1. ¿Qué es DStream?
-
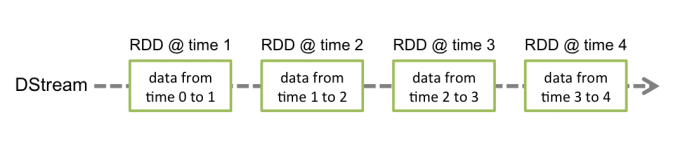
Flujo discreto es la abstracción básica de Spark Streaming, que representa un flujo de datos continuo y el flujo de datos de resultado después de varias operaciones del operador Spark.
-
Internamente, DStream está representado por una serie de RDD continuos . Cada RDD contiene datos durante un período de tiempo
-
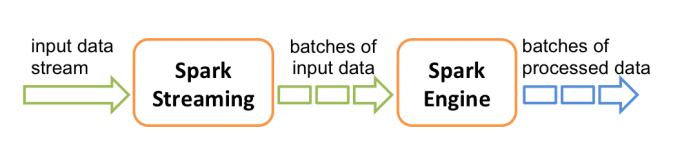
El diagrama de flujo de trabajo es el siguiente: Después de recibir los datos en tiempo real, divida los datos en lotes y luego páselos a Spark Engine para procesar el resultado final del lote.
2. Resumen de operadores relacionados con DStream
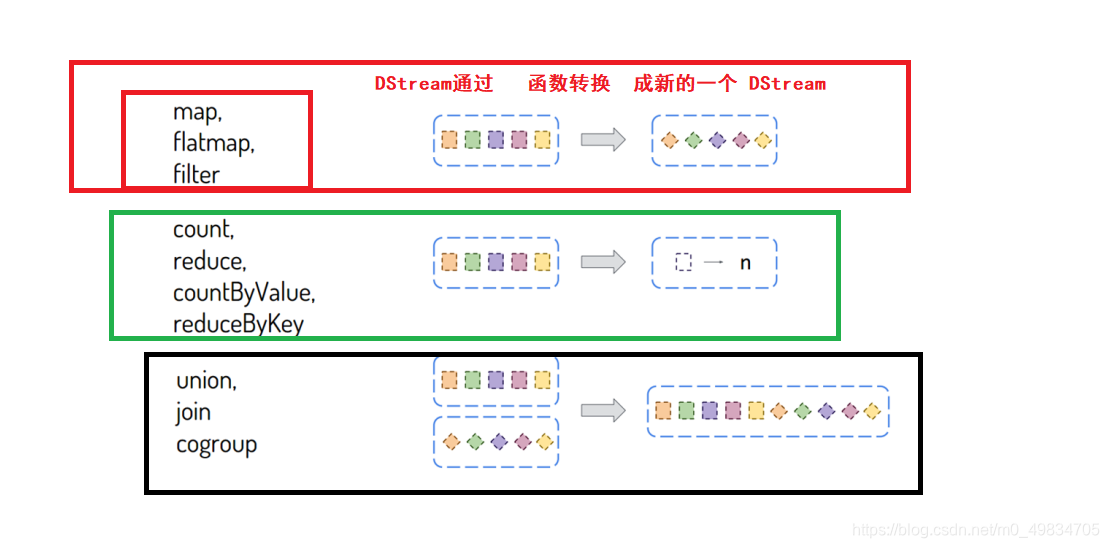
- Función de conversión [Operador de conversión de transformación]: convierte un DStream en otro DStream
- Nota:
- 1-El operador de transformación de SparkStreaming es relativamente limitado, pero a veces aún necesita ser utilizado
- Por ejemplo, es necesario ordenar los resultados del recuento de palabras. No existe el operador sortBy o sortByKey.
