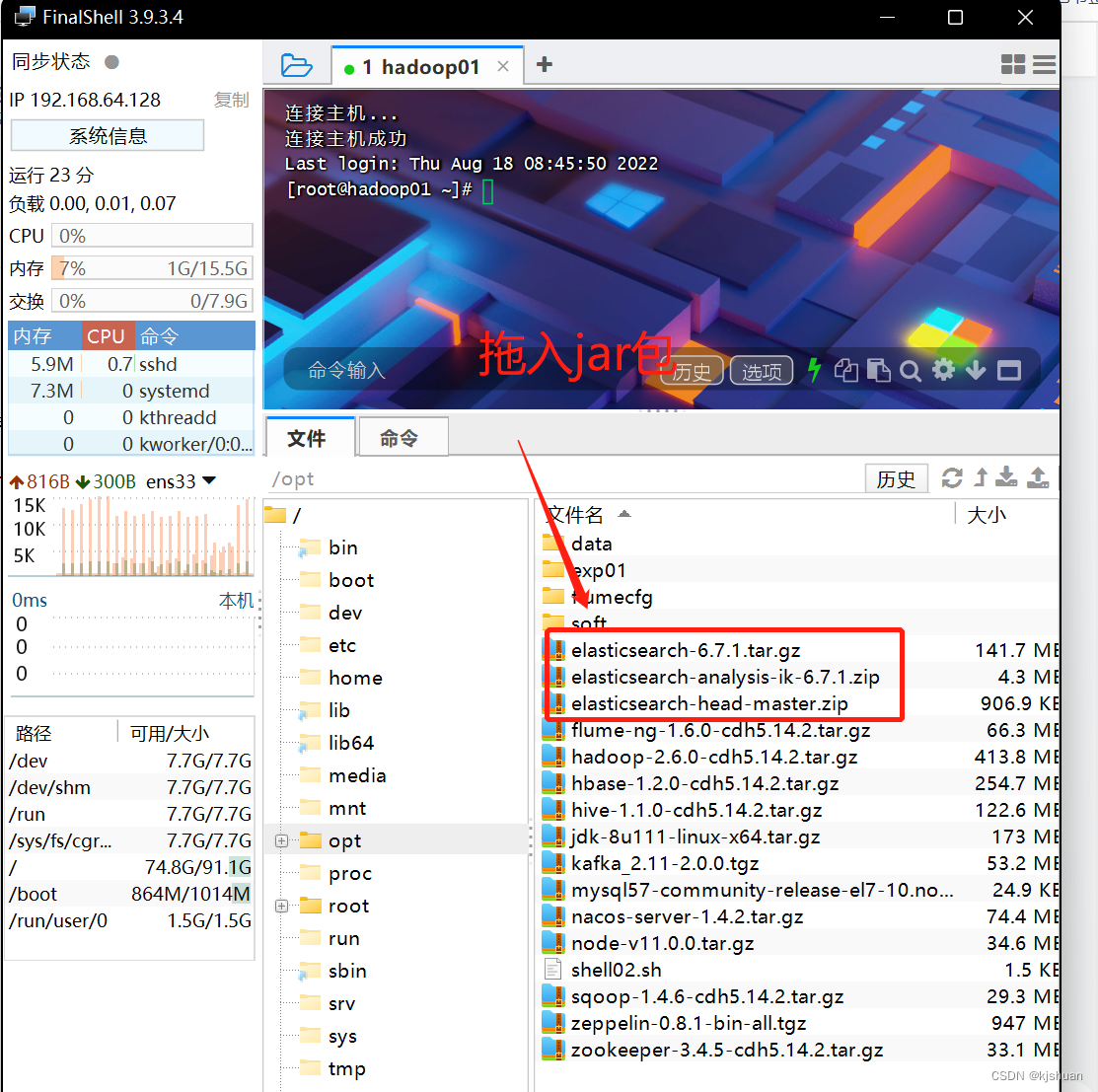
Pasos 1 de instalación distribuida de Elasticsearch
# Considere la necesidad de instalar elasticsearch-head para visualización web, así que primero instale nodejs, principalmente usando npm wget https://npm.taobao.org/mirrors/node/v11.0.0/node-v11.0.0.tar.gz tar - zxvf node-v11.0.0.tar.gz mv node-v11.0.0 /opt/soft/ cd /opt/soft/node-v11.0.0 yum install gcc gcc-c++ ./configure make hacer instalar nodo -v
Paso 2
cd /opt/ tar -zxf elasticsearch-6.7.1.tar.gz mv elasticsearch-6.7.1 /opt/soft/ cd /opt/soft/es671/config/ vim elasticsearch.yml ========= ===== #Modificar cluster.name: es-app node.name: es-1 network.host: 192.168.64.128 http.port: 9200 #Insertar http.cors.enabled: true http.cors.allow-origin: "*" ============== :wq #Crear un usuario useradd cm passwd cm ok ok su cm su vim /etc/security/limits.conf #Agregar la pregunta 1 al final de el sistema de archivos Max El número de archivos es demasiado bajo cm soft nofile 65536 cm hard nofile 131072 cm soft nproc 4096 cm hard nproc 4096 vim /etc/sysctl.conf #Agregar al final del archivo Problema 2 La memoria virtual es demasiado baja vm.max_map_count=655360 #Activar sysctl -p #Autorizar chown cm:cm -R /opt/soft/es671/ su cm cd. . cd /opt/soft/es671/bin/ ls ./elasticsearch #Vista del navegador 192.168.64.128:9200
Paso 3 (abre una nueva ventana)
cd /opt/ #Instalar zip yum install -y descomprimir zip #Descomprimir elasticsearch-head-master.zip mv elasticsearch-head-master /opt/soft/eshead cd /opt/soft/eshead/ #Dile al sistema que importe el paquete Finalmente, hay un archivo que no se puede encontrar y se informa un error (no es importante y no afecta el desarrollo) npm install #Abrir una nueva ventana cd /opt/soft/eshead npm run start #Acceso al navegador http: //192.168.64.128:9100
Búsqueda elástica02
ruidoso
Se utiliza para ubicar un determinado dato en la tabla de datos. Es único y no cambiará.
Rownum
Indica consultar la posición de un determinado registro en todo el conjunto de resultados. El número de fila correspondiente a diferentes condiciones de consulta para el mismo registro es diferente, pero el ID de fila no cambiará.

