Originalmente, el proceso de recorrido del mapa era relativamente simple: atravesar todos los depósitos y los depósitos desbordados detrás de ellos, y luego atravesar todas las celdas del depósito una por una. Cada depósito contiene 8 celdas. La clave y el valor se extraen de la celda con la clave y el proceso se completa.
Sin embargo, la realidad no es tan simple. ¿Recuerda el proceso de expansión mencionado anteriormente? El proceso de expansión no es una operación atómica. Solo mueve hasta 2 depósitos a la vez. Por lo tanto, si se activa la operación de expansión, el estado del mapa estará en un estado intermedio durante mucho tiempo: algunos depósitos se han movido. a casas nuevas, y algunos cubos se han trasladado a casas nuevas. Algunos cubos todavía están en el mismo lugar.
Por lo tanto, si el recorrido ocurre durante el proceso de expansión, implicará el proceso de atravesar los depósitos nuevos y antiguos, que es la dificultad.
Primero, permítanme escribir un ejemplo de código simple, pretendiendo no saber qué función se llama específicamente durante el proceso transversal:
package main
import "fmt"
func main() {
ageMp := make(map[string]int)
ageMp["qcrao"] = 18
for name, age := range ageMp {
fmt.Println(name, age)
}
}
Ejecutando una orden:
go tool compile -S main.go
Obtenga el comando de ensamblaje. No lo explicaré línea por línea aquí, puedes leer los artículos anteriores, que lo explican en detalle.
Las líneas clave del código ensamblador son las siguientes:
// ......
0x0124 00292 (test16.go:9) CALL runtime.mapiterinit(SB)
// ......
0x01fb 00507 (test16.go:9) CALL runtime.mapiternext(SB)
0x0200 00512 (test16.go:9) MOVQ ""..autotmp_4+160(SP), AX
0x0208 00520 (test16.go:9) TESTQ AX, AX
0x020b 00523 (test16.go:9) JNE 302
// ......
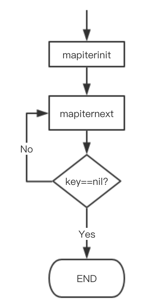
De esta manera, con respecto a la iteración del mapa, la relación de llamada a la función subyacente es clara de un vistazo. Primero, mapiterinitse llama a la función para inicializar el iterador y luego mapiternextse llama a la función en un bucle para iterar el mapa.
Definición de estructura de iterador:
type hiter struct {
// key 指针
key unsafe.Pointer
// value 指针
value unsafe.Pointer
// map 类型,包含如 key size 大小等
t *maptype
// map header
h *hmap
// 初始化时指向的 bucket
buckets unsafe.Pointer
// 当前遍历到的 bmap
bptr *bmap
overflow [2]*[]*bmap
// 起始遍历的 bucket 编号
startBucket uintptr
// 遍历开始时 cell 的编号(每个 bucket 中有 8 个 cell)
offset uint8
// 是否从头遍历了
wrapped bool
// B 的大小
B uint8
// 指示当前 cell 序号
i uint8
// 指向当前的 bucket
bucket uintptr
// 因为扩容,需要检查的 bucket
checkBucket uintptr
}
mapiterinitEs para inicializar y asignar valores a los campos en la estructura hiter.
Como se mencionó anteriormente, incluso si se recorre un mapa codificado, los resultados siempre estarán desordenados. A continuación podemos echar un vistazo más de cerca a su implementación.
// 生成随机数 r
r := uintptr(fastrand())
if h.B > 31-bucketCntBits {
r += uintptr(fastrand()) << 31
}
// 从哪个 bucket 开始遍历
it.startBucket = r & (uintptr(1)<<h.B - 1)
// 从 bucket 的哪个 cell 开始遍历
it.offset = uint8(r >> h.B & (bucketCnt - 1))
Por ejemplo, B = 2, entonces uintptr(1)<<h.B - 1el resultado es 3, y los 8 bits inferiores son 0000 0011. Al hacer AND con r, puede obtener un 0~3número de depósito; bucketCnt - 1 es igual a 7, y los 8 bits inferiores son 0000 0111. Después del desplazamiento r a la derecha por 2 bits, y con 7, puede obtener una 0~7celda con un número.