- Por lo tanto, con la ayuda del método de transformación, los datos de DStream se convierten en RDD para su funcionamiento

- Función de salida [Operador de acción de operaciones de salida]: envía un DStream a un sistema de almacenamiento externo
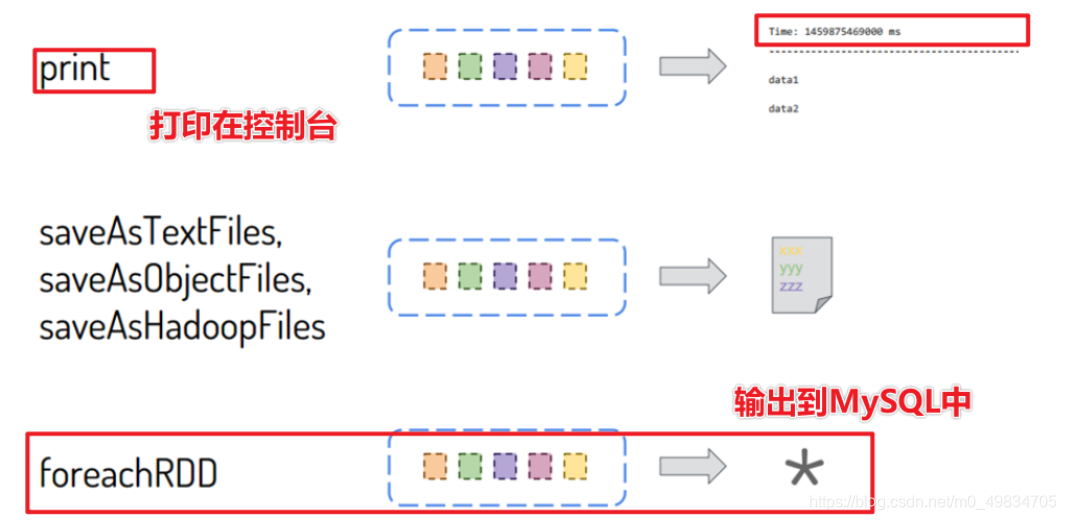
En el desarrollo real de la empresa SparkStreaming, se recomienda que aquellos que pueden operar en RDD no deben operar en DStream. Cuando llame a una función en DStream que también existe en RDD, use la operación RDD.
3. Objeto StreamingContext
- 1) Estructura de
datos SparkCore : RDD
SparkContext: objeto de instancia de contexto - 2) Estructura de
datos SparkSQL : Dataset / DataFrame = RDD + Schema
SparkSession: objeto de instancia de sesión, SQLContext / HiveContext en Spark 1.x - 3) Estructura de
datos SparkStreaming : DStream = Seq [RDD]
StreamingContext: Objeto de instancia de contexto de transmisión, la capa inferior o
parámetro SparkContext : dividir el intervalo de tiempo de datos de transmisión BatchInterval: 1s, 5s (demostración)
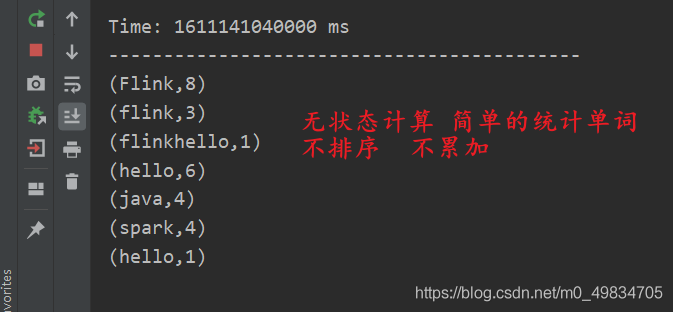
4. El operador de DStream se da cuenta del caso de cálculo de recuento de palabras en tiempo real
Simule el socket TCP para realizar un cálculo simple del recuento de palabras en tiempo real
import org.apache.spark.streaming.dstream.{
DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{
Seconds, StreamingContext}
import org.apache.spark.{
SparkConf, SparkContext}
/**
* @author liu a fu
* @date 2021/1/20 0020
* @version 1.0
* @DESC 第一个SparkStreaming wordcount案例 不会累加(称之为无状态计算)
*
* 1-首先声明StreamingContext申请资源,进入调用sparkContext
* 2-这里从socket接受数据,从node1节点下安装nc服务,使用nc -lk 9999端口发送数据**
* 3-将接受到的数据进行Tranformation转换
* 4-使用OutPutOpration操作输出结果
* 5-开启start,streamingcontext.start开启接受数据
* 6-指导StreamingContext.awaitTermination停止
* 7-StreamingContext.stop
*/
object _01StreamingCompution {
def main(args: Array[String]): Unit = {
//1-首先声明StreamingContext申请资源,进入调用sparkContext
val conf: SparkConf = new SparkConf()
.setMaster("local[8]")
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(5)) //每经过5秒处理一次数据
sc.setLogLevel("WARN")
//2-这里从socket接受数据,从node1节点下安装nc服务,使用nc -lk 9999端口发送数据
val receiveDS: ReceiverInputDStream[String] = ssc.socketTextStream("node1", 9999) //指定主机和端口
//3-将接受到的数据进行Tranformation转换
val resultDS: DStream[(String, Int)] = receiveDS
.flatMap(_.split("\\s+"))
.map((_, 1))
.reduceByKey(_ + _)
//4-使用OutPutOpration操作输出结果-----------print属于类似于action算子的
resultDS.print()
//5-开启start,streamingcontext.start开启接受数据
ssc.start() //Start the execution of the streams.