Iniciar ES
Configurar variables de entorno vim /etc/profile =========================== #Elasticsearch export Elasticsearch_Home=/opt/soft/es671 export PATH=$ RUTA:$Elasticsearch_Home/bin =========================== fuente /etc/profile su cm cd /opt/soft/es671/bin . /elasticsearch #Iniciar. /elasticsearch -d #Detener su cd /opt/soft/eshead npm run start 192.168.64.128:9100 #Acceso al navegador #Si desea instalar un clúster, recuerde vim elasticsearch.yml node.name: es- 1 necesita diferente

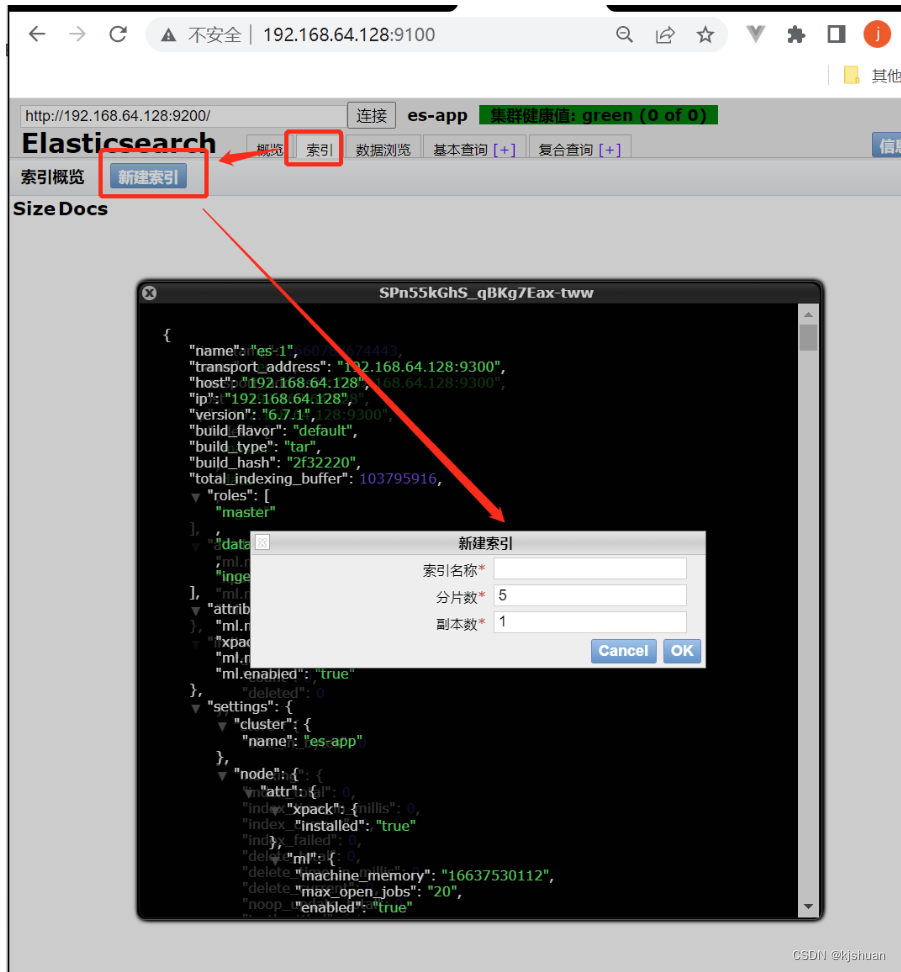
es crea índice
Método 1
poner indexTest001 poner /my_test_index_004
Método 2
es datos básicos de operación
1Crear tabla

