Para participar en el desarrollo del lado del servidor, debe ponerse en contacto con la programación de la red. Epoll es una tecnología esencial para servidores de red de alto rendimiento bajo Linux. Esta tecnología de multiplexación se utiliza en nginx, Redis, Skynet y la mayoría de los servidores de juegos.
Epoll es muy importante, pero ¿cuál es la diferencia entre epoll y select? ¿Cuál es el motivo de la alta eficiencia de epoll?

Aunque hay muchos artículos que explican el epoll en Internet, son demasiado simples o están atrapados en el análisis del código fuente, y pocos son fáciles de entender. Por lo tanto, el autor decidió escribir este artículo para que los lectores que carezcan de conocimientos profesionales también puedan comprender el principio de epoll.
La idea central del artículo es: permitir que los lectores comprendan claramente por qué epoll funciona bien.
Este artículo comenzará con el proceso de recibir datos de la tarjeta de red, conectará el conocimiento de la interrupción de la CPU, la programación del proceso del sistema operativo, etc .; luego analizará el proceso de evolución del bloqueo de la recepción de datos, seleccione la opción de recopilación paso a paso; finalmente, explore los detalles de implementación de epoll.
[Beneficios del artículo] El editor recomienda mi propio grupo de intercambio de idiomas linuxC / C ++: 832218493. He compilado algunos libros de aprendizaje y materiales de video que creo que son mejores para compartir. ¡Puede agregarlos si los necesita! ~!

1. Hablando de recibir datos de la tarjeta de red
A continuación se muestra un diagrama de estructura de computadora típico. La computadora está compuesta de CPU, memoria (memoria) e interfaz de red. El primer paso para comprender la esencia de epoll es ver cómo la computadora recibe los datos de red desde la perspectiva del hardware.
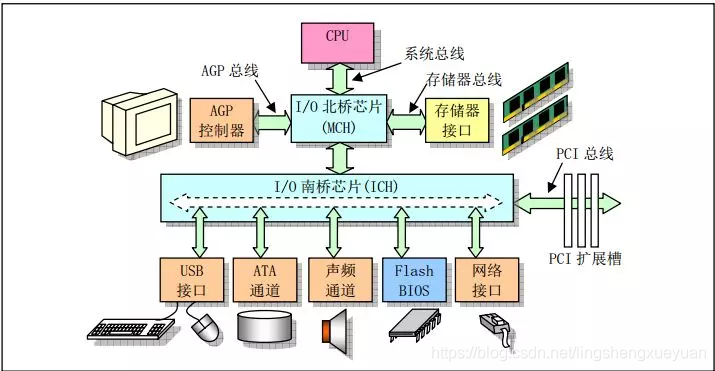
Diagrama de estructura de la computadora (fuente de la imagen: la estructura de la composición de la microcomputadora anotada completamente por el kernel de Linux)
La siguiente figura muestra el proceso de recepción de datos de la tarjeta de red.
En la etapa ①, la tarjeta de red recibe los datos del cable de red;
después de la transmisión del circuito de hardware en la etapa ②;
finalmente, en la etapa ③, los datos se escriben en una dirección en la memoria.
Este proceso implica conocimientos relacionados con el hardware, como la transmisión DMA y la selección del canal IO, pero solo necesitamos saber: la tarjeta de red escribirá los datos recibidos en la memoria.

El proceso de recepción de datos de la tarjeta de red
A través de la transmisión por hardware, los datos recibidos por la tarjeta de red se almacenan en la memoria y el sistema operativo puede leerlos.
2. ¿Cómo sé que se reciben los datos?
El segundo paso para comprender la esencia de epoll es observar la recepción de datos desde la perspectiva de la CPU. Para comprender este problema, primero debemos comprender un concepto de interrupción.
Cuando una computadora ejecuta un programa, existe un requisito de prioridad. Por ejemplo, cuando la computadora recibe una señal de apagado, debe guardar los datos inmediatamente. El programa que guarda los datos tiene una prioridad más alta (el capacitor puede ahorrar una pequeña cantidad de energía para que la CPU funcione por un período corto de hora).
