CONJUNTO
caracteristicas:
Los elementos son únicos, ordenados y eficientes en la inserción.
Funciones básicas:
begin () - devuelve un iterador al primer elemento
clear () - borra todos los elementos
count (): devuelve el número de elementos de un valor determinado
vacío (): si la colección está vacía, devuelve verdadero
end (): devuelve un iterador al último elemento
equal_range (): devuelve dos iteradores de los límites superior e inferior iguales al valor dado en el conjunto
borrar () - eliminar elementos en el conjunto
find (): devuelve un iterador que apunta al elemento encontrado
get_allocator () - devuelve el asignador de la colección
insert (): inserta un elemento en la colección
lower_bound () - devuelve un iterador al primer elemento mayor que (o igual a) un cierto valor
key_comp (): devuelve una función para comparar valores entre elementos
max_size (): devuelve el límite máximo de elementos que puede contener la colección
rbegin (): devuelve un iterador inverso que apunta al último elemento de la colección
rend (): devuelve un iterador inverso que apunta al primer elemento de la colección
size () - el número de elementos en la colección
swap () - intercambia dos variables de colección
upper_bound (): devuelve un iterador de elementos mayores que un cierto valor
value_comp (): devuelve una función utilizada para comparar valores entre elementos
Comparar:
(1) Si el elemento es una estructura, puede escribir directamente la función de comparación en la estructura.
(2) El elemento no es una estructura y la función de comparación está personalizada.
#include<iostream>
#include<cstdio>
#include<cstdlib>
#include<set>
#include<cctype>
#include<sstream>
using namespace std;
struct example1{
//结构体重载‘<’,使本身有序。
int x;
int y;
bool operator < (const example1 &a)const
{
return a.x<x;//从大到小排列
}
};
struct example2{
int x;
int y;
};
struct cmp//自定义比较函数myComp,重载“()”操作符
{
bool operator()(const example2 &a,const example2 &b)
{
return a.x-b.x>0;//从大到小排列
}
};
int main()
{
set<example1>set1;
example1 ex1[5]={
{
5,1},{
3,1},{
4,1},{
1,1},{
2,1}};
for(int i=0;i<5;i++)
set1.insert(ex1[i]);
set<example1>::iterator it;
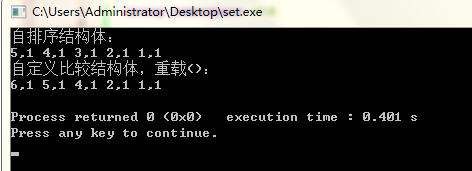
cout<<"自排序结构体:"<<endl;
for(it=set1.begin();it!=set1.end();it++)
cout<<(*it).x<<","<<(*it).y<<" ";
cout<<endl;
set<example2,cmp>set2;
example2 ex2[5]={
{
5,1},{
6,1},{
4,1},{
1,1},{
2,1}};
for(int i=0;i<5;i++)
set2.insert(ex2[i]);
set<example2,cmp>::iterator it2;
cout<<"自定义比较结构体,重载():"<<endl;
for(it2=set2.begin();it2!=set2.end();it2++)
cout<<(*it2).x<<","<<(*it2).y<<" ";
cout<<endl;
return 0;
}
Salida:
Ejemplo: primer diccionario de Andy UVA-10815
Descripción
Andy, de 8 años, tiene un sueño: quiere producir su propio diccionario. Esta no es una tarea fácil para él, ya que la cantidad de palabras que conoce no es suficiente. En lugar de pensar en todas las palabras él mismo, tiene una idea brillante. De su estantería elegía uno de sus libros de cuentos favoritos, del cual copiaba todas las palabras distintas. ¡Al ordenar las palabras en orden alfabético, ya está! Por supuesto, es un trabajo que consume mucho tiempo, y aquí es donde un programa de computadora es útil. Se le pide que escriba un programa que enumere todas las palabras diferentes en el texto de entrada. En este problema, una palabra se define como una secuencia consecutiva de alfabetos, en mayúsculas y / o minúsculas. También se deben considerar las palabras con una sola letra. Además, su programa debe distinguir entre mayúsculas y minúsculas. Por ejemplo, palabras como "Apple",
Entrada
El archivo de entrada es un texto con no más de 5000 líneas. Una línea de entrada tiene como máximo 200 caracteres. La entrada termina con EOF.
El archivo de entrada no tiene más de 5000 líneas de texto. La línea de entrada puede contener hasta 200 caracteres. EOF termina la entrada.
Salida
Su salida debe dar una lista de diferentes palabras que aparecen en el texto de entrada, una en una línea. Todas las palabras deben estar en minúsculas, ordenadas en orden alfabético. Puede estar seguro de que el número de palabras distintas en el texto no supera las 5000.
Salida Proporcione una lista de las diferentes palabras que aparecen en el texto de entrada, una palabra en una línea. Todas estas palabras deben estar en minúsculas, en orden alfabético. El número de palabras diferentes en el archivo no supera las 5000.
Entrada de muestra
Aventuras en Disneyland
Dos rubias iban a Disneylandia cuando llegaron a una bifurcación en el
la carretera. El letrero decía: "Disneyland se fue".
Entonces se fueron a casa.
Salida de muestra
un
aventuras rubias
vino
disneyland
tenedor
yendo
casa
en
izquierda
leer
la carretera
firmar
entonces
los
ellos
a
dos
fuimos
fueron
cuando
Código AC:
#include<iostream>
#include<cstdio>
#include<cstdlib>
#include<set>
#include<cctype>
#include<sstream>
using namespace std;
int main()
{
ios::sync_with_stdio(false);
string s,buf;
set<string>dict;
while(cin>>s)
{
for(int i=0;i<s.length();i++)
{
if(!isalpha(s[i])) s[i]=' ';//把非字母字符转化空格
else s[i]=tolower(s[i]);//其它字母转化为小写字母
}
stringstream ss(s);
//利用stringstream将带有空格的字符串的拆分成一个个字符,类似于java的split()
while(ss>>buf) dict.insert(buf);
}
set<string>::iterator it;
for(it=dict.begin();it!=dict.end();it++)
cout<<*it<<endl;
return 0;
}
Nota: Hay muchas funciones útiles en #include, similares a isalpha () // ¿Es una letra, tolower (),
toupper (), etc. Para obtener más detalles, consulte: archivo de encabezado cctype
seguido de #include input y output stream: úselo Realiza la eliminación de espacios y también puede realizar la conversión entre varios tipos de datos en C ++. Para obtener más información, consulte: archivo de encabezado sstream