2. Agregar datos

3. Modificar datos

4. Eliminar datos

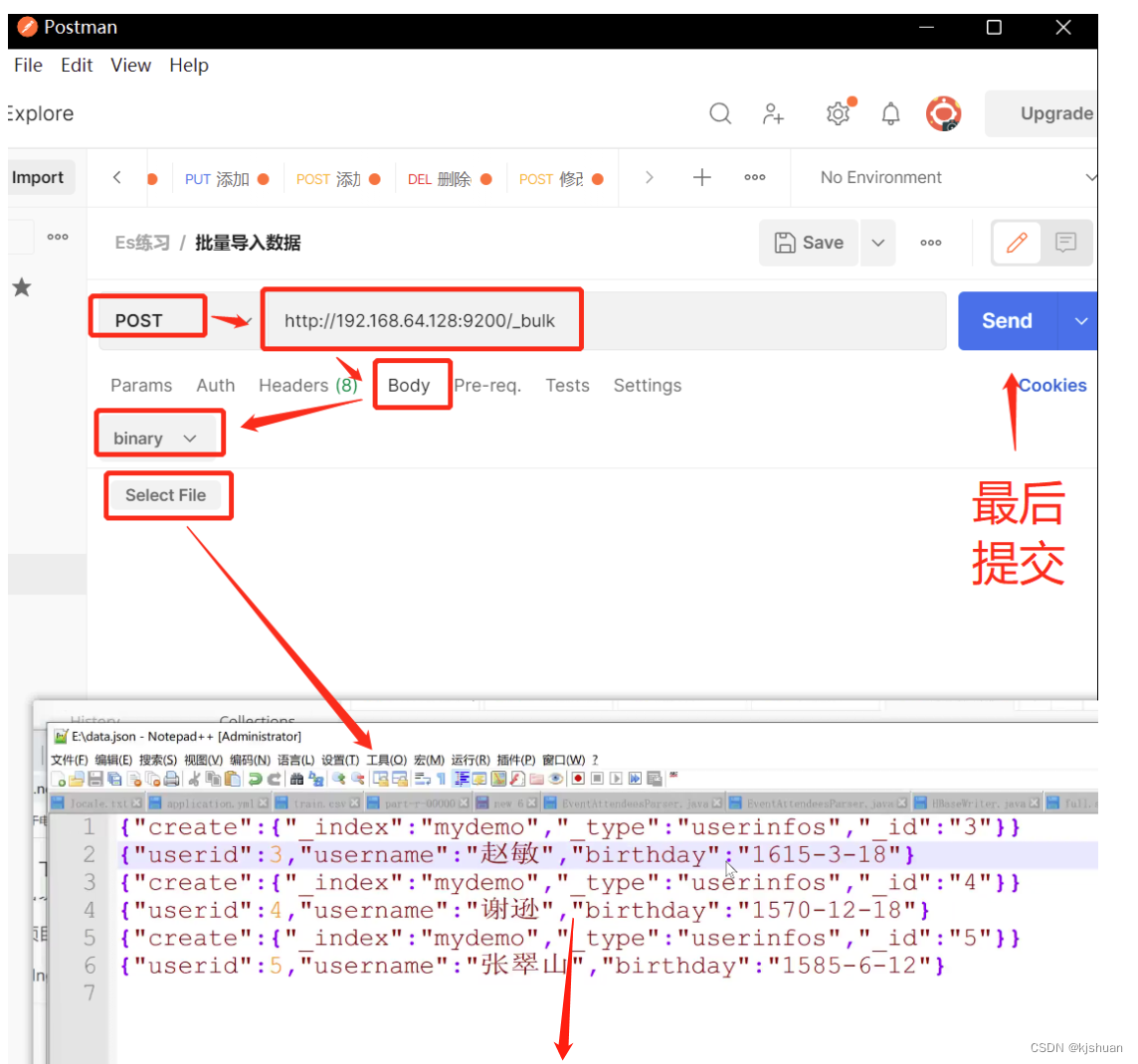
5. Agregue datos en lotes

6. Consulta por identificación

7. Consultar todo

8. consulta difusa


9. Consulta de concordancia de frase

10. Coincidencia de prefijos de frases

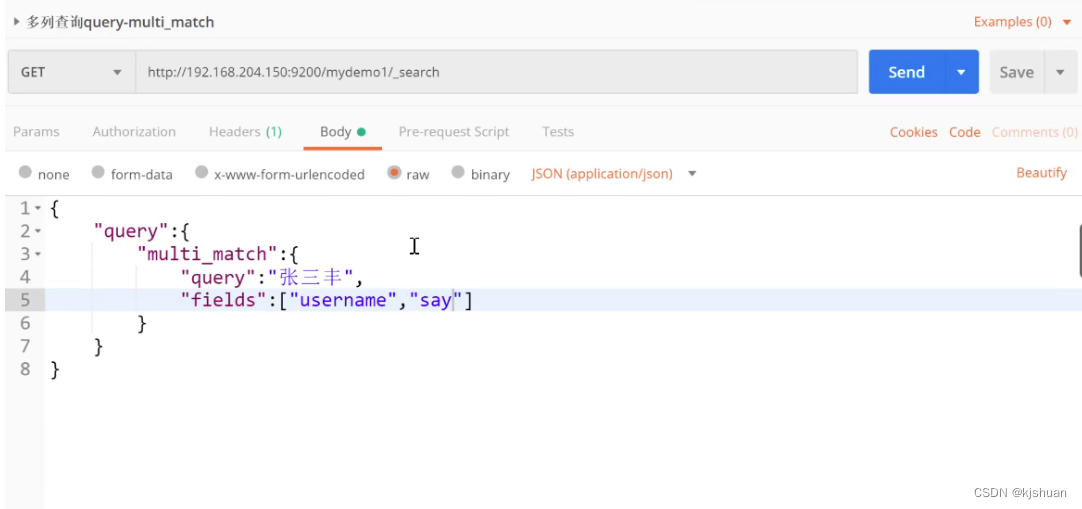
11.Consulta de varias columnas
12.en consulta query-query_string