En términos generales, la señal generada por el hardware requiere que la CPU responda de inmediato, de lo contrario, los datos pueden perderse, por lo que tiene una alta prioridad. La CPU debe interrumpir el programa que se está ejecutando para dar una respuesta; cuando la CPU completa la respuesta al hardware, vuelve a ejecutar el programa de usuario. El proceso de interrupción es como se muestra en la figura siguiente, es similar a una llamada de función, excepto que la llamada de función se localiza de antemano y la ubicación de la interrupción está determinada por la "señal".

Interrumpir llamada de programa
Tome el teclado como ejemplo.Cuando el usuario presiona una tecla en el teclado, el teclado enviará un nivel alto al pin de interrupción de la CPU, que puede capturar esta señal y luego ejecutar el programa de interrupción del teclado. La siguiente figura muestra el proceso de varios hardware que interactúan con la CPU a través de interrupciones.

Interrupción de la CPU (fuente de la imagen: net.pku.edu.cn)
Ahora puede responder a la pregunta "¿Cómo sé que se reciben los datos?": Cuando la tarjeta de red escribe datos en la memoria, la tarjeta de red envía una señal de interrupción a la CPU y el sistema operativo puede saber que hay nuevos datos viene, y luego interrumpe el programa a través de la tarjeta de red.
3. ¿Por qué el bloque de proceso no ocupa recursos de la CPU?
El tercer paso para comprender la esencia de epoll es mirar la recepción de datos desde la perspectiva de la programación de procesos del sistema operativo. El bloqueo es una parte clave de la programación del proceso. Se refiere al estado de espera de un proceso antes de que ocurra un evento (como recibir datos de la red). Recv, select y epoll son todos métodos de bloqueo. Analicemos por qué el bloqueo de procesos no ocupa recursos de CPU.
En aras de la simplicidad, comencemos el análisis desde la recepción de recepción ordinaria, primero mire el siguiente código:
//创建socket
int s = socket(AF_INET, SOCK_STREAM, 0);
//绑定
bind(s, ...)
//监听
listen(s, ...)
//接受客户端连接
int c = accept(s, ...)
//接收客户端数据
recv(c, ...);
//将数据打印出来
printf(...)
Este es el código de programación de red más básico. Primero cree un nuevo objeto de socket, llame a bind, escuche y acepte a su vez, y finalmente llame a recv para recibir datos. Recv es un método de bloqueo, cuando el programa se ejecuta en recv, esperará hasta recibir datos antes de ejecutarlo.
Entonces, ¿cuál es el principio de bloqueo?
Cola de trabajo
Para admitir la multitarea, el sistema operativo realiza la función de programación de procesos y divide el proceso en varios estados, como "en ejecución" y "en espera". El estado de ejecución es el estado en el que el proceso obtiene el derecho a usar la CPU y el código se está ejecutando; el estado de espera es el estado de bloqueo. Por ejemplo, cuando el programa anterior se ejecuta a recv, el programa cambiará del estado de ejecución al estado de espera y luego volver al estado de ejecución después de recibir los datos. El sistema operativo ejecutará los procesos en cada estado de ejecución de una manera de tiempo compartido. Debido a su alta velocidad, parece que está realizando múltiples tareas simultáneamente.
La computadora en la siguiente figura está ejecutando tres procesos, A, B y C. El proceso A está ejecutando el programa de red básico mencionado anteriormente. Al principio, estos tres procesos están referenciados por la cola de trabajo del sistema operativo. Se están ejecutando y se llevará a cabo el tiempo compartido.
