Directorio de artículos
1. La importancia de los algoritmos
- ingeniero de algoritmos
- Ejercite el pensamiento de código, escriba código de manera más eficiente
- Entrevista de aplicación (prueba escrita / prueba de computadora)
En segundo lugar, el algoritmo (algoritmo)
概念:一种设计过程,解决问题的办法。
Niklaus Wirth:“程序=数据结构+算法”
算法需要有输入和输出

1. Complejidad del tiempo
1.1 Introducción y análisis de problemas
 ¡Obviamente el primero en correr rápido!
¡Obviamente el primero en correr rápido!
类⽐⽣活中的⼀些事件,估计时间:
眨⼀下眼 =》一瞬间
⼝算“29+68” =》几秒
烧⼀壶⽔ =》几分钟
睡⼀觉 =》 几个小时
完成⼀个项⽬ =》几天/几星期/几个月
⻜船从地球⻜出太阳系 = 几年
La complejidad del tiempo es una fórmula que se utiliza para evaluar la eficiencia de un algoritmo.
Tome Python como ejemplo
print('hello world')
La complejidad de tiempo de esta oración se registra como: O (1)
donde 1 significa una unidad. Acordamos usar el tiempo perdido por oraciones simples como imprimir oraciones, suma, resta, multiplicación y división, y asignación como una unidad.
for i in range(n):
print('hello world')
Entonces la complejidad de tiempo de este código es O (n) porque hemos ejecutado n veces "1" ==》 n * 1 = n
parecido
for i in range(n):
for j in range(n):
print('hello world')
La complejidad del tiempo se registra como O (n²)
Nota:
Aquí una unidad no es un concepto exacto. En relación con un proceso repetido infinitamente, las declaraciones simples con ejecución limitada (declaraciones impresas, suma, resta, multiplicación y división, asignación) aún pueden considerarse como una unidad.
a = 2
print('hello world')
c = 4 + a
La complejidad temporal de este programa sigue siendo O (1) en lugar de O (3)
Lo mismo para
for i in range(n):
print('Hello World’)
for j in range(n):
print('Hello World')
La complejidad del tiempo es: O (n²) en lugar de O (n * (n + 1)) es O (n² + n)
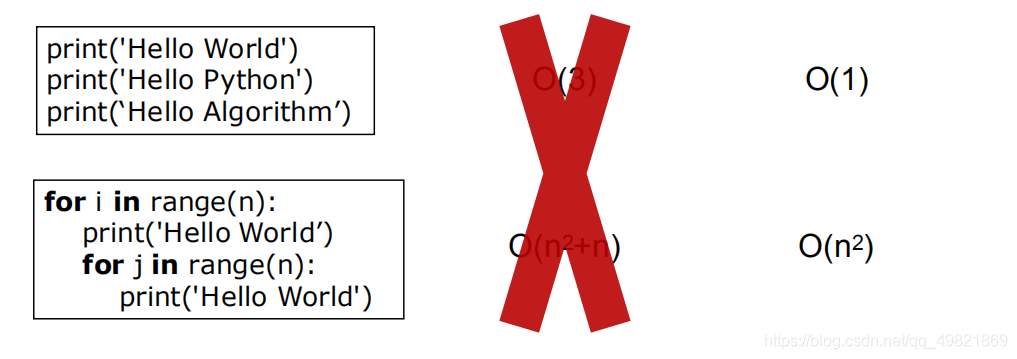
Para los siguientes problemas, lo llamamos el problema de la mitad
n = 64
while n > 1:
print(n)
n = n // 2
#输出
#64
#32
#16
#8
#4
#2
¿Cómo calcular la complejidad del tiempo?
解:设简单语句执行的次数(单位)为n
则:2**n=64 ==》 n = log2 64 =6
时间复杂度:O(n) = O(log2 64) = O(log 64)
Cuando el proceso del algoritmo se divide cíclicamente a la mitad, aparecerá logn en la fórmula de complejidad.