//6-指导StreamingContext.awaitTermination停止,有任何的异常都会触发停止
ssc.awaitTermination()
//7-StreamingContext.stop
ssc.stop()
}
}
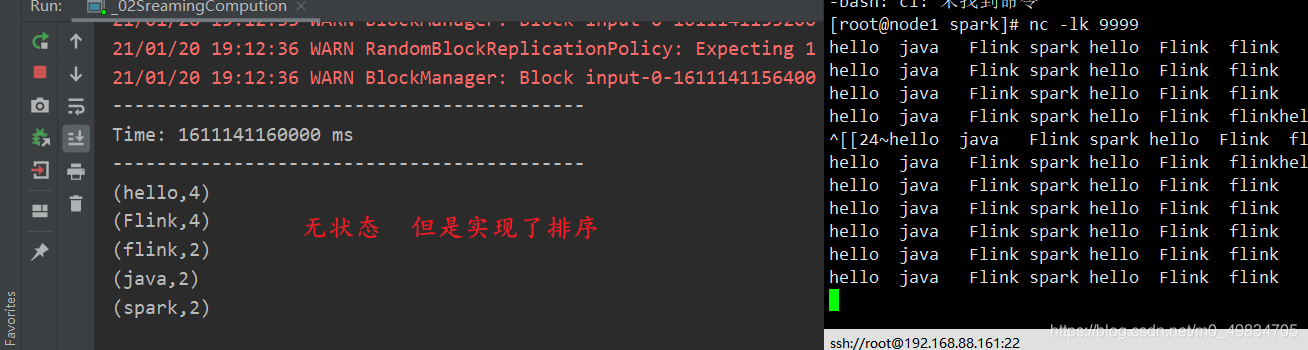
Simular TCP para implementar la clasificación ( operador de conversión de transformación + implementación sortBy )
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{
DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{
Seconds, StreamingContext}
import org.apache.spark.{
SparkConf, SparkContext}
/**
* @author liu a fu
* @date 2021/1/20 0020
* @version 1.0
* @DESC 实现wordcount统计后的排序输出
*/
object _02SreamingCompution {
def main(args: Array[String]): Unit = {
//1-首先声明StreamingContext申请资源,进入调用sparkContext
val conf: SparkConf = new SparkConf().setAppName(this.getClass.getSimpleName.stripSuffix("$")).setMaster("local[3]")
val sc = new SparkContext(conf)
val scc = new StreamingContext(sc, Seconds(5))
sc.setLogLevel("WARN")
//2-这里从socket接收数据
val reviceDS: ReceiverInputDStream[String] = scc.socketTextStream("node1", 9999)
//3-将接收的数据进行Tranformation转换
val resultDS: DStream[(String, Int)] = reviceDS
.flatMap(_.split("\\s+"))
.map((_, 1))
.reduceByKey(_ + _)
//实现排序操作
val output: DStream[(String, Int)] = resultDS.transform(iter => {
val valueRDD: RDD[(String, Int)] = iter.sortBy(_._2, false) //按照第二个进行排序 value
valueRDD
})
//4-使用OutPutOpration操作输出结果-----------print属于类似于action算子的
output.print()
//5-开启start,streamingcontext.start开启接受数据
scc.start()
scc.awaitTermination()
scc.stop()
}
}
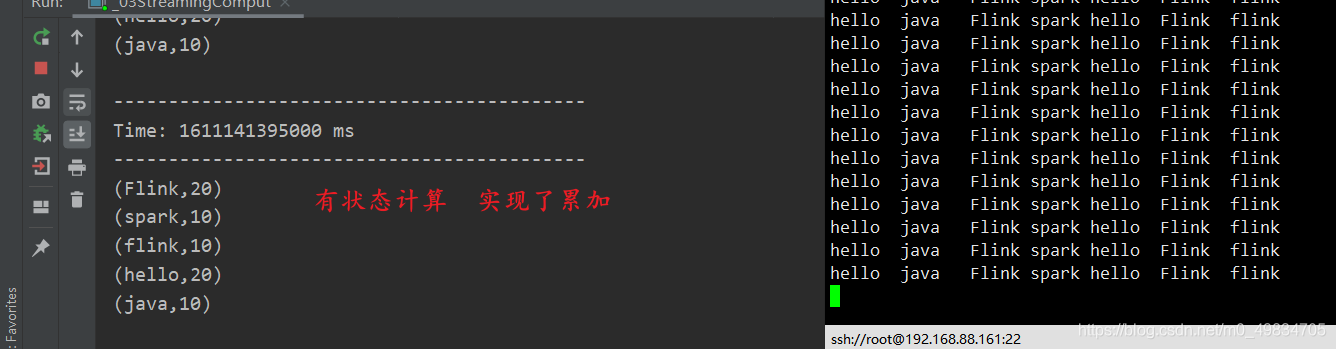
TCP implementa la acumulación con estado (método de definición de operador updateStateByKey)
import org.apache.spark.streaming.dstream.{
DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{
Seconds, StreamingContext}
import org.apache.spark.{
SparkConf, SparkContext}
/**
* @author liu a fu
* @date 2021/1/20 0020
* @version 1.0
* @DESC SparkStreaming wordcount案例 会累加(称之为有状态计算)
*/
object _03StreamingComput {
