Colección de conjuntos: una colección que no contiene elementos repetidos. Para ser más precisos, el conjunto no proporciona el par de elementos e1 y e2 que satisface e1.equals (e2) y contiene un elemento nulo. Como su nombre lo indica, esta interfaz imita la abstracción de conjuntos matemáticos.
La interfaz java.util.Set extiende la interfaz de Colección
Características:
1. No está permitido almacenar elementos duplicados
2. No hay índice, ningún método con índice y no se puede utilizar el recorrido de bucle for ordinario.
一 .HashSet
Esta clase implementa la interfaz Set y es compatible con una tabla hash (en realidad, una instancia de HashMap). No garantiza el orden de iteración del conjunto; en particular, no garantiza que el orden seguirá siendo el mismo para siempre. Esta clase permite el uso de elementos nulos.
Esta implementación tampoco es síncrona .
public static void main (String [] args) {
// Polimorfismo
Establecer <Integer> set = new HashSet <> ();
set.add (1);
set.add (3); // secuencia de acceso desordenada e inconsistente
set.add (2);
set.add (1); // Sin elementos duplicados
// No se puede usar un bucle for ordinario, iterativo o foreach
Iterador <Intero> iterador = set.iterator ();
while (iterator.hasNext ()) {
System.out.println (iterator.next ()); // 1 2 3
}
para (Entero i: conjunto) {
System.out.println (i); // 1 2 3
}
}
La estructura del conjunto hash para almacenar los datos (tabla hash)
¿Qué es una tabla hash?
Veamos primero el valor hash (valor hash)
Definición: un número entero decimal, dado aleatoriamente por el sistema (es decir, el valor de la dirección del objeto, una dirección lógica, una dirección simulada, no la dirección física donde se almacenan los datos)
Hay un método en la clase Object para obtener el valor hash del objeto.
public native int hashCode (): Devuelve el valor hash del objeto .
nativo: Significa que el método llama al método del sistema operativo local.
public static void main (String [] args) { Persona persona = nueva Persona (); // La clase Person hereda la clase Object, por lo que puede usar el método hashCode de la clase Object int hash = person.hashCode (); Persona person1 = nueva Persona (); int hash1 = person1.hashCode (); / * Método ToString en el código fuente del objeto: public String toString () { return getClass (). getName () + "@" + Integer.toHexString (hashCode ()); } La segunda mitad de la salida es la representación hexadecimal del valor de la dirección hash * / // Comparado System.out.println (persona); // demo08.Person@1b6d3586 System.out.println (hash); // 460141958 }
Tenga en cuenta que en el método toString del código fuente del objeto, la segunda mitad de @ Printed es el número hexadecimal del valor de la dirección hash.
Pero lo mismo es solo una dirección lógica, no una dirección física.
¡La misma dirección lógica no significa la misma dirección física! El objeto es diferente, la dirección hash también puede ser la misma.
Por ejemplo:
System.out.println (persona == persona1); // falso Cadena str = nueva Cadena ("aaa"); Cadena str1 = nueva Cadena ("aaa"); System.out.println (str.hashCode ()); // 96321 System.out.println (str1.hashCode ()); // 96321// La dirección lógica no es la misma que la dirección física System.out.println (str == str1); // falso // El objeto es diferente, la dirección hash también puede ser la misma System.out.println ("重地" .hashCode ()); // 1179395 System.out.println ("通话" .hashCode ()); // 1179395
Antes de JDK1.8, la capa inferior de la tabla hash se implementaba mediante matriz + lista vinculada, es decir, la lista vinculada se usa para manejar conflictos y las listas vinculadas del mismo valor hash se almacenan en una lista vinculada. Sin embargo, cuando hay muchos elementos en un depósito, es decir, cuando hay muchos elementos con valores hash iguales, la eficiencia de la búsqueda a través del valor clave al mismo tiempo es baja. En JDK1.8, el almacenamiento de la tabla hash se implementa mediante matriz + lista vinculada + árbol rojo-negro. Cuando la longitud de la lista vinculada excede el umbral (8), la lista vinculada se convierte en un árbol rojo-negro, que en gran medida reduce el tiempo de búsqueda.
En pocas palabras, la tabla hash se implementa mediante una matriz + lista vinculada + árbol rojo-negro (JDK1.8 agrega la parte del árbol rojo-negro).