1.2 Resumen de complejidad temporal y productos secos
》时间复杂度是⽤来估计算法运⾏时间的⼀个式⼦(单位)。
》⼀般来说,时间复杂度⾼的算法⽐复杂度低的算法慢。
一般:因为程序运行时间长短还会受限于机器的性能这个物理因素。
》常⻅的时间复杂度(按效率排序)
》O(1)<O(logn)<O(n)<O(nlogn)<O(n2)<O(n2logn)<O(n3)
》复杂问题的时间复杂度
》O(n!) O(2n) O(nn)
1.3 Cómo juzgar la complejidad del algoritmo de manera simple y rápida (adecuado para la mayoría de situaciones simples)
-
Determine el tamaño del problema n
-
Proceso de reducción a la mitad del ciclo:》 logn
-
ciclo de capa k alrededor de n— "n elevado a la potencia k
-
Complejidad: juzgar en base al proceso de ejecución del algoritmo
2. Complejidad espacial
空间复杂度:用来评估算法内存占用大小的式子
空间复杂度的表达方式和时间复杂度完全一样
》算法使⽤了⼏个变量:O(1)
》算法使⽤了⻓度为n的⼀维列表:O(n)
》算法使⽤了m⾏n列的⼆维列表:O(mn)
Nota : En la
mayoría de los casos, "espacio para el tiempo" significa que el valor del tiempo es mayor que el del espacio.
Tres, algoritmo recursivo
1. Características recursivas
La recursividad es esencialmente un bucle. En teoría, todas las cosas recursivas que se pueden hacer se pueden hacer en un bucle, pero en algunos casos la recursividad es más fácil de implementar que los bucles.
特点:
1.调用自身
2.结束条件
def func1(x):
print(x)
func(x-1)
Esto no es recursividad, sino un bucle sin fin sin condición final
def func2(x):
if x>1:
print(x)
func(x-1)
Esto es recursivo lo
mismo
def func3(x):
if x>0:
print(x)
func2(x+1)
Esto no es recursividad
def func4(x):
if x>0:
func4(x-1)
print(x)
Esto es recursividad,
yo uso barras estrechas para indicar la impresión y cuadros grandes para indicar funciones para mostrar mejor el funcionamiento de func2. Suponga que x es 3, imprime 3, 2, 1 a su vez,

y func4 (3) imprime 1, 2, 3 a su vez
1.2 Ejemplo recursivo: el problema de la Torre de Hanoi
神话背景:(其实是一个数学家瞎扯的,骗你来学汉诺塔)
⼤梵天创造世界的时候做了三根⾦刚⽯柱⼦,在⼀根
柱⼦上从下往上按照⼤⼩顺序摞着64⽚⻩⾦圆盘。
⼤梵天命令婆罗⻔把圆盘从下⾯开始按⼤⼩顺序重新
摆放在另⼀根柱⼦上。
在⼩圆盘上不能放⼤圆盘,在三根柱⼦之间⼀次只能
移动⼀个圆盘。
64根柱⼦移动完毕之⽇,就是世界毁灭之时。

Suponemos que el número de platos es n:
"Cuando n = 0: no hacer nada, el problema ha terminado
" Cuando n = 1: A = "C
" Cuando n = 2: plato pequeño = "B, plato grande =" C , placa pequeña =》 B
》 Cuando n = 3: Las placas de pequeña a grande se marcan como 1
, 2, 3 respectivamente 》 entonces: 1 =》 C, 2 =》 B, 1 =》 B, 3 =》 C, 1 =》 A , 2 =》 C, 1 =》 C
…………………………
》 Cuando n = n: podemos entender que hay n-1 platos pequeños y 1 plato grande
. 1. Ponga n -1
Ponga un plato pequeño a través de C a B "2. Ponga el plato grande a C
" 3. Ponga n-1 platos pequeños a través de A a C para
completar la tarea.
在这个过程中,我们简化了问题的规模,其实这是递归的核心,我之前学递归的时候,总是把关注点放在大规模和小规模问题之间发生了什么这个点上,想也想不清……现在感觉只需要关注怎么把问题规模缩小的和递归终止条件即可。
Código:
def hanoi(n,a,b,c):
#这里的n是盘子数,a是盘子一开始在的位置,c是终点位置,b是过度位置
if n>0: #n=0任务完成
hanoi(n-1,a,c,b)
print(f'{a}=>{c}') #模拟最后一个盘子从a到c
hanoi(n-1,b,a,c)
Resultados:
a => c
a => b
c => b
a => c
b => a
b => c
a => c
Podemos compararlo con nuestro proceso de simulación manual anterior.
1.3 Interesante torre de Hanoi
》汉诺塔移动次数的递推式:h(x)=2h(x-1)+1
》h(64)=18446744073709551615
》假设婆罗⻔每秒钟搬⼀个盘⼦,则总共需要5800亿年
Cuatro, algoritmo de búsqueda
Encontrar: en algunos elementos de datos, el proceso de encontrar los elementos de datos que son iguales a la palabra clave dada a través de un método determinado.