13.término consulta término-consulta

14.Consulta de vocabulario múltiple

15. Consulta de rango

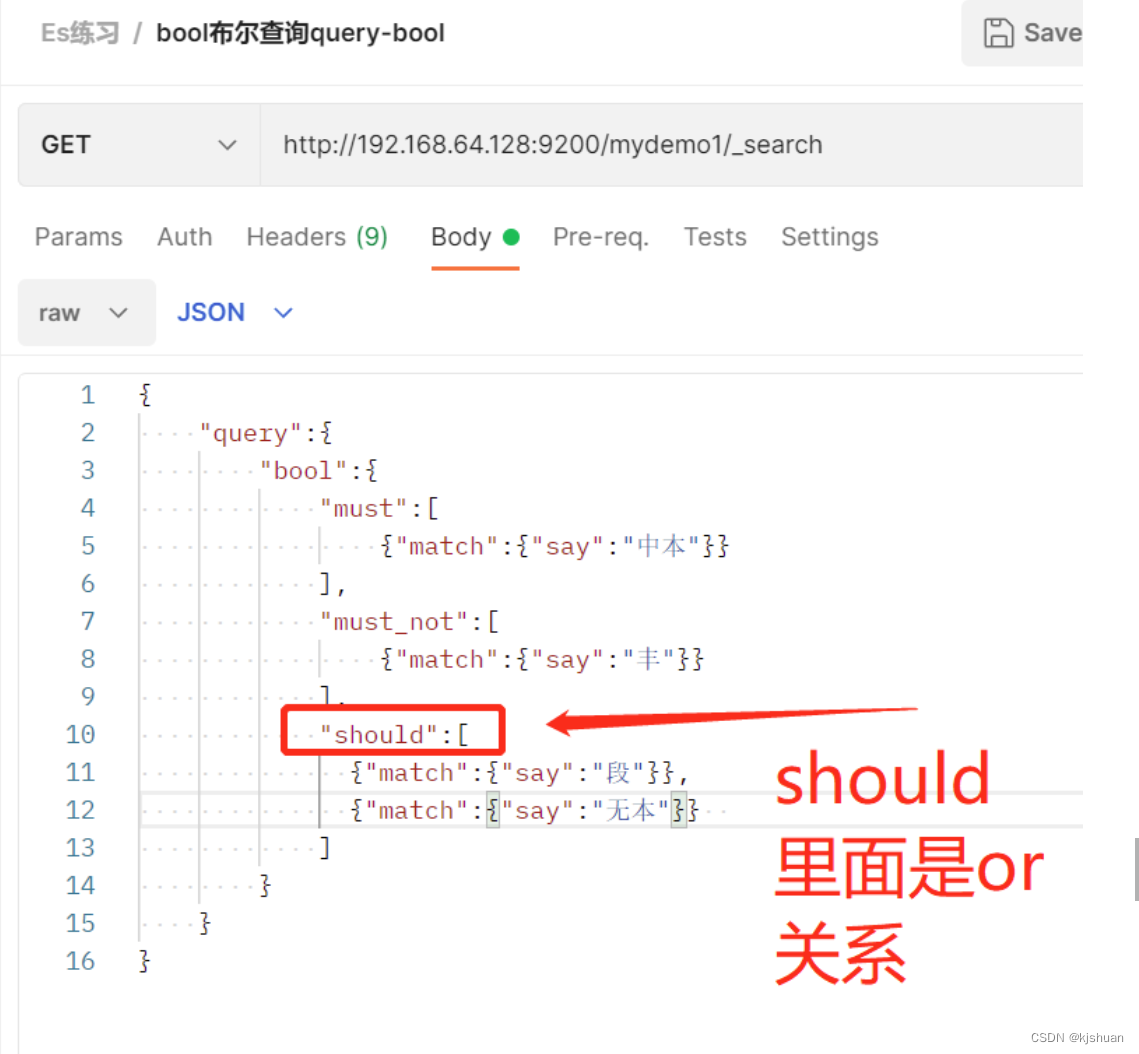
16. consulta booleana
Instalar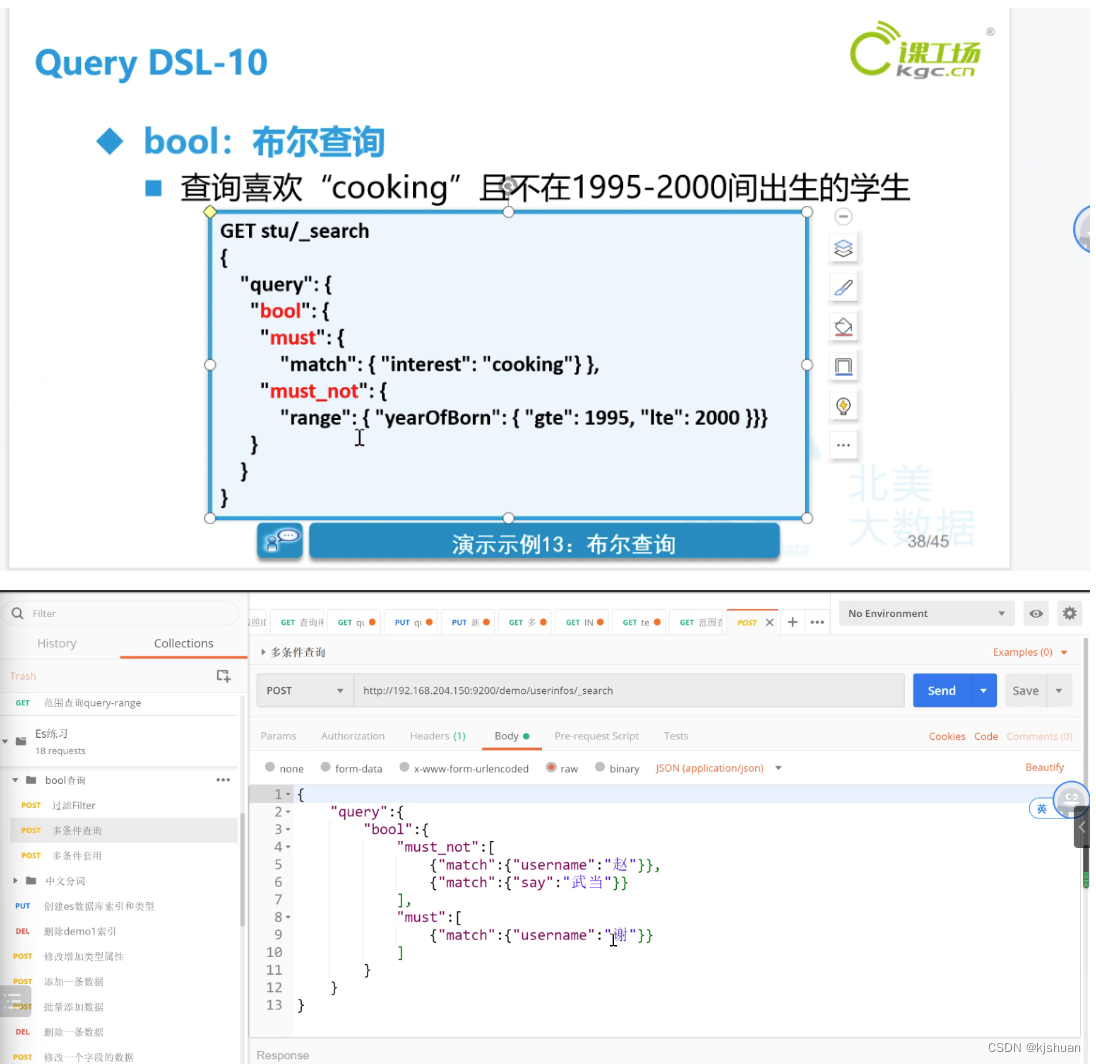

