Conocimientos preliminares de los rastreadores
1. Base del protocolo de red informática
Un proceso de solicitud de red completo es el siguiente:
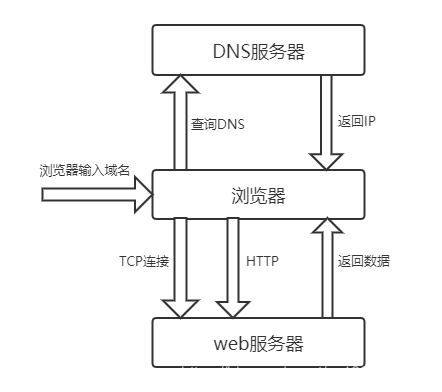
después de que el navegador ingresa el nombre de dominio, el navegador primero visita el servidor DNS, DNS devuelve la IP al navegador y luego el navegador establece una conexión TCP con el servidor web, el navegador puede enviar una solicitud http y el servidor web regresa Los datos se envían al navegador y el siguiente paso es que el navegador analice el contenido.
Protocolo de red de siete capas:
- Capa de aplicación
Http、ftp、pop3、DNS - Capa de presentación
- Capa de sesión
- Capa de transporte
TCP、UDP - Capa de red
ICMP、IP、IDMP - Capa de enlace de datos
ARP、RARP - Medio de transmisión física de la capa física
二 、 Html 、 Css 、 Javascript
Los tres elementos de una página web: Html、Css、Javascript
Htmles el esqueleto que lleva el contenido de la página web,
Csses el estilo
Javascriptde la página web , es el script que ejecuta la página web;
El contenido que necesitamos rastrear es generalmente parte del contenido HTML de la página web, por lo que podemos obtenerlo si está visible y podemos rastrearlo siempre que podamos verlo en la página.
Proceso de carga del navegador:
construya la carga del sub-recurso del árbol DOM (cargue css externo, js, imágenes y otros recursos externos), renderizado estilo (ejecución css)
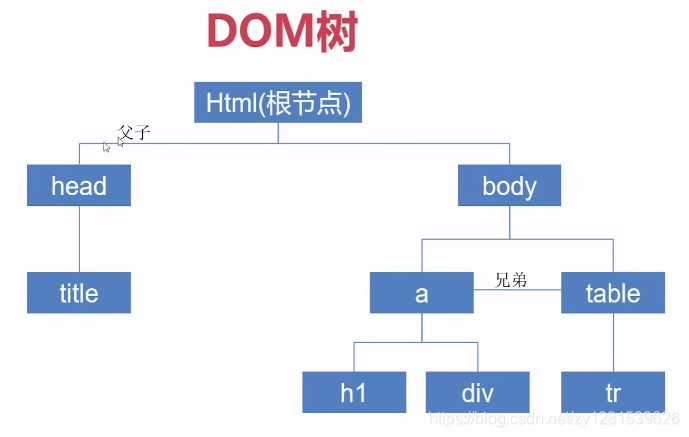
La búsqueda de elementos de página generalmente se encuentra a través del árbol DOM:
Carga asincrónica Ajax
Algunos datos se envían al servidor a través de js, y los datos se devuelven y los datos se insertan dinámicamente en la página a través de js. Este método no actualizará la página y el efecto de experiencia del usuario es bueno.
Los datos devueltos por ajax pueden estar en formato json o ser parte de una página html.
Páginas web dinámicas y páginas web estáticas:
dinámicas: los datos interactúan con el fondo y se pueden cambiar (ajax)
estática: los datos son inmutables (necesita modificar el código fuente si desea cambiar)
La experiencia de la página web dinámica es buena, carga parcial, buena para el servidor, buena escalabilidad
La página web estática es buena para SEO
Solicitud GET y solicitud POST
Los parámetros GET se incluyen en la URL y POST pasa los parámetros a través del cuerpo de la solicitud.
