Base de datos no relacional NoSQL
Concepto NoSQL
No solo SQL: no solo SQL, se refiere a bases de datos no relacionales, es un complemento útil para las bases de datos relacionales. Los datos finales todavía se almacenan en una base de datos relacional. Las bases de datos no relacionales se utilizan principalmente para mejorar la velocidad de consulta de la base de datos y generalmente se utilizan como caché de datos.
Base de datos no relacional

Una base de datos no relacional no es estrictamente una base de datos, debe ser una colección de métodos de almacenamiento estructurados de datos, que pueden ser documentos o pares clave-valor.
ventaja
- Formato flexible: el formato de los datos almacenados puede ser clave, valor, documento, imagen, etc. Es flexible de usar y tiene una amplia gama de escenarios de aplicación, mientras que las bases de datos relacionales solo admiten tipos básicos.
- Velocidad rápida: Nosql puede usar el disco duro o la RAM como portadora, mientras que las bases de datos relacionales solo pueden usar el disco duro;
- Bajo costo: la base de datos nosql es fácil de implementar y es básicamente un software de código abierto.
Desventaja
- No proporciona soporte sql, el costo de aprendizaje y uso es alto;
- La estructura de datos es relativamente compleja e inconveniente para consultas complejas.
Por que usar NOSQL
El rendimiento específico es la solución a los siguientes tres grandes problemas:
Acceso concurrente de alto rendimiento a la base de datos
Al mismo tiempo, existen accesos concurrentes por parte de un gran número de usuarios. A menudo llega a decenas de miles de solicitudes de lectura y escritura por segundo. Las bases de datos relacionales apenas pueden manejar decenas de miles de consultas SQL, pero la E / S del disco duro ya no puede manejar decenas de miles de solicitudes de datos de escritura SQL.
-
Por ejemplo, el Double 11 de Tmall, de 0 a. M. A 2 a. M., Ha alcanzado decenas de millones de visitas por segundo.
-
Durante el Festival de Primavera de 12306, los usuarios siguieron comprobando si quedaban boletos cuando regresaron a casa para comprar boletos de tren durante el Año Nuevo.
Gran almacenamiento: gran almacenamiento de datos
La cantidad de datos en la base de datos es extremadamente grande y todos los días se generan cantidades masivas de datos en las tablas de la base de datos.
Al igual que QQ, WeChat y Weibo, los usuarios generan dinámicas de usuario masivas todos los días, generando decenas de millones de registros todos los días. Para las bases de datos relacionales, realizar consultas SQL en una tabla con cientos de millones de registros es extremadamente ineficiente e incluso intolerable.
Alta escalabilidad y alta disponibilidad: requisitos de alta escalabilidad y alta disponibilidad
La expansión y actualización de bases de datos relacionales es problemática. Para muchos sitios web que necesitan brindar un servicio ininterrumpido las 24 horas, es muy doloroso actualizar y expandir el sistema de base de datos, que a menudo requiere tiempo de inactividad para el mantenimiento y la migración de datos.
Las bases de datos no relacionales se pueden expandir agregando constantemente nodos de servidor, sin necesidad de mantener la base de datos original.
Archivo de catálogo de Redis
| Directorio o archivo | efecto |
|---|---|
| redis-benchmark.exe | Un comando de herramienta para pruebas de rendimiento |
| redis-check-aof.exe | Herramienta de inspección y reparación de archivos AOF (AOF es uno de sus formatos de almacenamiento de archivos) |
| redis-check-dump.exe | Herramienta de inspección y modificación de archivos RDB (RDB es uno de sus formatos de almacenamiento de archivos) |
| redis-cli.exe | Lanzador de clientes |
| redis-server.exe | Programa de inicio del lado del servidor (no se iniciará automáticamente, por defecto debe iniciarse manualmente cada vez) |
| redis.window.conf | Archivo de configuración del servidor |
comando de operación de tipo cadena
5 tipos de datos de Redis
Redis es un sistema de almacenamiento de clave-valor avanzado, donde el valor admite cinco tipos de datos, en referencia al tipo de su valor, y la clave se puede considerar como un tipo de cadena. Redis no está escrito en Java, está escrito en lenguaje C.
