1. Introducción a ARIMA
1. Introducción
El nombre completo se llama modelo ARIMA de modelo de media móvil autorregresiva , nombre completo (ARIMA, modelo de media móvil integrado autorregresivo ). Es el tipo más común de modelo estadístico (modelo estadístico) utilizado para el pronóstico de series de tiempo. El modelo es muy simple, solo se necesitan variables endógenas y no se necesitan otras variables exógenas.
2. Introducción del modelo
1. Modelo autorregresivo (RA)
Describe la relación entre el valor actual y el valor histórico, y usa los datos históricos de tiempo de la propia variable para predecirse a sí misma. El modelo autorregresivo debe cumplir con los requisitos de estacionariedad. La fórmula para el proceso autorregresivo de orden p se define como:

![]() Es el valor actual,
Es el valor actual, ![]() es un término constante, P es el orden,
es un término constante, P es el orden, ![]() es el coeficiente de autocorrelación y
es el coeficiente de autocorrelación y ![]() es el error. Sin embargo, si desea utilizar un modelo autorregresivo, existen algunas restricciones de la siguiente manera:
es el error. Sin embargo, si desea utilizar un modelo autorregresivo, existen algunas restricciones de la siguiente manera:
- El modelo autorregresivo usa sus propios datos para hacer predicciones;
- Debe tener estabilidad ;
- Debe tener autocorrelación , si el coeficiente de autocorrelación (φi) es menor a 0.5, no debe ser adoptado;
- La autorregresión solo es adecuada para predecir fenómenos relacionados con el período anterior .
2. Modelo de media móvil (MA)
El modelo de media móvil se centra en la acumulación de términos de error en el modelo autorregresivo.La definición de fórmula del proceso autorregresivo de orden q:
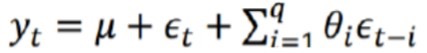
El método de media móvil puede eliminar eficazmente las fluctuaciones aleatorias en la predicción.
3. Modelo de media móvil autorregresiva (ARMA)
El modelo ARIMA (p, d, q) se denomina modelo de promedio móvil autorregresivo diferencial (Modelo de promedio móvil integrado autorregresivo , abreviado como ARIMA). De hecho, es una combinación de media móvil y autorregresiva.
Lo que hace el modelo ARIMA es: transformar una serie de tiempo no estacionaria en una serie de tiempo estacionaria, y luego hacer una regresión de la variable dependiente solo en su valor de retraso y el valor presente y valor de retraso del término de error aleatorio para establecer un modelo. La fórmula se define como:

AR es autorregresivo, p es un término autorregresivo, MA es la media móvil, q es el número de términos de media móvil yd es el número de diferencias realizadas cuando la serie temporal se vuelve estacionaria.
3. Función de autocorrelación
1. Función de autocorrelación ACF
Una secuencia ordenada de variables aleatorias se compara consigo misma y la función de autocorrelación refleja la correlación entre los valores de la misma secuencia en diferentes series de tiempo. La fórmula dice:

El rango de valores de Pk es [-1,1].
2. Función de autocorrelación parcial (PACF)
Para un modelo AR (p) estacionario, cuando se calcula el coeficiente de autocorrelación p (k) del rezago k, en realidad no es una correlación pura entre x (t) yx (tk). x (t) también se verá afectado por las k-1 variables aleatorias del medio x (t-1), x (t-2), ..., x (t-k + 1) y estas k-1 variables aleatorias Todas las variables tienen una correlación con x (tk), por lo que el coeficiente de autocorrelación p (k) está realmente mezclado con la influencia de otras variables en x (t) y x (tk).
En otras palabras, ACF también contiene la influencia de otras variables, y el coeficiente de autocorrelación parcial PACF es estrictamente la correlación entre estas dos variables. Después de que PACF elimina la interferencia de k-1 variables aleatorias x (t-1), x (t-2), ..., x (t-k + 1), la influencia de x (tk) en x (t) Relevancia.
2. Adquisición de datos
Los datos bursátiles utilizan la interfaz API (pandas-datareader) proporcionada por Yahoo Finance, y el paquete de guía es el siguiente:
%matplotlib inline
import pandas as pd
import pandas_datareader
import datetime
import matplotlib.pylab as plt
import seaborn as sns
from matplotlib.pylab import style
from statsmodels.tsa.arima_model import ARIMA
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
import statsmodels.tsa.api as smt
#设置字体、图形样式
%config InlineBackend.figure_format = 'retina'
sns.set_style("whitegrid")
plt.rcParams['font.sans-serif'] = [u'SimHei']
plt.rcParams['axes.unicode_minus'] = False
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']Lo que obtuve aquí son los datos de existencias de Taiji Industrial, el código de existencias es 600667.SS y el período de datos es de 2019 hasta el presente.
start = pd.datetime(2019, 1, 1)
end = pd.datetime.today()
stock = pandas_datareader.DataReader('600667.SS', 'yahoo', start, end)
stock.head()
Entre ellos, Close es el valor neto del día. Primero veamos la tendencia de los datos.
stock_train.plot(figsize=(12,8))
plt.legend(bbox_to_anchor=(1.25, 0.5))
plt.title("Stock Close")
sns.despine()
Aquí hay un día como una unidad, complete los datos que faltan (el mercado está cerrado), completo el valor lineal aquí
stock_train = stock_train.resample('D').interpolate('linear')
stock_train.plot(figsize=(12,8))
plt.legend(bbox_to_anchor=(1.25, 0.5))
plt.title("Stock Close")
sns.despine()
Necesitamos comprender los datos en profundidad y ser más intuitivos,
def tsplot(y, lags=None, title='', figsize=(14, 8)):
fig = plt.figure(figsize=figsize)
layout = (2, 2)
ts_ax = plt.subplot2grid(layout, (0, 0))
hist_ax = plt.subplot2grid(layout, (0, 1))
y.plot(ax=ts_ax)
ts_ax.set_title(title)
y.plot(ax=hist_ax, kind='hist', bins=25)
hist_ax.set_title('Histogram')
sns.despine()
plt.tight_layout()
return ts_ax, acf_ax, pacf_ax
tsplot(stock_train, title='Consumer Sentiment', lags=36)
3. Procesamiento previo de datos
De acuerdo con la visualización de datos anterior, se puede ver que la distribución de datos no es estable, es decir, no es uniforme. Al realizar el procesamiento de diferencias, los datos de diferencia de cada orden se pueden dibujar como un diagrama de dispersión, de la siguiente manera:
lags=9
ncols=3
nrows=int(np.ceil(lags/ncols))
fig, axes = plt.subplots(ncols=ncols, nrows=nrows, figsize=(4*ncols, 4*nrows))
for ax, lag in zip(axes.flat, np.arange(1,lags+1, 1)):
lag_str = 't-{}'.format(lag)
X = (pd.concat([stock_train, stock_train.shift(-lag)], axis=1,
keys=['y'] + [lag_str]).dropna())
X.plot(ax=ax, kind='scatter', y='y', x=lag_str);
corr = X.corr().as_matrix()[0][1]
ax.set_ylabel('Original')
ax.set_title('Lag: {} (corr={:.2f})'.format(lag_str, corr));
ax.set_aspect('equal');
sns.despine();
fig.tight_layout();
Según el diagrama de dispersión, conozca la primera diferencia (en línea recta).
stock_diff = stock_train.diff()
stock_diff = stock_diff.dropna()
plt.figure()
plt.plot(stock_diff)
plt.title('一阶差分')
plt.show()

Básicamente, es bastante estable. Los datos fluctúan mucho de febrero a marzo. Debido a la epidemia, es mejor eliminar esta parte de los datos, pero no iré aquí. Cuando presenté el modelo ARMA anteriormente, expliqué los parámetros p, q y d. Obviamente, d es 1 aquí. Entonces, ¿cómo se determinan pyq? A determinar de acuerdo con ACF y PACF, las reglas específicas son las siguientes:

Censurando, dentro del intervalo de confianza, el 95% de los puntos cumplen la regla. Primero tenemos que dibujar la gráfica de acf y pacf,
fig = plt.figure(figsize=(12,8))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(stock_diff, lags=20,ax=ax1)
ax1.xaxis.set_ticks_position('bottom')
fig.tight_layout();
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(stock_diff, lags=20, ax=ax2)
ax2.xaxis.set_ticks_position('bottom')
fig.tight_layout();
De acuerdo con las reglas anteriores, primero determine el orden de q. Observe el diagrama acf. La parte sombreada representa la parte truncada, es decir, desde qué orden entrar a la sombra, se puede ver en el diagrama que es de orden 2, y en este momento pacf también tiende a Casi cero. Para determinar el orden de p, observe el diagrama de pacf, se puede ver que después de que se satisface el orden 2, en este momento acf también está cerca de 0.
Cuarto, entrenamiento de modelos
model = ARIMA(stock_train, order=(2, 1, 2),freq='D') # p,d,q
result = model.fit()
result.summary()
A continuación, se utiliza el modelo entrenado para predecir la tendencia desde 2019-08-01 hasta 2020-10-01:
pred = result.predict('20190801', '20201001',dynamic=True, typ='levels')
plt.figure(figsize=(6, 6))
plt.xticks(rotation=45)
plt.plot(pred)
plt.plot(stock_train)
La línea azul es el valor real y la línea roja es el valor predicho, que parece inútil. Finalmente, observe la distribución de los valores predichos:

En esencia, ARIMA solo puede capturar relaciones lineales, pero no relaciones no lineales. En otras palabras, el uso del modelo ARIMA para predecir datos de series de tiempo debe ser estable, si los datos no son estables, la ley no se puede capturar. Los datos de acciones son inestables y, a menudo, fluctúan bajo la influencia de políticas y noticias, por lo que el efecto no es bueno. Puede ser mejor usar algunos cambios en los términos de búsqueda de Google para extraer algunas características y luego usar el modelo de árbol para predecir. Vuelva a intentarlo más tarde.