Resumen de texto completo
MobileNetV3 es una red obtenida mediante tecnología de búsqueda automática y se puede utilizar en la CPU del terminal móvil. MobileNetV3 no propuso un nuevo bloque, pero propuso una nueva función de activación y analizó el equilibrio entre precisión y latencia.
El comienzo del artículo es presentar cómo utilizar la tecnología de búsqueda automática para diseñar la estructura de la red. En este artículo se proponen dos arquitecturas de red: MobileNetV3-Large y MobileNetV3-Small , que se pueden aplicar a tareas de clasificación, detección de objetos y segmentación semántica. Para las tareas de segmentación semántica, se propone un nuevo decodificador: LR-ASPP (Lite Reduced Atrous Spatial Pyramid Pooling).
En general, MobileNetV3 es una combinación de aplicaciones, representada por MobileNetV2 + SE (r = 4) + hard-swish + global avg pooling front .
Bloque MoblieNetV3
El bloque de MobileNetV3 se muestra en la siguiente figura.

Se puede ver que el bloque de MobileNetV3 se compone de dos partes: (1) convolución profunda separable con estructura residual inversa; (2) aplicación de compresión y excitación.
Se puede observar que la estructura SE se aplica después de la profundidad, no después de la puntualidad.
Por lo tanto, el diseño de módulo de MobileNetV3 se compone principalmente de tres diseños de módulo:
- La convolución de profundidad separable introducida por MobileNetV1;
- El residual invertido con cuello de botella lineal introducido por MobileNetV2 (el residual invertido con cuello de botella lineal);
- Un modelo de atención a la luz basado en la estructura de excitación y compresión introducido por MNasNet;
Mejora de la red
Rediseño de capas caras
El autor obtuvo una red inicial mediante la búsqueda de arquitectura, pero el autor encontró que la primera parte de la red y la última parte de la red son más "caras" que las otras capas (la capa anterior tiene una resolución más alta). Por lo tanto, el autor realizó algunas modificaciones en la red manteniendo la precisión para reducir el tiempo de ejecución.
La primera es preceder a la capa Global Avg Pooling con un bloque y usar una convolución 1 * 1 para calcular las características . Esta operación redujo 7 ms 7 ms7 m s (ocupa11% 11 \%1 1 % ) tiempo de ejecución y30 millones 30 millones. 3 0 m I L L I O n- S MAdds, y sustancialmente sin pérdida de precisión. El cambio se muestra en la siguiente figura: La parte superior de la imagen es la última parte del MobileNetV2 original y la parte inferior es la última parte del MobileNetV3 modificado.

En la detección de bordes (la primera operación de convolución después de ingresar la imagen), las redes de luz actuales a menudo usan convolución 3 * 3 con 32 núcleos de convolución. El autor utiliza una función de activación diferente en MobileNetV3 para reemplazar RELU y swish de uso común, y reduce el número de núcleos de convolución de 32 a 16, mientras logra la misma precisión, reduciendo el tiempo de ejecución de 2ms.
Función de activación
使用swish swishs w i s h función de activación en lugar deRe LU ReLULa función de activación R e L U traerá unagranmejora de precisión, pero debido asigmoide sigmoideLa existencia de la función s i g m o i d ,swish swishLa función s w i s h consumirá más tiempo de ejecución.
swish [x] = x ∗ σ (x) swish [x] = x * \ sigma (x)s w i s h [ x ]=X∗σ ( x )
sigmoide sigmoideaLa función s i g m o i d puede usar la función lineal por partesR e LU 6 (x + 3) 6 \ frac {ReLU6 (x + 3)} {6}6ReLU6(x+3)En cambio, tan swish swishs w i s h puede obtener su función de realización correspondiente: h - swish [x] = x ∗ R e LU 6 (x + 3) 6 h-swish [x] = x * \ frac {ReLU6 (x + 3)} {6}h-s w i s h [ x ]=X∗6ReLU6(x+3 )
El uso de la función lineal por partes tiene dos ventajas: (1) sigmoide sigmoideaLa función s i g m o i d llevará más tiempo en la implementación de la terminal; (2)sigmoide sigmoideaLa función s i g m o i d tiene diferentes implementaciones. En la cuantificación, diferentes métodos de implementación pueden causar un desajuste de pérdida de cuantificación.
La siguiente figura muestra que esta aproximación es muy efectiva:
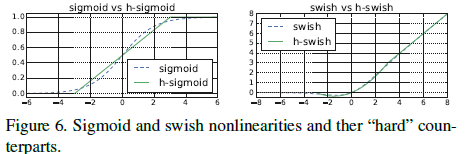
El autor descubrió inesperadamente a través de experimentos que los beneficios de elegir swish como función de activación se obtienen utilizando swish en la capa de red más profunda. Por lo tanto, en el modelo de este artículo, el autor usa hard-swish como función de activación en la segunda mitad de la red.
Diseño de red
El diseño de red de MobileNetV3-Large:

Diseño de red de MobileNetV3-Small:

experimentar
clasificación
Precisión, cantidad de cálculo, cantidad de parámetros principales en la clasificación de ImageNet y resultados de experimentos en teléfonos móviles de la serie Pixel:


Comparación de MobileNetV3 Large / Small y MobileNetV2:

Puede verse en la curva que si desea utilizar una red más pequeña que MobileNetV3-Large, MobileNetV3-small será mejor. Porque el rendimiento de MobileNetV3-Large cuando el número de núcleos de convolución disminuye no es tan bueno como MobileNetV3-Small. El efecto de MobileNetV3-Small es mejor que MobileNetV2.
Detectar
Cuando MobileNetV3 crea el marco de detección, divide a la mitad los canales de todas las capas entre la última capa con stride = 16 y la última capa con stride = 32. La razón es que solo hay 80 clases en el conjunto de datos COCO y no hay necesidad de una red tan grande como la clase 1000 ImageNet.
La precisión del algoritmo de detección de objetivos SSDLite en MS COCO:

Segmentación semántica
Basado en MobieNetV3, se diseña un nuevo modelo ligero de segmentación semántica Lite R-ASPP:


Comparación de rendimiento


Resumen de resultados experimentales
- En la tarea de clasificación de ImageNet, la precisión de MobileNetV3-Large aumenta en un 3,2% en comparación con MobileNetV2, y el retraso se reduce en un 15%.
- En la tarea de detección que utiliza SSDlite en el conjunto de datos COCO, la precisión de detección de MobileNetV3-large es aproximadamente la misma que la de MobileNetV2, pero la velocidad aumenta en un 25%.
- En la tarea de segmentación semántica de paisajes urbanos, el modelo de nuevo diseño MobileNetV3-Large LR-ASPP tiene una precisión de segmentación similar a MobileNetV2 R-ASPP, pero es un 30% más rápido.