| El tipo de datos del valor | Descripción |
|---|---|
| tipo de cuerda | Cuerda |
| tipo de lista | Lista: los elementos se pueden repetir y los elementos se indexan y ordenan |
| establecer tipo | Colección: Los elementos no son repetibles, los elementos no tienen número de índice ni orden. |
| tipo hash | El valor consta de varios pares clave-valor |
| tipo zset | Colección: los elementos no son repetibles, cada elemento tiene un número de índice y un valor de puntuación, que se puede clasificar según la puntuación. |
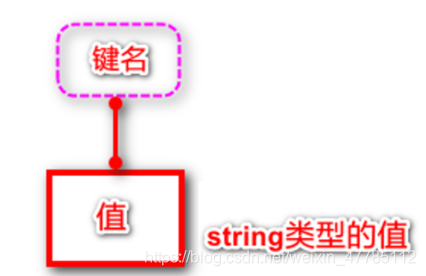
Cadena tipo cadena
Almacenado en binario en Redis, no hay proceso de codificación y decodificación.
Ya sea de tipo cadena, entero o punto flotante, se escribirá como una cadena.
La longitud máxima de datos que puede contener el valor del tipo de cadena en Redis es 512M, que es el tipo de datos más utilizado en el futuro.
Comandos comunes
| mando | Caracteristicas |
|---|---|
| establecer valor clave | Almacene la clave y el valor del tipo de cadena, si la clave no existe, agréguela, si existe, modifíquela |
| valor de la clave setnx | Si la clave no existe, agréguela. Si no existe, no haga nada y no sobrescribirá la clave y el valor anteriores. |
| obtener la clave | Obtenga valor por clave |
| del 键 | Eliminar clave y valor por clave |
Comandos de operación de tipo lista
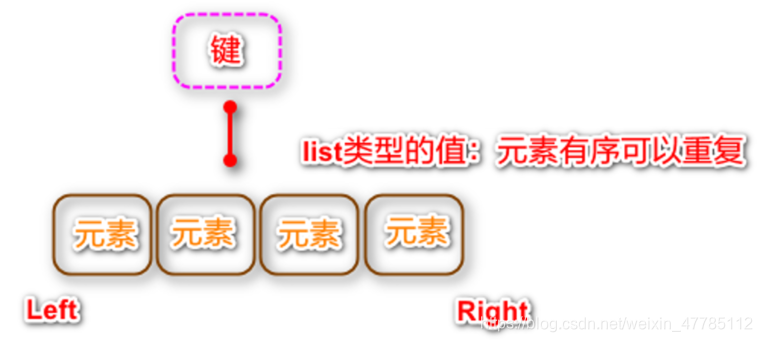
Visión de conjunto
En Redis, el tipo Lista es una lista vinculada de cadenas ordenadas en el orden de inserción. Como una lista enlazada normal en una estructura de datos, podemos agregar nuevos elementos a su izquierda y derecha.
Al insertar, si la clave no existe, Redis creará una nueva lista vinculada para la clave.
Si se eliminan todos los elementos de la lista vinculada, la clave también se eliminará de la base de datos.
El número máximo de elementos que pueden incluirse en la lista es 4G (4,1 mil millones)
Comandos comunes
| mando | comportamiento |
|---|---|
| elemento de elemento clave exuberante | Agrega 1 o más elementos de la izquierda |
| elemento de elemento clave rpush | Agregue 1 o más elementos de la derecha |
| tecla lpop | Elimina el elemento más a la izquierda y vuelve |
| clave rpop | Eliminar el elemento más a la derecha y volver |
| La tecla de rango comienza y termina | Encuentre los elementos en el rango de índice especificado y regrese, cada elemento tiene 2 números de índice, números de índice de izquierda a derecha: 0 ~ longitud-1 números de índice de derecha a izquierda: -1 ~ -length Si desea obtener todos los elementos de la lista completa, ¿Cómo escribir el rango de números de índice? 0 ~ -1 |
| llen 键 | Obtenga cuántos elementos hay en la lista |
Demostración de comandos

Un servidor Redis puede incluir varias bases de datos, y el cliente solo puede conectarse a una determinada base de datos en Redis, al igual que crear varias bases de datos en un servidor mysql, y el cliente especifica a qué base de datos conectarse cuando se conecta.
