Configuración del entorno
Python 3.6
scikit-image 0.17.2
numpy 1.19.0
opencv-python 3.4.2.16
opencv-contrib-python 3.4.2.16
Progreso del programa
Leer datos de entrenamiento
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range = 45,
width_shift_range = 0.2,
height_shift_range = 0.2,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip=True)
train_gen = train_datagen.flow_from_directory("data/train",
target_size = (240, 240),
batch_size = 8,
class_mode="categorical")
ImageDataGenerator
Es posible mejorar los datos;
enlace de referencia: Keras ImageDataGenerator
- reescalar: normalizar el valor de 0 a 255 a un valor entre 0 y 1;
- rango de rotación: entero, el ángulo de rotación aleatorio de la imagen, el valor es [0, 180], creo que el valor predeterminado es generalmente en sentido antihorario;
- width_shift_range: número de punto flotante, una cierta proporción, el rango de desplazamiento horizontal aleatorio de la imagen, el valor es [0, 1];
- height_shift_range: número de punto flotante, una cierta proporción, la amplitud de la traducción vertical aleatoria de la imagen, el valor es [0, 1];
- shear_range: número de punto flotante, que indica el grado de transformación de corte (en sentido antihorario);
- zoom_range: número de punto flotante, que indica el grado de zoom aleatorio, o una lista de la forma [inferior, superior];
- horizontal_flip: valor booleano, volteo horizontal aleatorio;
Clasifique automáticamente las imágenes según las carpetas:
flow_from_directory
Puede numerarse según carpetas y clasificarse automáticamente;

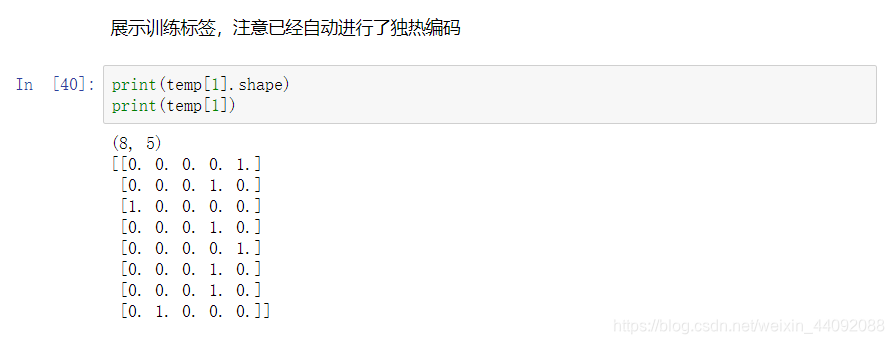
ver los datos de entrenamiento en un lote, hay 8 imágenes en un lote, temp [0] es la imagen, temp [1] es la etiqueta; el


rango de datos es 0 ~ 1 : uno-
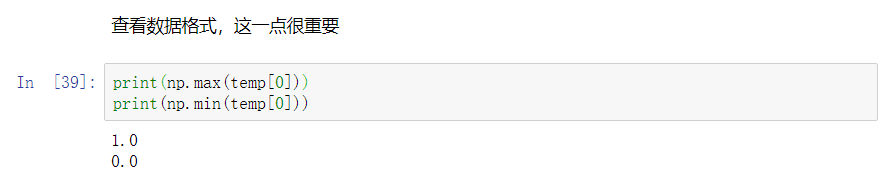
codificación en caliente completada:

Cargar modelos previamente entrenados en línea
VGG = keras.applications.vgg16.VGG16(weights="imagenet", include_top=False, input_shape=[240, 240, 3])