Por lo tanto, en mapiternextla función, el recorrido comenzará desde la celda con el número it.offset de it.startBucket, y la clave y el valor se extraerán hasta que regrese al depósito inicial para completar el proceso transversal.
La parte del código fuente es relativamente fácil de entender, especialmente después de comprender las secciones de código comentadas anteriormente, no hay presión para leer esta parte del código. Entonces, a continuación, explicaré gráficamente todo el proceso transversal, esperando que sea claro y fácil de entender.
Supongamos que tenemos un mapa como se muestra en la siguiente figura. Inicialmente, B = 1 y hay dos depósitos. Luego, se activa la expansión (no entre en las condiciones de expansión aquí, es solo una configuración), y B se convierte en 2. . Además, el contenido del depósito n.º 1 se ha movido al nuevo depósito, 1 号dividiéndolo en 1 号suma 3 号; 0 号el depósito aún no se ha movido. El cubo viejo cuelga del *oldbucketspuntero y el cubo nuevo cuelga del *bucketspuntero.
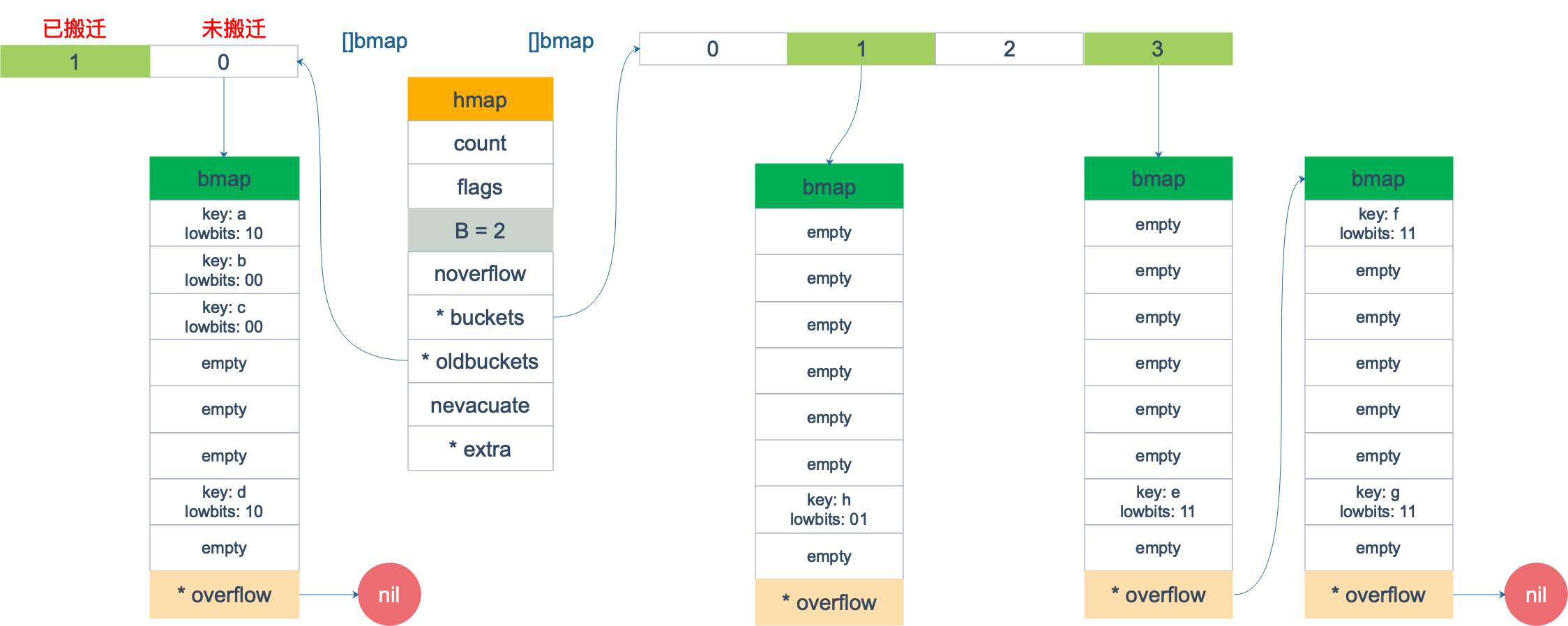
En este momento, atravesamos este mapa. Supongamos que después de la inicialización, startBucket = 3, offset = 2. Por lo tanto, el punto de partida del recorrido será la celda No. 2 del depósito No. 3. La siguiente imagen es el estado cuando comienza el recorrido:
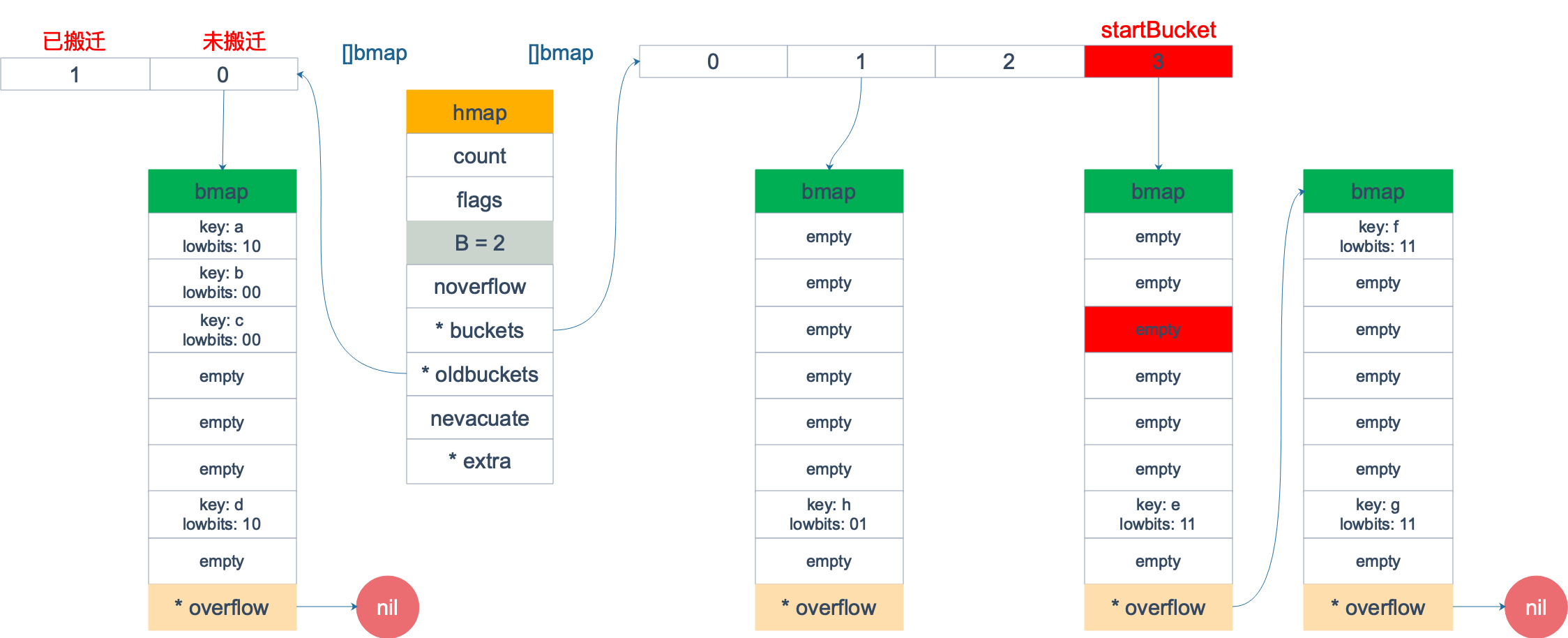
El marcado en rojo indica la posición inicial y el orden de recorrido del cubo es: 3 -> 0 -> 1 -> 2.