- GET es inofensivo cuando el navegador retrocede y POST enviará la solicitud nuevamente
- Las solicitudes GET solo se pueden codificar en URL, mientras que POST admite varios métodos de codificación
- Los parámetros transmitidos en la URL para las solicitudes GET tienen una longitud limitada, mientras que POST no
- GET es menos seguro que POST, porque los parámetros se exponen directamente en la URL, por lo que no se puede pasar información confidencial
3 tipos de contenido
-
application/x-www-form-urlencoded
POST envía los datos, el formulario nativo del navegador, si el atributo enctype no está configurado, los datos se enviarán finalmente en application / x-www-form-urlencoded. Los datos enviados se codifican de acuerdo con key1 = val1 & key2 = val2, y tanto key como val se transcodifican en URL. -
multipart/form-data
Archivo de carga de formulario. -
application/json
Dígale al servidor que el cuerpo del mensaje es una cadena JSON serializada.
Tres, el método básico para gatear
1. Clasificación del plan de cobranza
Generalmente, solo recopilamos los datos especificados requeridos por el sitio web de recopilación, y el esquema de recopilación se clasifica:
- Utilice el protocolo http para recopilar análisis de páginas
- Utilice la interfaz api para recopilar la recopilación de datos de la aplicación
- Utilice la colección de api del sitio web de destino: Weibo, github
2. biblioteca de solicitudes
Dirección del documento oficial: https://requests.readthedocs.io/zh_CN/latest/
Instalación:
pip install requests
Si utiliza un entorno virtual, asegúrese de volver a instalarlo en el entorno virtual para garantizar el funcionamiento normal del proyecto utilizando el entorno virtual.
En primer lugar, rastree la página de Baidu:
import requests
res = requests.get("http://www.baidu.com")
print(res.text)
Se imprime el código html de la página de Baidu: los

elementos específicos se presentarán en detalle más adelante.
3. Expresiones regulares
Las expresiones regulares son para un mejor procesamiento de las cadenas obtenidas y más convenientes para obtener los caracteres que necesitamos.
Sintaxis regular de uso común:
| gramática | efecto |
|---|---|
| . | Coincidir con cualquier carácter (sin incluir la nueva línea) |
| ^ | Coincidir con la posición de inicio, coincidir con el comienzo de cada línea en modo multilínea |
| PS | Coincidir con la posición final, coincidir con el final de cada línea en modo multilínea |
| * | Coincide con el metacarácter anterior 0 o más veces |
| + | Coincide con el metacarácter anterior una o más veces |
| ? | Coincide con el metacarácter anterior de 0 a 1 veces |
| {Minnesota} | Coincide con el metacarácter anterior m an veces |
| \\ | Personaje de escape |
| [] | conjunto de caracteres |
| | | OR lógico |
| \segundo | Coincidir con una cadena vacía al principio o al final de una palabra |
| \SEGUNDO | Coincidir con una cadena vacía que no esté al principio o al final de una palabra |
| \re | Coincidir con un número |
| \RE | Coincidir sin dígitos |
| \ s | Coincidir con cualquier espacio en blanco |
| \ S | Coincidir con espacios en blanco no arbitrarios |
| \ w | Coincide con cualquier carácter entre números, letras y guiones bajos |
| \ W | Coincide con cualquier carácter que no sean números, letras y guiones bajos |
Python usa regular para extraer cumpleaños simplemente:
import re
info = "姓名:zhangsan 生日:1995年12月12日 入职日期:2020年12月12日"
# print(re.findall("\d{4}", info))
match_result = re.match(".*生日.*?(\d{4})", info)
print(match_result.group(1)) # 1995
4. Uso de Beautifulsoup
- Instalación
(si está utilizando un entorno virtual, debe cambiar al entorno virtual para la instalación)
pip install beautifulsoup4
- Documento oficial
https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/ - Fácil de usar
from bs4 import BeautifulSoup
import requests
baidu = requests.get("http://www.baidu.com")
baidu.encoding = "utf-8"
bs = BeautifulSoup(baidu.text, "html.parser")
title = bs.find("title")
print(title.string)
navs = bs.find_all("img")
for i in navs:
print(i)
resultado:

5. Sintaxis básica de Xpath
Aquí presentamos principalmente Selector.
