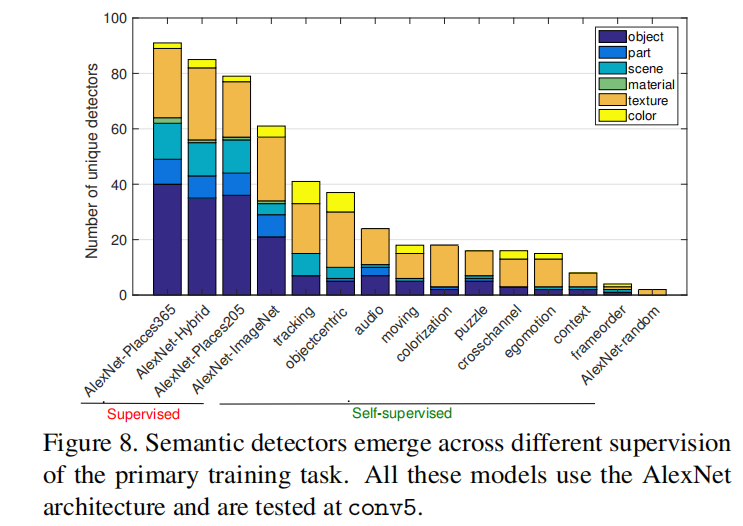
Los modelos autosupervisados crean muchos detectores de textura, pero relativamente pocos detectores de objetos; claramente, las tareas de aprendizaje autosupervisado son mucho menos interpretables que las tareas de aprendizaje supervisado en grandes conjuntos de datos anotados.
3.5 Condiciones de Entrenamiento vs Interpretabilidad
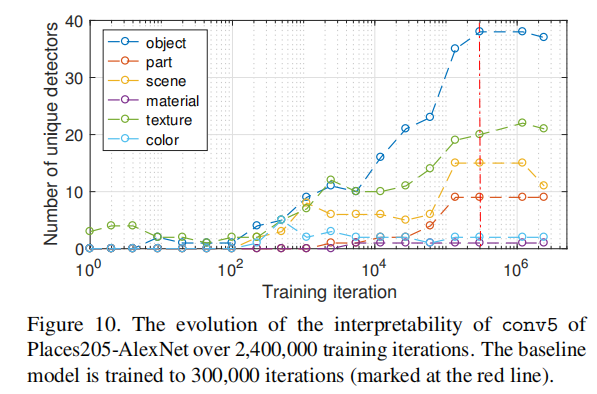
La figura anterior representa la interpretabilidad de las instantáneas del modelo de referencia en diferentes iteraciones de entrenamiento. Podemos ver que los detectores de objetos y partes comienzan a emerger en alrededor de 10,000 iteraciones (256 imágenes por iteración). No encontramos evidencia de transiciones entre diferentes categorías de conceptos durante el entrenamiento. Por ejemplo, las unidades en conv5 no se convierten en detectores de texturas o materiales antes de convertirse en detectores de objetos o partes.
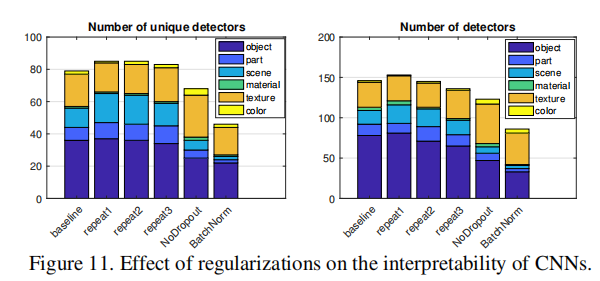
Repetir1, repetir2 y repetir3 en la figura anterior representan tres métodos de inicialización de peso diferentes, y los resultados indican:
- Comparando diferentes inicializaciones aleatorias, los modelos convergen a niveles similares de interpretabilidad en términos de número de detectores únicos y totales;
- Para la red sin Dropout, hay más detectores de texturas, pero menos detectores de objetos;
- La normalización por lotes parece reducir significativamente la interpretabilidad.
3.6 Clasificación vs Interpretabilidad de Redes
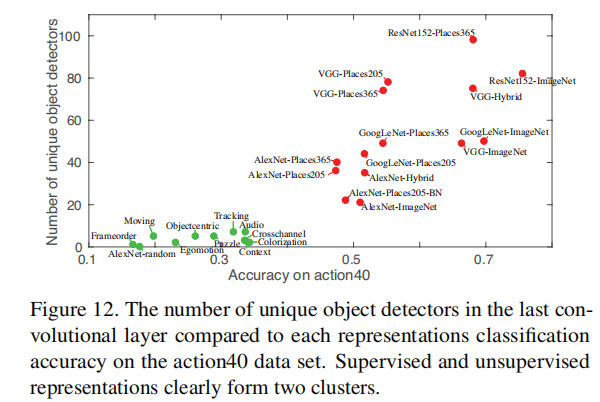
Como puede verse en la figura anterior, existe una correlación positiva entre la capacidad de clasificación y la interpretabilidad.
3.7 Ancho de capa frente a interpretabilidad
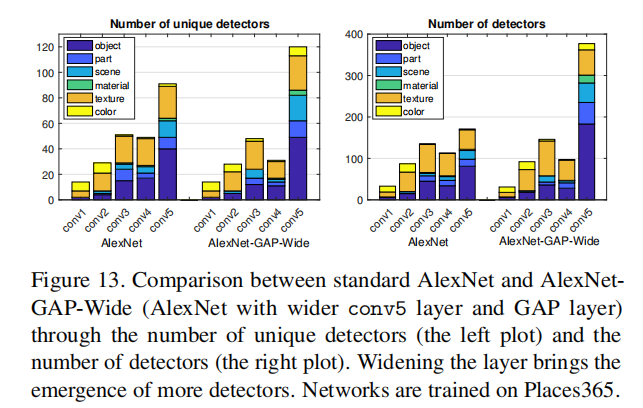
Los núcleos de convolución de conv5 se han aumentado de 256 a 768, lo que tiene una precisión de clasificación similar a la de AlexNet estándar en el conjunto de validación, pero hay muchos detectores y detectores independientes en conv5; también aumentamos la cantidad de unidades de conv5 a 1024 y 2048 , pero el número de conceptos independientes no aumentó significativamente más. Esto puede indicar la capacidad limitada de AlexNet para separar factores explicativos, o puede indicar que limitar el número de conceptos separados ayuda a resolver la tarea principal de clasificación de escenas.
4. Preguntas y respuestas
En las siguientes referencias [2], [3], [4], se registran algunas preguntas respondidas por el propio autor, que pueden ayudar a comprender mejor el artículo.
referencia
[1] Disección de red:
cuantificación de la interpretabilidad de las representaciones visuales profundas
[2] Notas de papel: "Disección de red: cuantificación de la interpretabilidad de las representaciones visuales profundas" - CSDN
[3] Explicación de sus características de caja negra desde la perspectiva de la esencia de las redes neuronales profundas - Zhihu
[ 4] Zhihu God Zhou Bolei: uso de la "disección de redes" para analizar la interpretabilidad de las redes neuronales convolucionales