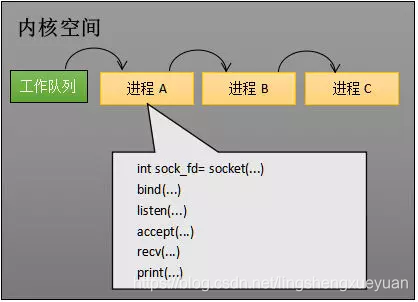
Hay tres procesos A, B y C en la cola de trabajos
Cola de espera
Cuando el proceso A ejecuta la instrucción para crear un socket, el sistema operativo creará un objeto socket administrado por el sistema de archivos (como se muestra a continuación). Este objeto de socket contiene miembros como el búfer de envío, el búfer de recepción y la cola de espera. La cola de espera es una estructura muy importante, que apunta a todos los procesos que necesitan esperar el evento de socket.
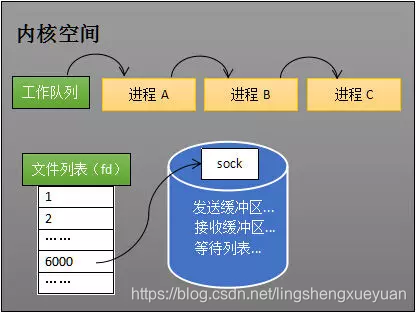
Crear socket
Cuando el programa llega a recv, el sistema operativo moverá el proceso A de la cola de trabajo a la cola de espera del socket (como se muestra en la figura siguiente). Dado que solo quedan los procesos B y C en la cola de trabajo, de acuerdo con la programación del proceso, la CPU ejecutará los programas de estos dos procesos a su vez, y no ejecutará los programas del proceso A. Por lo tanto, el proceso A está bloqueado y no ejecutará el código y no ocupará recursos de la CPU.
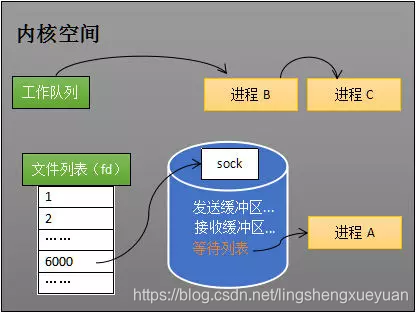
Cola de espera de socket
Nota: La cola de espera agregada por el sistema operativo solo agrega una referencia a este proceso de "espera" para que pueda obtener el objeto de proceso y reactivarlo cuando se reciben datos, en lugar de incorporar directamente la administración de procesos en sí mismo. Para la comodidad de la ilustración, la figura anterior cuelga directamente el proceso debajo de la cola de espera.
Despertar proceso
Cuando el socket recibe los datos, el sistema operativo vuelve a colocar el proceso en la cola de espera del socket en la cola de trabajo, el proceso comienza a ejecutarse y el código continúa ejecutándose. Al mismo tiempo, debido a que el búfer de recepción del socket ya tiene datos, recv puede devolver los datos recibidos.
Cuarto, todo el proceso de recepción de datos de red por parte del kernel.
En este paso, a través del conocimiento de las tarjetas de red, las interrupciones y la programación de procesos, se describe todo el proceso de recepción de datos por parte del kernel bajo el bloqueo recv.
Como se muestra en la figura siguiente, durante el período de bloqueo de recepción, la computadora recibe los datos transmitidos por el extremo opuesto (paso ①), y los datos se transmiten a la memoria a través de la tarjeta de red (paso ②), y luego la tarjeta de red informa a la CPU de la llegada de datos a través de una señal de interrupción, y la CPU ejecuta el programa de interrupción (Paso ③).
El programa de interrupción aquí tiene dos funciones principales: Primero, escriba los datos de red en el búfer de recepción del conector correspondiente (paso ④), luego active el proceso A (paso ⑤) y coloque el proceso A en la cola de trabajo nuevamente.