Dado que el depósito n.° 3 corresponde al antiguo depósito n.° 1, primero verifique si el antiguo depósito n.° 1 ha sido reubicado. El método de juicio es:
func evacuated(b *bmap) bool {
h := b.tophash[0]
return h > empty && h < minTopHash
}
Si el valor de b.tophash[0] está dentro del rango de valores de la bandera, es decir, en el intervalo (0,4), significa que ha sido reubicado.
empty = 0
evacuatedEmpty = 1
evacuatedX = 2
evacuatedY = 3
minTopHash = 4
En este ejemplo, se ha movido el antiguo cubo número 1. Por lo tanto, su valor de tophash[0] está en el rango de (0,4), por lo que solo es necesario atravesar el nuevo depósito número 3.
Recorra las celdas del depósito n.° 3 en secuencia y encontrará la primera clave que no esté vacía: elemento e. En este punto, la función mapiternext regresa y nuestro resultado transversal solo tiene un elemento:

Dado que la clave devuelta no está vacía, se seguirá llamando a la función mapiternext.
Continúe atravesando desde el último lugar atravesado y encuentre el elemento f y el elemento g del nuevo cubo de desbordamiento No. 3.
Atravesar el conjunto de resultados también crece:

Después de atravesar el nuevo cubo N° 3, regresa al nuevo cubo N° 0. El depósito No. 0 corresponde al antiguo depósito No. 0. Después de la verificación, el antiguo depósito No. 0 no se ha reubicado, por lo que el recorrido del nuevo depósito No. 0 se cambia al antiguo depósito No. 0. ¿Eso significa sacar todas las llaves del viejo cubo número 0?
No es tan simple. Recuerde que el antiguo depósito No. 0 se dividirá en dos depósitos después de la reubicación: el nuevo No. 0 y el nuevo No. 2. Lo que estamos atravesando en este momento es solo el nuevo depósito número 0 (tenga en cuenta que los recorridos son todos *bucketpunteros de recorrido, que son los llamados nuevos depósitos). Por lo tanto, solo sacaremos aquellas claves del antiguo depósito n.º 0 que estén asignadas al nuevo depósito n.º 0 después de la fisión.
Por lo tanto, lowbits == 00se recorrerá el conjunto de resultados:

Al igual que en el proceso anterior, continúe atravesando el nuevo depósito No. 1 y descubra que se ha movido el antiguo depósito No. 1. Solo necesita atravesar los elementos existentes en el nuevo depósito No. 1. El conjunto de resultados se convierte en:

Continúe atravesando el nuevo depósito No. 2, que proviene del antiguo depósito No. 0, por lo que necesitamos las llaves en el antiguo depósito No. 0 que se fusionarán en el nuevo depósito No. 2, es decir, esas llaves de lowbit == 10.
De esta forma, recorrer el conjunto de resultados se convierte en:

Finalmente, cuando el recorrido continúa hasta el nuevo depósito número 3, se descubre que se han atravesado todos los depósitos y se completa todo el proceso de iteración.
Por cierto, si encuentra una clave math.NaN()como esta, el método de procesamiento es similar. El núcleo todavía depende de en qué cubo cae después de dividirse. Basta con mirar la parte más baja de su hash superior. Si el bit más bajo del hash superior es 0, se asigna a la parte X; si es 1, se asigna a la parte Y. En base a esto, decida si eliminar la clave y colocarla en el conjunto de resultados transversales.
El núcleo del recorrido del mapa es comprender que cuando se duplica la capacidad, el depósito anterior se dividirá en dos depósitos nuevos. La operación transversal se realizará en el orden del número de serie del nuevo depósito. Cuando el depósito anterior no se mueve, la clave que se moverá al nuevo depósito en el futuro debe encontrarse en el depósito anterior.