Como sugiere el nombre, el tokenizador sirve para segmentar texto. Actualmente, es nos proporciona estándar (bueno para idiomas occidentales), icu (para el sudeste asiático y otras regiones), ik (chino) y algunos menos utilizados como Letter Tokenizer (para segmentación sin caracteres), analizador de espacios en blanco (para cada uno al encontrar la segmentación de espacios en blanco).
Tipo de tokenizador:
- Estándar: método de segmentación de un solo carácter, un carácter se divide en una palabra. ( es el tokenizador predeterminado )
- CJKAnalyzer: método de segmentación binaria, que trata dos caracteres adyacentes como una palabra.
- SmartChineseAnalyzer: Buen soporte para chino, pero escasa escalabilidad, y no es fácil manejar sinónimos extendidos y palabras vacías.
- paoding`: Paoding Jie Niu word segmenter, sin actualización continua, solo es compatible con lucene3.0.
- mmseg4`: es compatible con Lucene 4.10 y se actualiza continuamente en github, utilizando el algoritmo mmseg.
- Tokenizador de espacios en blanco: elimina espacios, no admite chino y no realiza ningún otro procesamiento estandarizado en la unidad de vocabulario generada.
- tokenizador de idioma: un tokenizador para un idioma específico, el chino no es compatible.
- IK-analyzer: el segmentador de palabras chinas más popular .
Instalar IK-analyzer
- Descarga ik 中 文字 分 器
- Descomprima en el directorio / usr / share / elasticsearch / plugins / ik
unzip elasticsearch-analysis-ik-7.9.3.zip -d /data/local/elasticsearch/9200/plugins/ik
3. Reinicie elasticsearch
4. Pruebe el efecto de segmentación de palabras
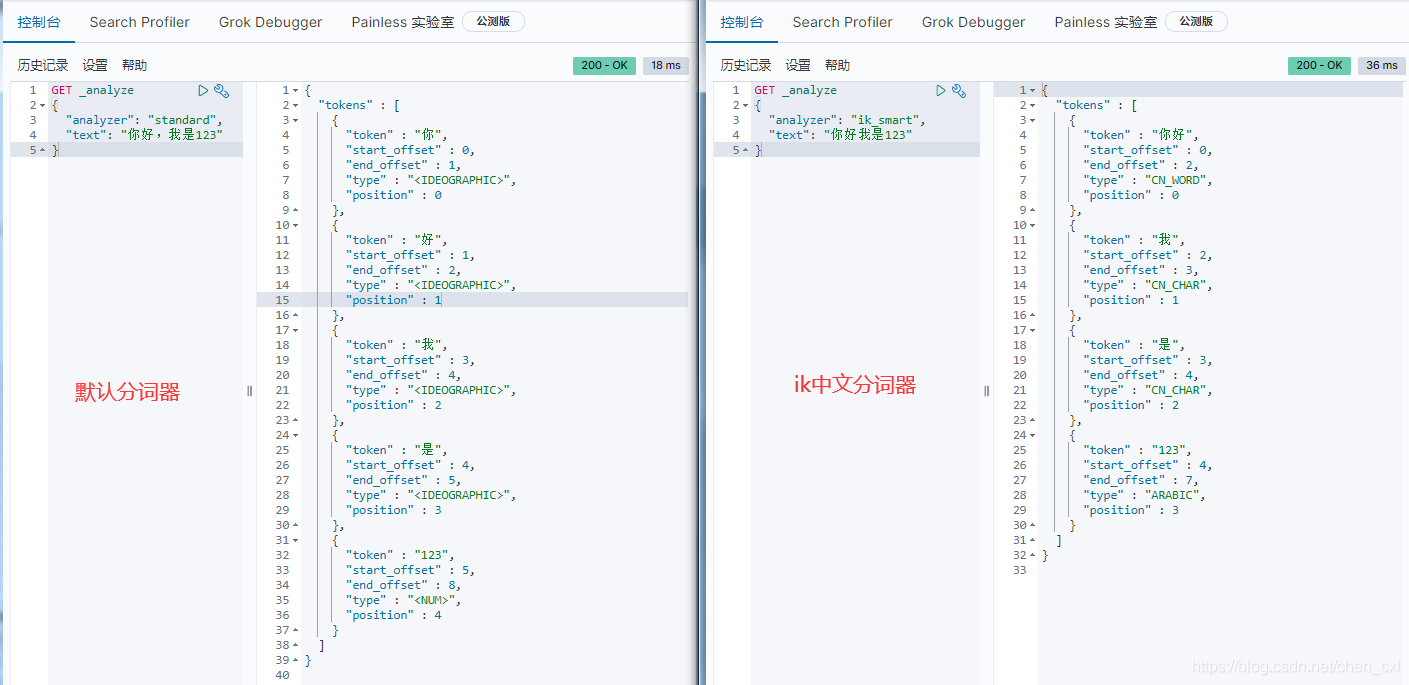
Utilice el analizador de IK
Use ik_max_word (detallado) al indexar
#建立索引时使用ik_max_word分词
PUT _template/request_log
{
"index": {
"refresh_interval": "5s",
"analysis": {
"analyzer": {
"ik": {
"tokenizer": "ik_max_word"
}
}
}
}
}
Configurar el tokenizador para un solo campo
"字段名称": {
"type": "text",
"analyzer": "ik_max_word"
}
Utilice ik_smart (de grano grueso) al buscar
GET /request_log-app-2020.06.08/_search
{
"query": {
"match_phrase" : {
"operation" : {
"query" : "发货",
"analyzer" : "ik_smart"
}
}
}
}
Comandos relacionados
#测试分词结果
GET _analyze
{
"analyzer": "ik_smart", //指定分词器
"text": ["要测试的字符串"]
}
#获取document中的某个field内的各个term的统计信息。
GET /索引/_termvectors/文档id
{
"fields":["字段1"]
}