
Tabla de contenido
3. Método de búsqueda por interpolación
4. Método de búsqueda de Fibonacci
Encontrar algoritmo
Los algoritmos de búsqueda se pueden dividir en los dos tipos siguientes según el tamaño de los datos
- Búsqueda interna: la búsqueda interna se refiere a un algoritmo que realiza operaciones de búsqueda en la memoria o almacenamiento interno. La búsqueda interna es adecuada para situaciones en las que el tamaño de los datos es pequeño, está almacenado en la memoria o se accede a él rápidamente. Los algoritmos de búsqueda interna comunes incluyen búsqueda secuencial, búsqueda binaria, búsqueda por interpolación, etc.
- Búsqueda externa: la búsqueda externa se refiere a un algoritmo que realiza operaciones de búsqueda en colecciones de datos a gran escala o en medios de almacenamiento auxiliares, como discos externos.
Si la tabla o los datos buscados han cambiado se divide en los dos tipos siguientes:
- Búsqueda estática: la búsqueda estática se refiere a una operación de búsqueda realizada sin cambiar los datos que se buscan. Es decir, la tabla o los datos que se buscan permanecen sin cambios durante el proceso de búsqueda. La búsqueda estática es adecuada para situaciones en las que se buscan datos estáticos o de solo lectura. Una vez creado un índice o una tabla, las operaciones de búsqueda se pueden repetir sin modificar los datos. Los algoritmos de búsqueda estática comunes incluyen búsqueda secuencial, búsqueda binaria, búsqueda por interpolación, etc.
- Búsqueda dinámica: la búsqueda dinámica se refiere a una operación de búsqueda realizada cuando los datos que se buscan pueden modificarse durante el proceso de búsqueda. Es decir, la tabla o los datos que se buscan se pueden agregar, eliminar o actualizar durante el proceso de búsqueda. La búsqueda dinámica es adecuada para escenarios en los que se buscan datos dinámicos y es necesario responder a los cambios de datos en tiempo real. Los algoritmos de búsqueda dinámica comunes incluyen árboles de búsqueda binarios, árboles AVL, árboles rojo-negro, etc. Estas estructuras de árbol pueden lograr una búsqueda eficiente y admitir la inserción y eliminación de datos dinámicos.
1. Búsqueda secuencial
Ilustración:

Principio del algoritmo : la búsqueda secuencial, también llamada búsqueda lineal, es un algoritmo de búsqueda básico. Compara la secuencia de elementos que se van a encontrar uno por uno hasta que se encuentra el elemento objetivo o se recorre toda la secuencia. Los pasos específicos son los siguientes:
- A partir del primer elemento de la secuencia, se compara con el elemento objetivo en la secuencia.
- Si el elemento actual es igual al elemento de destino, la búsqueda es exitosa y se devuelve la posición correspondiente.
- Si el elemento actual no es igual al elemento de destino, continúe con el siguiente elemento para comparar.
- Si el elemento objetivo no se encuentra después de recorrer toda la secuencia, la búsqueda falla.
Código de caso:
public class javaDemo1 {
public static void main(String[] args) {
int data[] = new int[100];
int Target = 99;
int TargetIndex = -1;
Random random = new Random();
for (int i=0;i< data.length;i++){
data[i] = random.nextInt(100);
}
// 循序查找
for (int j=0;j< data.length;j++){
if (data[j] == Target){
TargetIndex = j;
break;
}
}
System.out.println(Arrays.toString(data));
if (TargetIndex!= -1){
System.out.println("找到数据啦,在第"+(TargetIndex+1)+"个数据处");
}else {
System.out.println("抱歉,并没有找到目标数据 喵");
}
}
}
Resumen del algoritmo: la complejidad temporal de la búsqueda secuencial es O (n), donde n es la longitud de la secuencia que se buscará. Debido a sus características simples e intuitivas, es adecuado para datos a pequeña escala o colecciones de datos desordenadas.