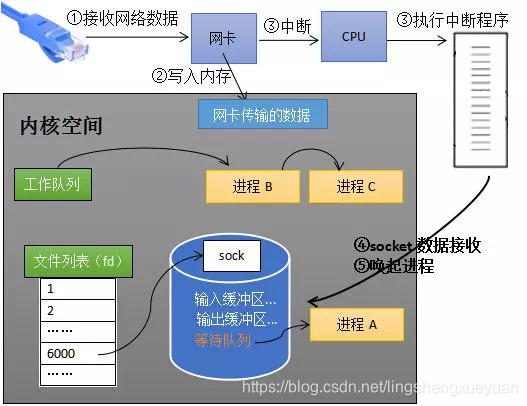
Todo el proceso de recepción de datos del kernel
El proceso de activación del proceso se muestra en la siguiente figura:

Despertar proceso
Lo anterior es todo el proceso de recepción de datos por parte del kernel. Aquí podemos pensar en dos cuestiones:
Primero, ¿cómo sabe el sistema operativo a qué socket corresponden los datos de red?
En segundo lugar, ¿cómo monitorear los datos de múltiples sockets al mismo tiempo?
La primera pregunta: debido a que un socket corresponde a un número de puerto y el paquete de datos de red contiene información de puerto e ip, el kernel puede encontrar el socket correspondiente a través del número de puerto. Por supuesto, para mejorar la velocidad de procesamiento, el sistema operativo mantendrá la estructura de índice del número de puerto al socket para una lectura rápida.
El segundo tema es la máxima prioridad de la multiplexación, que es el tema central de la segunda mitad de este artículo.
Cinco, una forma sencilla de supervisar varios enchufes al mismo tiempo
El servidor necesita administrar múltiples conexiones de clientes, mientras que recv solo puede monitorear un único socket Bajo esta contradicción, la gente comenzó a buscar formas de monitorear múltiples sockets. La esencia de epoll es monitorear de manera eficiente múltiples enchufes.
Desde la perspectiva del desarrollo histórico, primero debe aparecer un método ineficiente, y la gente lo mejorará, al igual que seleccionar es epoll.
Para comprender primero la selección menos eficiente, puede comprender mejor la naturaleza de epoll.
Si es posible pasar una lista de sockets por adelantado, si no hay datos en los sockets de la lista, suspenda el proceso hasta que un socket reciba datos y reactive el proceso. Este método es muy sencillo y también es la idea de diseño de select.
Para facilitar la comprensión, revisemos primero el uso de seleccionar. En el siguiente código, primero prepare una matriz fds para que fds almacene todos los sockets que necesitan ser monitoreados. Luego llame a select. Si todos los sockets en fds no tienen datos, select se bloqueará hasta que un socket reciba datos, select regresa y reactiva el proceso. El usuario puede atravesar fds, determinar qué socket recibió los datos a través de FD_ISSET y luego realizar el procesamiento.
int s = socket(AF_INET, SOCK_STREAM, 0);
bind(s, ...);
listen(s, ...);
int fds[] = 存放需要监听的socket;
while(1){
int n = select(..., fds, ...)
for(int i=0; i < fds.count; i++){
if(FD_ISSET(fds[i], ...)){
//fds[i]的数据处理
}
}}
seleccionar proceso
La idea de implementación de select es muy sencilla. Si el programa supervisa tres sockets, sock1, sock2 y sock3 como se muestra en la figura siguiente, después de llamar a select, el sistema operativo agrega el proceso A a las colas de espera de estos tres sockets.
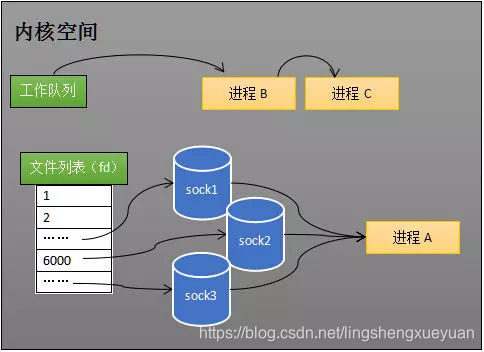
El sistema operativo agrega el proceso A a la cola de espera de estos tres sockets
Cuando cualquier conector recibe datos, el programa de interrupción activará el proceso. La siguiente figura muestra el flujo de procesamiento de los datos recibidos por sock2:
Nota: La devolución de llamada de interrupción de recv y select se puede configurar para un contenido diferente.