/**
* 这里自己定义的一个方法用于累加 和 判断历史值是否存在
* @param currentValue 这里是当前的值,需要是用sum累加
* @param historyValue 这里是历史的值,判断历史的值是否存在,如果存在直接使用,如果不存在赋值为0
* @return
*/
def updateFunc(currentValue:Seq[Int],historyValue:Option[Int]):Option[Int] = {
val addSum = currentValue.sum + historyValue.getOrElse(0)
Option(addSum)
}
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName(this.getClass.getSimpleName.stripSuffix("$")).setMaster("local[5]")
val sc = new SparkContext(conf)
val scc = new StreamingContext(sc, Seconds(5))
sc.setLogLevel("WARN")
scc.checkpoint("data/checkpoint/check001")
2-这里从socket接受数据,从node1节点下安装nc服务,使用nc -lk 9999端口发送数据
val reviceDS: ReceiverInputDStream[String] = scc.socketTextStream("node1", 9999)
//3-将接受到的数据进行Tranformation转换
val resultDS: DStream[(String, Int)] = reviceDS
.flatMap(_.split("\\s+"))
.map((_, 1))
.updateStateByKey(updateFunc)
//4-使用OutPutOpration操作输出结果-----------print属于类似于action算子的
resultDS.print()
//5-开启start,streamingcontext.start开启接受数据
scc.start() //Start the execution of the streams.
//6-指导StreamingContext.awaitTermination停止,有任何的异常都会触发停止
scc.awaitTermination()
scc.stop()
}
}
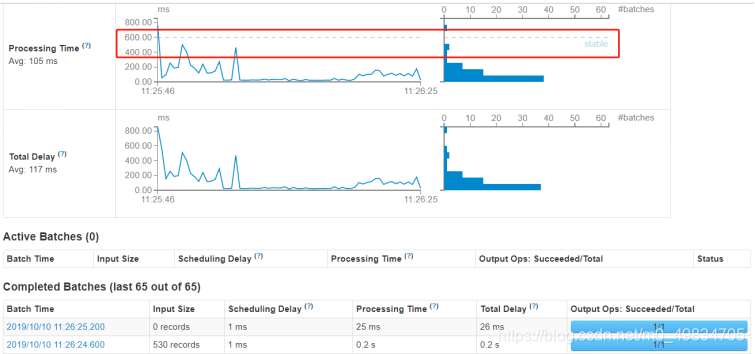
5. Interfaz de supervisión de aplicaciones
Ejecute el caso de estadísticas de frecuencia de palabras anterior e inicie sesión en la página de monitoreo WEB UI: http: // localhost: 4040 para ver la información de monitoreo relacionada.
-
En primer lugar, transmisión de información de resumen de la aplicación de transmisión El
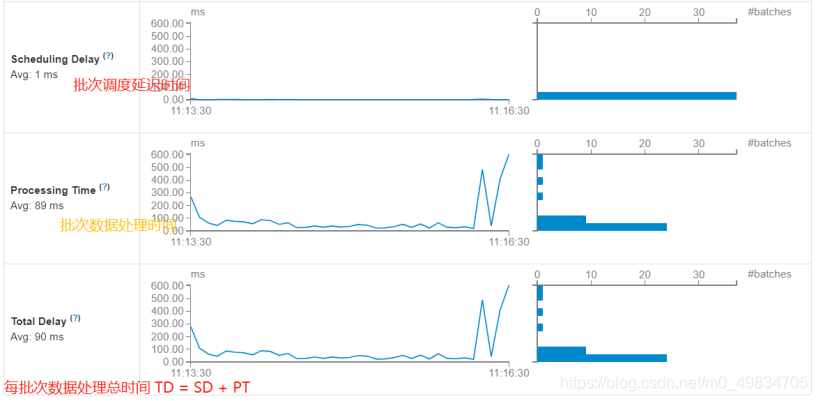
tiempo total de procesamiento de cada lote de datos de lote TD = tiempo de retardo de programación de lote SD + tiempo de procesamiento de datos de lote PT.

-
Estándar de medición de
rendimiento Estándar de rendimiento de procesamiento de datos en tiempo real SparkStreaming:
cada lote de tiempo de procesamiento de datos TD <= BatchInterval cada intervalo de tiempo de lote