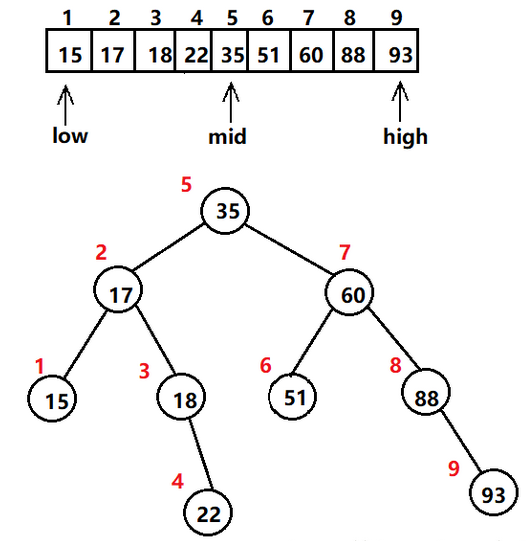
2. Búsqueda binaria
Ilustración:

Principio del algoritmo: la búsqueda binaria, también llamada media búsqueda, es un algoritmo de búsqueda eficiente que requiere que la secuencia a buscar esté en orden. Localiza rápidamente el elemento objetivo reduciendo continuamente el alcance de la búsqueda. Los pasos específicos son los siguientes:
- El primer elemento y el último elemento de la secuencia ordenada se utilizan como límites izquierdo y derecho respectivamente.
- Calcule la posición media mid y obtenga el elemento en el medio de la secuencia.
- Si el elemento del medio es igual al elemento de destino, la búsqueda es exitosa y se devuelve la posición correspondiente.
- Si el elemento del medio es más grande que el elemento objetivo, el elemento objetivo puede estar en la mitad izquierda y el rango reducido es la secuencia desde el límite izquierdo hasta la mitad de 1.
- Si el elemento central es más pequeño que el elemento objetivo, el elemento objetivo puede estar en la mitad derecha, reduciendo el rango a la secuencia desde mid+1 hasta el límite derecho.
- Repita los pasos anteriores hasta que se encuentre el elemento de destino o el rango de búsqueda esté vacío.
Código de caso:
public class javaDemo2 {
public static void main(String[] args) {
int data[] = new int[10];
// 目标值与目标值对应的下角标
int Target = 3;
int TargetIndex = -1;
// 二分法的下界与上界
int low = 0;
int high = data.length-1;
int middle;
Random random = new Random();
for (int i=0;i< data.length;i++){
data[i] = random.nextInt(10);
}
// 形成有序数组
Arrays.sort(data);
// 二分法查找
while (low<=high){
middle = (low+high)/2;
if (data[middle]>Target){
high = middle-1;
}else if (data[middle]<Target){
low = middle + 1;
}else {
TargetIndex = middle;
break;
}
}
System.out.println(Arrays.toString(data));
System.out.println("目标值为"+Target);
if (TargetIndex!= -1){
System.out.println("找到数据啦,在第"+(TargetIndex+1)+"个数据处");
}else {
System.out.println("抱歉,并没有找到目标数据 喵");
}
}
}
Resumen del algoritmo : la complejidad temporal de la búsqueda binaria es O (log n), donde n es la longitud de la secuencia que se buscará. Esto es más eficiente porque el rango de búsqueda se reduce a la mitad cada vez.
3. Método de búsqueda por interpolación
Ilustración:
Principio del algoritmo : El método de búsqueda por interpolación es un algoritmo de búsqueda optimizado basado en el método de dicotomía, que busca en función de la posición estimada del elemento objetivo en la secuencia ordenada, mejorando así la velocidad de búsqueda. Los pasos específicos son los siguientes:
- Calcule la posición estimada del elemento objetivo en relación con el primer y último elemento, es decir, calcule la posición de interpolación a mitad de la fórmula (objetivo - arr[izquierda]) / (arr[derecha] - arr[izquierda]) * (derecha - izquierda) + izquierda.
- Si la posición de interpolación media excede el rango de la matriz, o el elemento de destino es más pequeño que el primer elemento o más grande que el último elemento, significa que el elemento de destino no existe.
- Si el elemento en la posición de interpolación media es igual al elemento objetivo, la búsqueda es exitosa y se devuelve la posición correspondiente.
- Si el elemento en la posición de interpolación media es más grande que el elemento objetivo, el elemento objetivo puede estar en la mitad izquierda y el rango reducido es la secuencia desde el límite izquierdo hasta la mitad 1.
- Si el elemento en la posición de interpolación mid es más pequeño que el elemento objetivo, el elemento objetivo puede estar en la mitad derecha y el rango se reduce a la secuencia desde mid+1 hasta el límite derecho.
- Repita los pasos anteriores hasta que se encuentre el elemento de destino o el rango de búsqueda esté vacío.