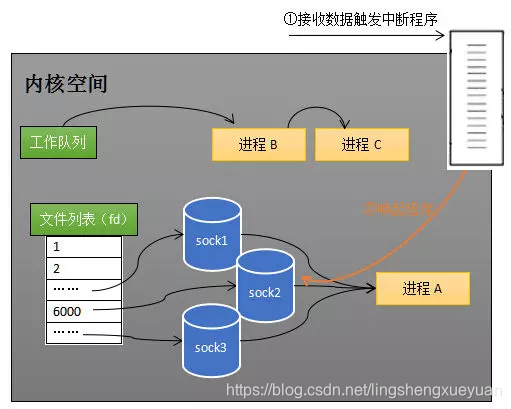
sock2 recibe los datos, el programa de interrupción evoca el proceso A
El llamado proceso de activación consiste en eliminar el proceso de todas las colas de espera y agregarlo a la cola de trabajo, como se muestra en la siguiente figura:
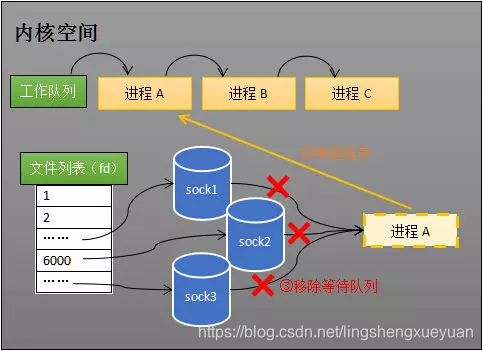
Elimine el proceso A de todas las colas de espera y agréguelo a la cola de trabajo
Después de estos pasos, cuando el proceso A se despierta, sabe que al menos un socket ha recibido datos. El programa solo necesita recorrer la lista de sockets una vez para tener el socket listo.
Este método simple funciona bien y tiene implementaciones correspondientes en casi todos los sistemas operativos.
Pero los métodos simples a menudo tienen desventajas, principalmente:
Primero, cada llamada para seleccionar debe agregar el proceso a la cola de espera de todos los sockets de monitoreo, y cada activación debe eliminarse de cada cola. Aquí están involucrados dos recorridos, y cada vez que se pasa la lista completa de fds al kernel, hay una cierta sobrecarga. Es precisamente debido al alto costo de la operación transversal que, por consideraciones de eficiencia, se especifica el número máximo de monitoreo de selección y solo se pueden monitorear 1024 sockets de forma predeterminada.
En segundo lugar, después de que se despierta el proceso, el programa no sabe qué sockets recibieron datos y necesita recorrerlos una vez.
Entonces, ¿hay alguna manera de reducir el recorrido? ¿Hay alguna forma de guardar el socket listo? Estos dos problemas son la tecnología epoll a resolver.
Nota complementaria: esta sección solo explica una situación de selección. Cuando el programa llama a select, el núcleo primero atravesará el socket, si hay más de un socket recibiendo búfer con datos, select regresará directamente sin bloquear. Esta es una de las razones por las que el valor de retorno de select puede ser mayor que 1. Si ningún socket tiene datos, el proceso se bloqueará.
Seis, ideas de diseño de epoll
Epoll se inventó muchos años después de que apareciera select N. Es una versión mejorada de select y poll (poll y select son básicamente lo mismo, con algunas mejoras). Epoll utiliza las siguientes medidas para mejorar la eficiencia:
Medida 1: Separación de funciones
Una de las razones de la ineficacia de la selección son los dos pasos de "mantener la cola de espera" y "bloquear el proceso" en uno. Como se muestra en la figura siguiente, cada llamada para seleccionar requiere dos pasos, sin embargo, en la mayoría de los escenarios de aplicación, el socket que se va a monitorear es relativamente fijo y no necesita ser modificado cada vez. Epoll separa estas dos operaciones, primero mantiene la cola de espera con epoll_ctl y luego llama a epoll_wait para bloquear el proceso. Evidentemente, se puede mejorar la eficiencia.