Instalación de segmentación de palabras chinas.
El requisito previo es arrastrar el paquete jar.

mkdir ik mv elasticsearch-analysis-ik-6.7.1.zip ik/ ls cd ik/ descomprimir elasticsearch-analysis-ik-6.7.1.zip cd .. mv ik/ /opt/soft/es671/plugins/ cd /opt /soft/es671/plugins/ ls cd ../.. chown cm:cm -R /opt/soft/es671/ su cm cd es671/bin/ ./elasticssearch -d su cd /opt/soft/eshead npm run empezar
Prueba del segmentador de palabras .ik
 .1 Uso del tokenizador
.1 Uso del tokenizador



integración springboot es

El primer paso es importar pom.
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version> 2.2.0.RELEASE </version> <relativePath/> <!-- lookup padre del repositorio --> </parent> <repositorios> <repositorio> <id>spring-snapshots</id> <url>http://repo.spring.io/libs-snapshot</url> </repository> </repositories> <pluginRepositories> <pluginRepository> <id>instantáneas de primavera</id> <url>http://repo.spring.io/libs-snapshot</url> </pluginRepository> </pluginRepositories><dependencia> <groupId>org.springframework.boot</groupId> <artifactId >spring-boot-starter-data-elasticsearch </artifactId> </dependencia>
El segundo paso es configurar yml.
servidor:
puerto: 8001
primavera:
aplicación:
nombre: myelastics
elasticsearch: resto :
uris : 192.168.64.128:9200
El tercer paso es configurar la clase de entidad.
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
@Document(indexName = "mydemo1",type= "userinfos" )
public class Userinfos {
@Id
private String id;
@Field(tipo = FieldType.Integer,nombre = "id de usuario")
ID de usuario entero privado;
@Field(tipo = FieldType.Text,nombre = "nombre de usuario")
cadena privada nombre de usuario; @JsonFormat(pattern = "yyyy-MM-dd")
@Field(type = FieldType.Date,name = "cumpleaños",format = DateFormat.date)
private Fecha de cumpleaños;
}
Paso 4 Configurar la interfaz del mapeador
interfaz pública UserinfosMapper extiende ElasticsearchRepository<Userinfos,String> {
}
Paso 5: configurar la consulta de prueba
@SpringBootTest
class Es05ApplicationTests {
@Resource
private UserinfosMapper userinfosMapper;
@Test
void contextLoads() {
//La primera consulta basada en id
// Opcional<Userinfos> op = userinfosMapper.findById("222");
//Si está vacío, no se informará ningún error
// op.ifPresent(a-> System.out.println(a));
// System.out.println(op.get());
//La segunda consulta difusa
MatchQueryBuilder qbmq = QueryBuilders. matchQuery("username ", "Zhang Wuji");
Iterable<Userinfos> search = userinfosMapper.search(qbmq);
//el método lamda se refiere a los resultados transversales
search.forEach(System.out::println);
}
}
¡Ver resultados!