O cargue archivos de acceso local:
from keras.models import load_model
VGG = load_model("model/VGG_Pretrained.h5")
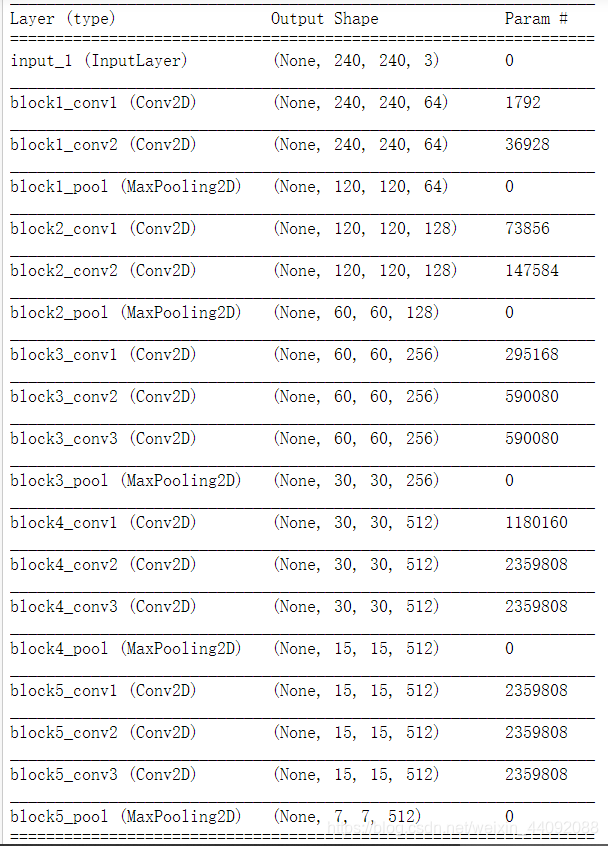
Ver información del modelo:

Agrega un clasificador al final del modelo.
from keras.layers import Dense, Flatten
x = VGG.layers[-1].output
x = Flatten()(x)
x = Dense(64, activation="sigmoid")(x)
predictions=Dense(5, activation="softmax")(x)
model = keras.Model(inputs=VGG.inputs, outputs=predictions)
Agregue un clasificador detrás del modelo. Tenga en cuenta que el número de neuronas en la capa de salida debe ser el mismo que el de la etiqueta. Se debe agregar Flatten; de lo contrario, la capa densa no puede aceptar la entrada de matriz; en
términos simples, se agregan dos capas de neuronas. El más problemático es el Connect the original modelos;
for layer in model.layers[:-2]:
layer.trainable=False
Entrena solo las dos últimas capas;

Definir optimizador
adam = Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-8)
model.compile(loss="categorical_crossentropy", optimizer=adam, metrics=["accuracy"])
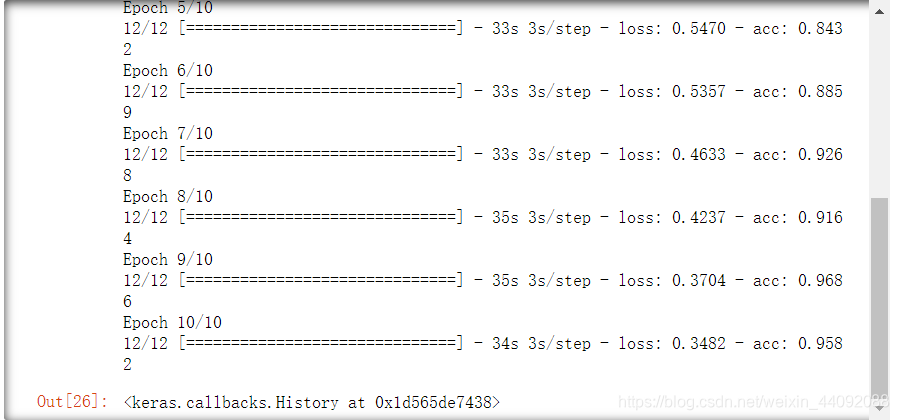
Modelo de entrenamiento
model.fit_generator(train_gen, steps_per_epoch=12, epochs=10)
Guarde el modelo entrenado:

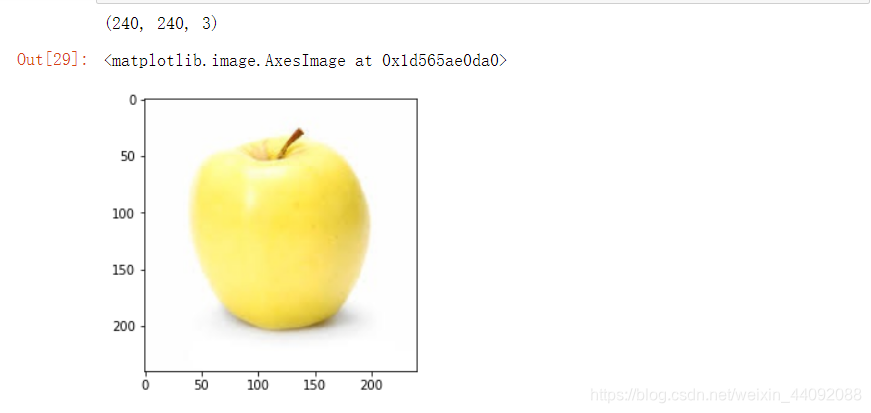
Cargar datos de prueba
import skimage.io as io
import skimage.transform as transform
img = io.imread("data/test/3.jpg")
img = img/255
img = transform.resize(img, output_shape=[240, 240])
print(img.shape)
plt.imshow(img)
empezar a probar:
indices = {'紫葡萄': 0, '红苹果': 1, '绿葡萄': 2, '黄苹果': 3, '黄香蕉': 4}
output = model.predict(img.reshape([1, 240, 240, 3]))
print(output)
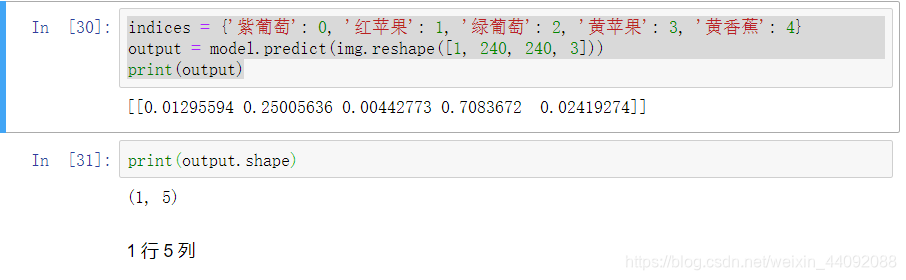
Resultado de salida
output_r tiene dos números, que indican respectivamente cuántas filas y cuántas columnas es el resultado de la predicción:

Código fuente completo
Sin información de salida redundante
# 完整版
import numpy as np
import keras
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.optimizers import Adam
from keras.utils.np_utils import to_categorical
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range = 45,
width_shift_range = 0.2,
height_shift_range = 0.2,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip=True)
train_gen = train_datagen.flow_from_directory("data/train",
target_size = (240, 240),
batch_size = 8,
class_mode="categorical")
# 从网上下载预先存取好的模型
VGG = keras.applications.vgg16.VGG16(weights="imagenet", include_top=False, input_shape=[240, 240, 3])
# 或者直接从本地导入
# from keras.models import load_model
# VGG = load_model("model/VGG_Pretrained.h5")
# 在原模型末尾加入分类器
from keras.layers import Dense, Flatten
x = VGG.layers[-1].output
x = Flatten()(x)
x = Dense(64, activation="sigmoid")(x)
predictions=Dense(5, activation="softmax")(x)
model = keras.Model(inputs=VGG.inputs, outputs=predictions)
# 设置为只需要训练最后新加入的两层神经元
for layer in model.layers[:-2]:
layer.trainable=False
# 定义优化器
adam = Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-8)
model.compile(loss="categorical_crossentropy", optimizer=adam, metrics=["accuracy"])
# 训练模型
model.fit_generator(train_gen, steps_per_epoch=12, epochs=10)
# 载入测试数据
import skimage.io as io
import skimage.transform as transform
img = io.imread("data/test/3.jpg")
img = img/255
img = transform.resize(img, output_shape=[240, 240])
# print(img.shape) # 查看图片信息
# plt.imshow(img)
# 结果展示
indices = {'紫葡萄': 0, '红苹果': 1, '绿葡萄': 2, '黄苹果': 3, '黄香蕉': 4}
output = model.predict(img.reshape([1, 240, 240, 3]))
# print(output)
# 使得结果更加清晰
output_r = np.where(output==np.max(output))
print(np.max(output_r[1])) # 表示预测结果的列编号