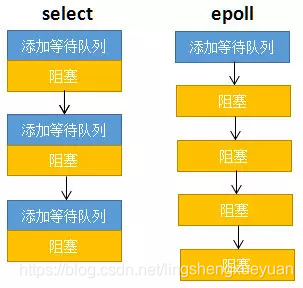
Comparado con select, epoll divide la función
Para facilitar la comprensión del contenido posterior, primero comprendamos el uso de epoll. En el siguiente código, primero use epoll_create para crear un objeto epoll epfd, luego agregue el socket a monitorear a epfd a través de epoll_ctl, y finalmente llame a epoll_wait para esperar los datos:
int s = socket(AF_INET, SOCK_STREAM, 0);
bind(s, ...)
listen(s, ...)
int epfd = epoll_create(...);
epoll_ctl(epfd, ...); //将所有需要监听的socket添加到epfd中
while(1){
int n = epoll_wait(...)
for(接收到数据的socket){
//处理
}
}
La separación de funciones permite optimizar epoll.
Medida 2: Lista lista
Otra razón de la ineficacia de la selección es que el programa no sabe qué sockets reciben datos y solo puede atravesar uno por uno. Si el kernel mantiene una "lista lista" que se refiere al socket que recibió los datos, puede evitar el cruce. Como se muestra en la figura siguiente, la computadora tiene tres sockets, y sock2 y sock3 cuyos datos recibidos son referenciados por la lista lista rdlist. Cuando se despierta el proceso, siempre que obtenga el contenido de rdlist, puede saber qué sockets recibieron datos.
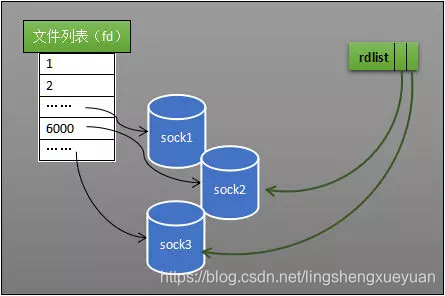
Diagrama esquemático de lista lista
Siete, principio epoll y proceso de trabajo
Esta sección explicará el principio y el flujo de trabajo de epoll con ejemplos y diagramas.
Crear objeto epoll
Como se muestra en la figura siguiente, cuando un proceso llama al método epoll_create, el kernel crea un objeto eventpoll (es decir, el objeto representado por epfd en el programa). El objeto eventpoll también es miembro del sistema de archivos y, al igual que los sockets, también tiene una cola de espera.
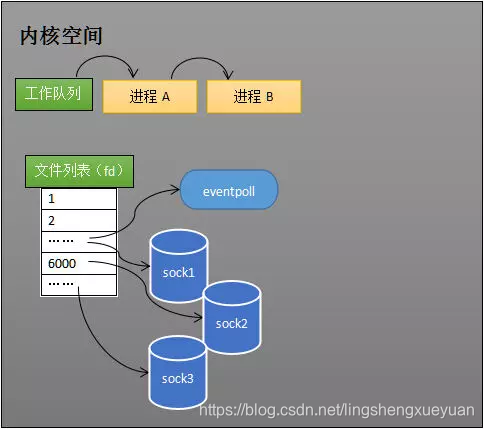
El kernel crea objetos eventpoll
Es necesario crear un objeto eventpoll que represente el epoll, porque el núcleo necesita mantener datos como la "lista lista", y la "lista lista" puede ser miembro de eventpoll.
Mantener lista de vigilancia
Después de crear un objeto epoll, puede usar epoll_ctl para agregar o eliminar el socket que se va a monitorear. Tomemos como ejemplo la adición de socket.Como se muestra en la siguiente figura, si agrega el monitoreo sock1, sock2 y sock3 a través de epoll_ctl, el kernel agregará eventpoll a la cola de espera de estos tres sockets.