Hay 16 bases de datos numeradas db0-db15 en Redis. No podemos crear nuevas bases de datos, ni podemos eliminar bases de datos. No hay una estructura de tabla en la base de datos y el cliente se conecta a la base de datos 0 de forma predeterminada. Pero, ¿cuántas bases de datos se pueden configurar a través del archivo de configuración?
Métodos comunes de la clase Jedis
-
Cada método es el nombre del comando en redis, y los parámetros del método son los parámetros del comando.
-
Cada objeto Jedis es similar al objeto Conexión en JDBC. Obtener un objeto Jedis es esencialmente obtener un objeto de conexión.
| Conecta y cierra | Caracteristicas |
|---|---|
| nuevos Jedis (host String, puerto int) | Crear un objeto de conexión parámetro 1: nombre de host parámetro 2: número de puerto 6379 |
| vacío cerrado () | Cerrar la conexión |
| Métodos de operación en cuerdas. | Descripción |
|---|---|
| set (clave de cadena, valor de cadena) | Agregar claves y valores de tipo cadena |
| String get (clave de cadena) | Obtenga valor por clave |
| del (Cadena… claves) | Eliminar una o más claves y valores |
| Métodos de funcionamiento de la lista | Descripción |
|---|---|
| lpush (clave de cadena, cadena ... valores) | Agrega 1 o más elementos de la izquierda |
| List<String> lrange(String key,long start,long end) | 获取一个范围内所有的元素 |
代码
package com.itheima;
import redis.clients.jedis.Jedis;
/**
* Jedis的基本使用
*/
public class Demo1Base {
public static void main(String[] args) {
//1.创建Jedis连接对象
Jedis jedis = new Jedis("localhost", 6379);
//2.向服务器添加1个字符串类型的键和值
jedis.set("book","人鬼情喂鸟");
//3.从服务器中通过键获取值
String book = jedis.get("book");
//4.关闭连接
jedis.close();
//5.打印输出到控制台
System.out.println(book);
}
}
Jedis连接池的使用
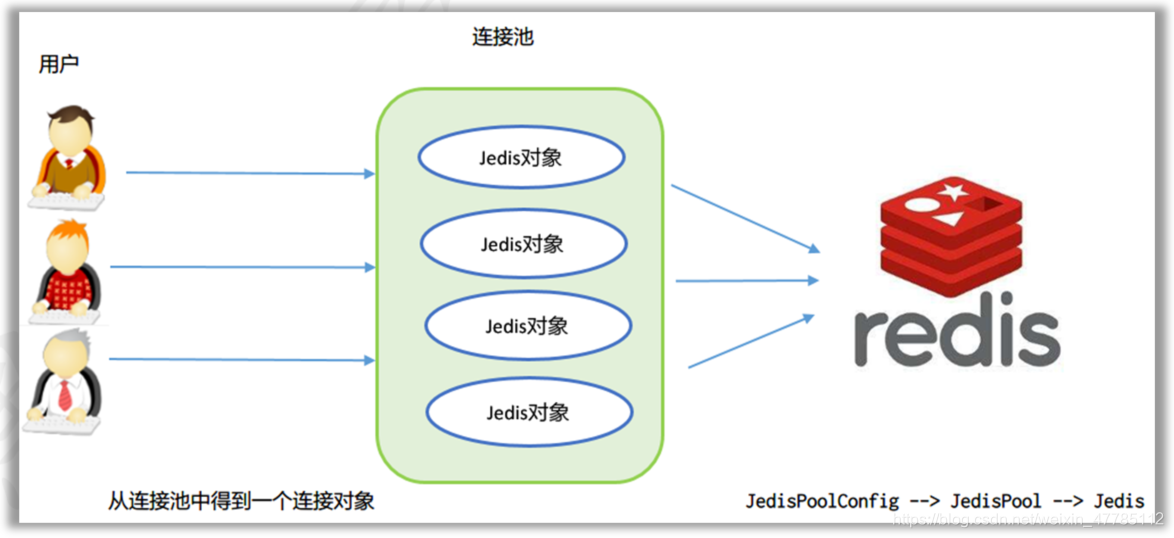
jedis连接资源的创建与销毁是很消耗程序性能,所以jedis为我们提供了jedis的连接池技术,jedis连接池在创建时初始化一些连接对象存储到连接池中,使用jedis连接资源时不需要自己创建jedis对象,而是从连接池中获取一个资源进行redis的操作。使用完毕后,不需要销毁该jedis连接资源,而是将该资源归还给连接池,供其他请求使用。
Jedis连接池API
用于创建连接池的配置信息
| JedisPoolConfig配置类 | 功能说明 |
|---|---|
| JedisPoolConfig() | 构造方法,创建一个配置对象 |
| void setMaxTotal() | 连接池中最大连接数 |
| void setMaxWaitMillis() | 设置最长等待时间,单位是毫秒 |
| JedisPool连接池类 | 说明 |
|---|---|