Código de caso:
public class InsertSerach {
public static void main(String[] args) {
int data[] = new int[10];
int Target = 9;
int TargetIndex = -1;
int low = 0;
int high = data.length-1;
int middle;
Random random = new Random();
for (int i= 0;i< data.length;i++){
data[i] = random.nextInt(10);
}
// 实现数组排列有序
Arrays.sort(data);
// 插入查找
while (low<=high){
middle = low + (high - low) * (Target - data[low]) / (data[high] - data[low]);
if (data[middle]<Target){
low = middle +1;
}else if (data[middle]>Target){
high= middle -1;
}else {
TargetIndex = middle;
break;
}
}
System.out.println(Arrays.toString(data));
if (TargetIndex!= -1){
System.out.println("找到数据啦,在第"+(TargetIndex+1)+"个数据处");
}else {
System.out.println("抱歉,并没有找到目标数据 喵");
}
}
}Resumen del algoritmo: la complejidad temporal del método de búsqueda por interpolación es O (log log n), donde n es la longitud de la secuencia que se va a buscar. Funciona bien para secuencias ordenadas que están distribuidas uniformemente, pero puede que no funcione bien para secuencias que están distribuidas de manera desigual.
4. Método de búsqueda de Fibonacci
Ilustración:
Principio del algoritmo: el método de búsqueda de Fibonacci es un algoritmo de búsqueda binaria mejorado que utiliza el principio de la sección áurea para realizar la búsqueda. Primero, necesitas crear una secuencia de Fibonacci en la que cada elemento sea la suma de los dos elementos anteriores.
Cuando utilice el método de búsqueda de Fibonacci, primero debe determinar la longitud de una secuencia de Fibonacci de modo que la longitud no sea menor que la longitud de la matriz que se va a buscar. Luego, determine dos valores de Fibonacci, F(k)-1 y F(k-2)-1, según la longitud de la secuencia de Fibonacci.
Luego, en la matriz ordenada que se va a buscar, el elemento en la posición F(k)-1 se utiliza como valor intermedio para la comparación:
- Si el valor objetivo es igual al valor intermedio, la búsqueda tiene éxito y se devuelve la posición correspondiente.
- Si el valor objetivo es menor que el valor medio, la búsqueda de Fibonacci continúa en la mitad izquierda del valor medio.
- Si el valor objetivo es mayor que el valor medio, la búsqueda de Fibonacci continúa en la mitad derecha del valor medio.
Después de cada comparación, de acuerdo con la reducción del rango de búsqueda, se selecciona un nuevo valor intermedio para la siguiente comparación hasta que se encuentre el valor objetivo o el rango de búsqueda esté vacío.
Código de caso:
public class FibonacciSearch {
public static void main(String[] args) {
int data[] = new int[10];
int Target = 9;
int TargetIndex = -1;
int low = 0;
int high = data.length - 1;
int middle = 0;
Random random = new Random();
for (int i = 0; i < data.length; i++) {
data[i] = random.nextInt(10);
}
Arrays.sort(data);
// 生成斐波那契数列
int[] fibonacci = generateFibonacci(data.length);
// 根据斐波那契数列确定数组长度的最接近值
int length = getClosestFibonacciNumber(data.length);
// 扩展数组长度至斐波那契数列长度
int[] extendedData = Arrays.copyOf(data, length);
for (int i = data.length; i < extendedData.length; i++) {
extendedData[i] = extendedData[data.length - 1];
}
while (low <= high) {
int k = fibonacci[middle - 1];
if (Target < extendedData[middle]) {
high = middle - 1;
middle = low + k - 1;
} else if (Target > extendedData[middle]) {
low = middle + 1;
middle = low + k;
} else {
TargetIndex = Math.min(middle, high);
break;
}
}
System.out.println(Arrays.toString(data));
if (TargetIndex != -1) {
System.out.println("找到数据啦,在第" + (TargetIndex + 1) + "个数据处");
} else {
System.out.println("抱歉,并没有找到目标数据 喵");
}
}
// 生成斐波那契数列
private static int[] generateFibonacci(int length) {
int[] fibonacci = new int[length];
fibonacci[0] = 1;
fibonacci[1] = 1;
for (int i = 2; i < length; i++) {
fibonacci[i] = fibonacci[i - 1] + fibonacci[i - 2];
}
return fibonacci;
}
// 获取斐波那契数列中与数组长度最接近的数值
private static int getClosestFibonacciNumber(int n) {
int a = 0;
int b = 1;
while (b <= n) {
int temp = b;
b = a + b;
a = temp;
}
return a;
}
}
Resumen del algoritmo: la ventaja del método de búsqueda de Fibonacci sobre el método de búsqueda binaria tradicional es que puede acercarse al valor objetivo más rápido y evitar el problema de desbordamiento de enteros que ocurre al tomar valores intermedios en la búsqueda binaria. Sin embargo, en algunos casos, el rendimiento del método de búsqueda de Fibonacci puede no ser tan bueno como el del método de búsqueda binaria, por lo que en aplicaciones prácticas, es necesario elegir un algoritmo de búsqueda apropiado según la situación específica.