Búsqueda de lista, también llamada búsqueda de tabla lineal: busque el elemento especificado de la lista
"Entrada: lista, elemento a buscar
" "Salida: encontrado: índice de elemento no encontrado: Ninguno / -1
Función de búsqueda de lista incorporada: índice () , su El efecto es como se describió anteriormente, la diferencia es que se lanzará una excepción si no se encuentra el elemento
lis = [1,2,3,4,5]
print(lis.index(1))
print(lis.index(6))
resultado
0 Traceback (última llamada más reciente): Archivo
“C: / Users / LENOVO / Desktop / 算法 .py”, línea 5,
impreso (lis.index (6)) ValueError: 6 no está en la lista
1. Buscar en orden
Búsqueda secuencial: también llamada búsqueda lineal, comienza desde el primer elemento de la lista y busca secuencialmente hasta que se encuentra el elemento o la búsqueda llega al final de la lista.
Complejidad temporal: O (n), n es la longitud de la lista, aquí nos referimos específicamente a una lista unidimensional
> def linear_search(data_set,value):
for i in range(len(data_set)):
if data_set[i] == value:
return i
resultado:
2. Búsqueda binaria / media búsqueda
Búsqueda binaria: también llamada búsqueda binaria. A partir del área de candidatos inicial de la lista ordenada, al comparar el valor a buscar con el valor intermedio del área de candidatos, el área de candidatos se puede reducir a la mitad cada vez que se selecciona .
Por ejemplo: la
 búsqueda binaria se realiza así:
búsqueda binaria se realiza así:
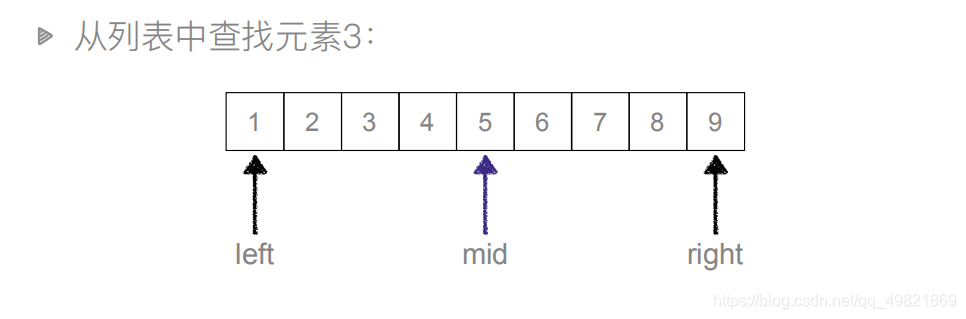
La primera búsqueda: izquierda = 0, derecha = 8, donde izquierda y derecha son los subíndices del elemento
mid = 4, el valor correspondiente al índice medio (el valor medio) es 5, 5> 3 La
segunda búsqueda: debido a la última vez 5> 3 y la lista es de pequeña a grande, podemos encontrar que el valor a buscar está en el lado izquierdo de mid, en este momento right = mid-1 = 4-1 = 3, left = 0 sin cambios, mid = \ (izquierda + derecha) // 2 (El subíndice es un valor entero) mid = 1, el valor medio es 2, 2 <3
Tercera búsqueda: podemos juzgar que el valor a buscar está a la derecha de mid según el segundo resultado de búsqueda, luego left = mid + 1 = 1 + 1 = 2, right = 3 permanece sin cambios, mid = (2 + 3) // 2 = 2, el valor correspondiente es 3, la búsqueda termina .
Vale la pena señalar que si izquierda> derecha significa que no hay ningún valor en el área central, significa que el elemento no está en la lista de búsqueda y la búsqueda finaliza.
Implementación de Python:
lis = [1,2,3,4]
def bin_search(data_set,value):
left,right = 0,len(data_set)-1
while left <= right:
mid = (left+right)//2
if data_set[mid]==value:
return mid
elif data_set[mid]>value:
high = mid-1
else:
left=mid+1
return -1
res =bin_search(lis,6)
print(res)
Resultado:
Complejidad de tiempo: O (logn) n es la longitud de la lista unidimensional
3. Comparar
Normalmente, la búsqueda binaria es más rápida que la búsqueda lineal, pero debido a que la premisa de la búsqueda binaria es que los elementos de la lista están ordenados, existe un proceso de clasificación. Si hay muchos elementos de la lista, la clasificación lleva mucho tiempo.
Entonces, la forma de elegir estos dos métodos de búsqueda también debe tener en cuenta circunstancias específicas.
La búsqueda se usa muchas veces, puede considerar ordenar +
índice de búsqueda binaria () en
Python es una búsqueda secuencial ps: Python viene con el método de clasificación
1.sort (),

2.sorted ()
lis = [1,2,3,4,5]
res = sorted(lis,key=lambda x:-x)
print(res)
resultado