Instalación:
descarga del paquete de Python: https://www.lfd.uci.edu/~gohlke/pythonlibs/
Si lo instala directamente lxmlo si la scrapyinstalación no se realiza correctamente, puede ir al sitio web anterior para descargar el paquete de instalación y luego pipinstalarlo:
pip install lxml
pip install Twisted-20.3.0-cp38-cp38-win32.whl
pip install Scrapy-1.8.0-py2.py3-none-any.whl
xpath usa expresiones de ruta para navegar en xml y html.


Uso simple:
import requests
from scrapy import Selector
baidu = requests.get("http://www.baidu.com")
baidu.encoding = "utf-8"
html = baidu.text
sel = Selector(text=html)
tag = sel.xpath("//*[@id='lg']/img").extract()[0]
print(tag)
# <img hidefocus="true" src="//www.baidu.com/img/bd_logo1.png" width="270" height="129">
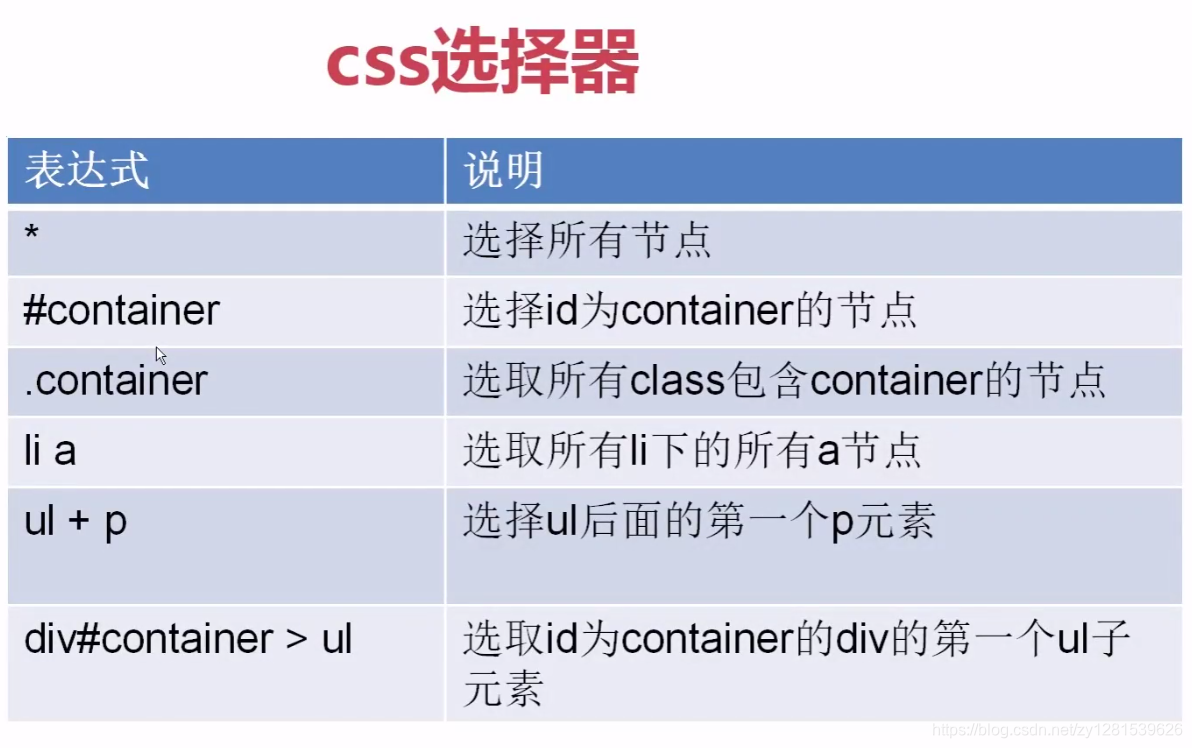
6. Selector de CSS para extraer elementos
import requests
from scrapy import Selector
baidu = requests.get("http://www.baidu.com")
baidu.encoding = "utf-8"
html = baidu.text
sel = Selector(text=html)
imgs = sel.css("img").extract()
for i in imgs:
print(i)
# <img hidefocus="true" src="//www.baidu.com/img/bd_logo1.png" width="270" height="129">
# <img src="//www.baidu.com/img/gs.gif">