Como se muestra en la explicación:
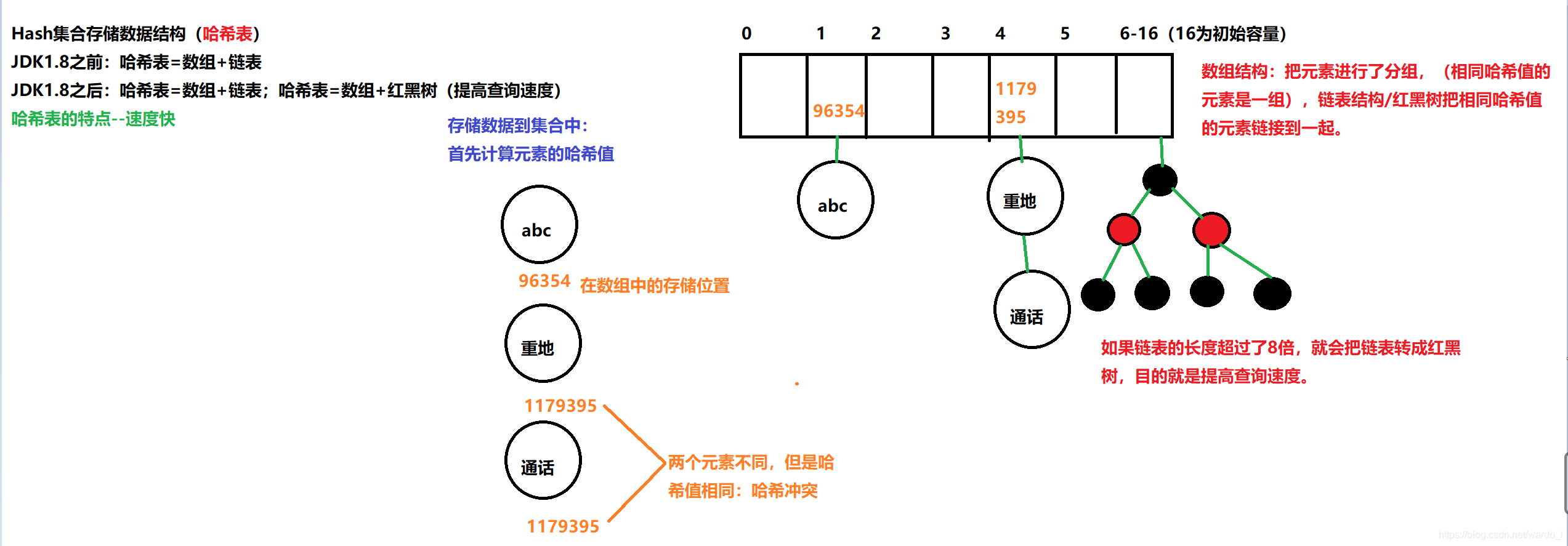
Aprendamos el principio de que HashSet no permite que se repitan elementos:
// Crea una colección HashSet
HashSet <String> hashSet = new HashSet <> ();
// elemento de tienda
Cadena str1 = nueva Cadena ("aaa");
Cadena str2 = nueva Cadena ("aaa");
hashSet.add (str1);
hashSet.add (str2);
hashSet.add ("Tierra pesada");
hashSet.add ("Llamar");
hashSet.add ("aaa");
System.out.println (hashSet); // [aaa, terreno pesado, llamada]

HashSet almacena elementos de tipo personalizados
Almacene datos de tipos Integer y String en HashSet. Estos tipos de datos son todos tipos definidos, y el método hashCode y el método equals se anulan, entonces, ¿cómo almacenar elementos de tipo personalizados?
¡También reescribe el método hashCode y el método equals!
Al almacenar elementos de tipo personalizado para HashSet, debe volver a escribir el método hashCode y el método equals en el objeto y establecer su propio método de comparación para asegurarse de que los objetos de la colección HashSet sean únicos.
Cuando no hay un método de reescritura:
public static void main (String [] args) {
// Crea una colección HashSet para almacenar Person
HashSet <Persona> hashSet = new HashSet <> ();
Persona p1 = nueva Persona ("Yiyang Qianxi");
Persona p2 = nueva Persona ("王俊凯");
Persona p3 = nueva Persona ("Yiyang Qianxi");
hashSet.add (p1);
hashSet.add (p2);
hashSet.add (p3);
System.out.println (p1.hashCode ()); // 460141958
System.out.println (p3.hashCode ()); // 1956725890
System.out.println (p1.equals (p3)); // falso
// Cuando los métodos equals y hashCode no se anulan
// Imprimir [Persona {nombre = 'Yiyang Qianxi'}, Persona {nombre = '王俊凯'}, Persona {nombre = 'Yiyang Qianxi'}]
// No se puede identificar a la misma celebridad
System.out.println (hashSet);
}
Después de reescribir el método:
@Anular
public boolean es igual a (Objeto o) {
si (esto == o) devuelve verdadero;
if (o == null || getClass ()! = o.getClass ()) devuelve falso;
Persona persona = (Persona) o;
return Objects.equals (nombre, persona.nombre);
}
@Anular
public int hashCode () {
return Objects.hash (nombre);
}
System.out.println (p1.hashCode ()); // 806906957
System.out.println (p3.hashCode ()); // 806906957
System.out.println (p1.equals (p3)); // cierto
System.out.println (hashSet); // [Persona {nombre = '王俊凯'}, Persona {nombre = 'Yiyang Qianxi'}]