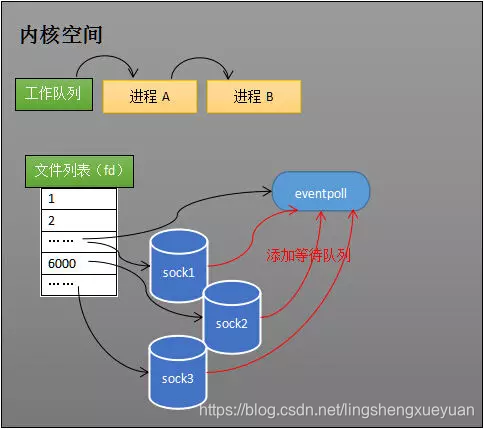
Agregue el enchufe para monitorear
Cuando el socket recibe datos, el programa de interrupción operará el objeto eventpoll en lugar de operar directamente el proceso.
Recibir datos
Cuando el socket recibe los datos, el programa de interrupción agregará una referencia de socket a la "lista lista" de eventpoll. La siguiente figura muestra que después de que sock2 y sock3 reciben los datos, el programa de interrupción hace que rdlist se refiera a estos dos sockets.
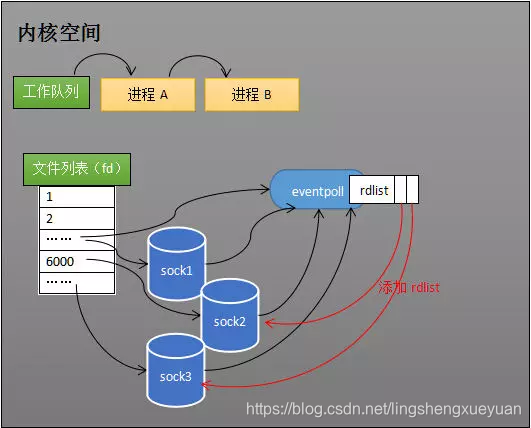
Agregar una referencia a la lista lista
El objeto eventpoll es equivalente al intermediario entre el socket y el proceso La recepción de datos del socket no afecta directamente al proceso, pero cambia el estado del proceso al cambiar la lista lista de eventpoll.
Cuando el programa se ejecuta en epoll_wait, si rdlist ya ha hecho referencia al socket, entonces epoll_wait regresa directamente, si rdlist está vacío, el proceso se bloquea.
Bloquear y despertar el proceso
Suponga que el proceso A y el proceso B se están ejecutando en la computadora y, en algún momento, el proceso A se ejecuta en la instrucción epoll_wait. Como se muestra en la siguiente figura, el kernel pondrá el proceso A en la cola de espera de eventpoll, bloqueando el proceso.

proceso de bloqueo epoll_wait
Cuando el socket recibe datos, el programa de interrupción modifica rdlist por un lado y, por otro lado, despierta eventpoll para esperar el proceso en la cola, y el proceso A entra de nuevo en estado de ejecución (como se muestra a continuación). También debido a la existencia de rdlist, el proceso A puede saber qué sockets han cambiado.
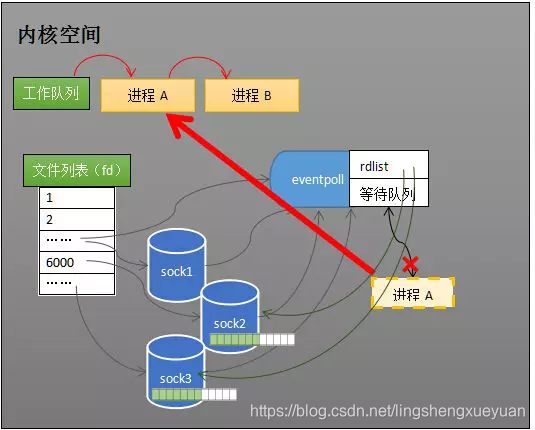
epoll despierta el proceso
8. Detalles de la implementación de epoll
En este punto, creo que los lectores tienen una cierta comprensión de la naturaleza de epoll. Pero también necesitamos saber cómo es la estructura de datos de eventpoll.
Además, ¿qué estructura de datos debería utilizar la cola lista? ¿Qué estructura de datos debería usar eventpoll para administrar los sockets agregados o eliminados a través de epoll_ctl?