| JedisPool(配置对象,服务器名,端口号) | 构造方法,创建连接池的类 参数1:上面的配置对象 参数2:服务器名 参数3:端口号 |
| Jedis getResource() | 从连接池中获取一个创建好的连接对象,返回Jedis对象 |
JedisPool的基本使用
需求:
使用连接池优化jedis操作,从连接池中得到一个创建好的Jeids对象,并且使用这个Jedis对象。向Redis数据库写入一个set集合,并且取出集合。打印到控制台,并且查看数据库中信息。
开发步骤
- 创建连接池配置对象,设置最大连接数10,设置用户最大等待时间2000毫秒
- 通过配置对象做为参数,创建连接池对象
- 从连接池里面获取jedis连接对象,执行redis命令。
- 执行redis命令写入list集合
- 执行redis命令读取list集合
- 输出读取的数据
- 关闭连接对象(通常连接池不关闭)
执行代码
package com.itheima;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import java.util.List;
/**
* Jedis连接池的基本使用
*/
public class Demo2Pool {
public static void main(String[] args) {
//1.创建连接池的配置对象
JedisPoolConfig config = new JedisPoolConfig();
//2.设置连接池的参数
config.setMaxTotal(10); //最大连接数
config.setMaxWaitMillis(2000); //最长等待时间为2秒钟
//3.创建连接池,使用上面配置对象
JedisPool pool = new JedisPool(config,"localhost", 6379);
//4.从连接池中获取连接对象
Jedis jedis = pool.getResource();
//5.使用连接对象
jedis.lpush("students", "孙悟空", "猪八戒", "白骨精");
List<String> students = jedis.lrange("students", 0, -1);
System.out.println(students);
//6.关闭连接对象
jedis.close();
}
}
小结
| JedisPool连接池类 | 作用 |
|---|---|
| JedisPool(配置对象,服务器名,端口号) | 创建连接池 参数1:配置对象 参数2:服务器名 参数3:端口号 |
| Jedis getResource() | 从连接池中获取连接对象 |
| void close() | 关闭连接池 |
ResourceBundle类的使用
代码
jedis.properties的内容
# 连接池的最大连接数
maxTotal=10
# 最长等待时间为2秒钟
maxWaitMillis=2000
# 服务器名字
host=localhost
# 端口号
port=6379
使用ResourceBundle类:
package com.itheima;
import java.util.ResourceBundle;
public class Demo3Resource {
public static void main(String[] args) {
//1. 通过静态方法读取属性文件,参数是:属性文件的主文件名,没有扩展名
ResourceBundle bundle = ResourceBundle.getBundle("jedis");
//2. 获取属性值,通过键获取值
String host = bundle.getString("host");
//3.输出值
System.out.println(host);
}
}
小结
| java.util.ResourceBundle类 | 功能 |
|---|---|
| static ResourceBundle getBundle(“配置文件基名”) | 读取配置文件,得到对象。参数是主文件名 |
| String getString(“键名”) | 通过键获取值 |
Jedis连接池工具类的实现
jedis.properties配置文件
# 主机名
host=localhost
# 端口号
port=6379
# 最大连接数
maxTotal=20
# 最长等待时间
maxWaitMillis=3000
JedisUtils.java
package com.itheima.utils;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import java.util.ResourceBundle;
/**
* Jedis连接池工具类
*/
public class JedisUtils {
private static JedisPool pool;
//在静态代码块中创建连接池
static {
//读取配置文件