Como se muestra en la figura siguiente, eventpoll contiene lock, mtx, wq (cola de espera) y rdlist, entre los cuales rdlist y rbr son lo que nos importa.
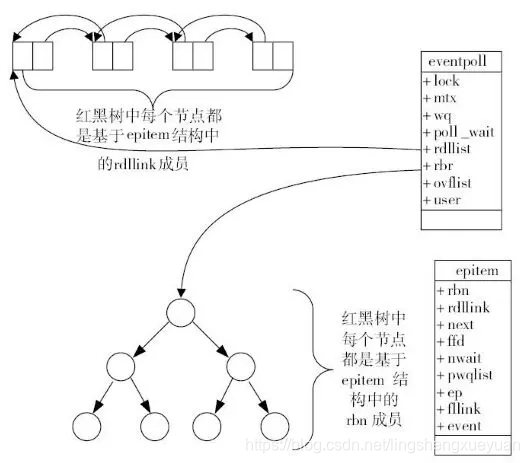
Diagrama esquemático del principio de epoll, fuente de la imagen: "Comprensión profunda de Nginx: desarrollo de módulos y análisis de arquitectura (segunda edición)", Tao Hui
Estructura de datos de la lista lista
La lista lista se refiere al socket listo, por lo que debería poder insertar datos rápidamente.
El programa puede llamar a epoll_ctl para agregar un conector de monitoreo en cualquier momento, o puede eliminarlo en cualquier momento. Al eliminar, si el socket ya está en la lista de listos, también debe eliminarse. Por lo tanto, la lista lista debe ser una estructura de datos que se pueda insertar y eliminar rápidamente.
Una lista doblemente enlazada es una estructura de datos de este tipo, y epoll usa una lista doble enlazada para implementar la cola lista (correspondiente a la lista de lista en la figura anterior).
Estructura del índice
Dado que epoll separa la "cola de supervisión de mantenimiento" y el "bloqueo de procesos", también significa que se necesita una estructura de datos para almacenar los sockets supervisados, al menos para una fácil adición y eliminación, y una búsqueda sencilla para evitar adiciones repetidas. El árbol rojo-negro es un árbol de búsqueda binario autoequilibrado. La complejidad temporal de la búsqueda, la inserción y la eliminación son todas O (log (N)), y la eficiencia es mejor. Epoll utiliza el árbol rojo-negro como estructura de índice (correspondiente al rbr en la figura anterior)).
Nota: Debido a que el sistema operativo debe tener en cuenta múltiples funciones y más datos que deben guardarse, rdlist no se refiere directamente al socket, sino indirectamente a través de epitem. Los nodos del árbol rojo-negro también son objetos de epitem. De manera similar, el sistema de archivos no se refiere directamente al socket. Para facilitar la comprensión, en este artículo se omiten algunas estructuras indirectas.
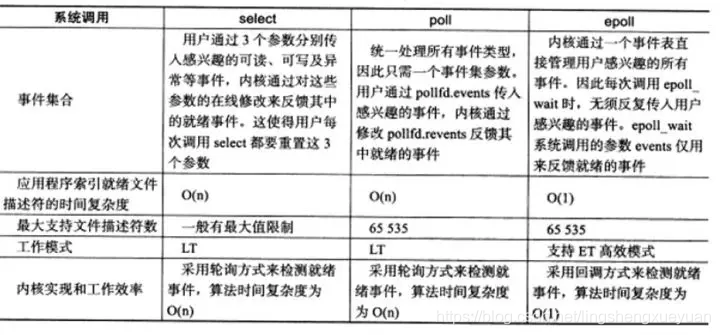
Nueve, resumen
Epoll presenta eventpoll como una capa intermedia basada en selección y sondeo, utiliza estructuras de datos avanzadas y es una tecnología de multiplexación eficiente. Aquí también hay una comparación simple de select, poll y epoll en forma de tabla para finalizar este artículo. Espero que los lectores puedan ganar algo.