ResourceBundle bundle = ResourceBundle.getBundle("jedis");
//读取属性值
int maxTotal = Integer.parseInt(bundle.getString("maxTotal"));
int maxWaitMillis = Integer.parseInt(bundle.getString("maxWaitMillis"));
int port = Integer.parseInt(bundle.getString("port"));
String host = bundle.getString("host");
//创建连接池配置对象
JedisPoolConfig config = new JedisPoolConfig();
//设置连接池的参数
config.setMaxTotal(maxTotal);
config.setMaxWaitMillis(maxWaitMillis);
//创建连接池
pool = new JedisPool(config, host, port);
}
/**
* 获取连接对象
*/
public static Jedis getJedis() {
return pool.getResource();
}
}
使用工具类
package com.itheima;
import com.itheima.utils.JedisUtils;
import redis.clients.jedis.Jedis;
//使用连接池工具类
public class Demo4Use {
public static void main(String[] args) {
//从连接池中获取连接对象
Jedis jedis = JedisUtils.getJedis();
//添加键和值
jedis.set("car", "BWM");
//取出
String car = jedis.get("car");
//输出
System.out.println(car);
//关闭连接
jedis.close();
}
}
持久化
利用永久性存储介质将数据进行保存,在特定的时间将保存的数据进行恢复的工作机制称为持久化 持久化用于防止数据的意外丢失,确保数据安全性
永久化介质保存数据,存在硬盘
RDB
直接拷贝数据从内存到磁盘上
RDB优点
-
RDB是一个紧凑压缩的二进制文件,存储效率较高
-
RDB内部存储的是redis在某个时间点的数据快照,非常适合用于数据备份,全量复制等场景
-
RDB恢复数据的速度要比AOF快很多
-
应用:服务器中每X小时执行bgsave备份,并将RDB文件拷贝到远程机器中,用于灾难恢复。
RDB缺点
-
RDB方式无论是执行指令还是利用配置,无法做到实时持久化,具有较大的可能性丢失数据
-
bgsave指令每次运行要执行fork操作创建子进程,要牺牲掉一些性能
-
Redis的众多版本中未进行RDB文件格式的版本统一,有可能出现各版本服务之间数据格式无法兼容现象
AOF
-
AOF(append only file)持久化:以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中命令 达到恢复数据的目的。与RDB相比可以简单理解为由记录数据改为记录数据产生的变化
-
AOF的主要作用是解决了数据持久化的实时性,目前已经是Redis持久化的主流方式
Tres estrategias para escribir datos AOF (appendfsync)
-
siempre (cada vez): cada operación de escritura se sincroniza con los datos del archivo AOF con cero errores, el rendimiento es bajo y no se recomienda.
-
everysec (por segundo): sincroniza las instrucciones en el búfer con el archivo AOF cada segundo. En el caso de un tiempo de inactividad repentino del sistema, se perderán los datos en 1 segundo. La precisión de los datos es alta y el rendimiento es alto. Se recomienda su uso, y también es la configuración predeterminada.
-
no (control del sistema): el proceso general del ciclo que se sincroniza con el archivo AOF cada vez que es controlado por el sistema operativo es incontrolable
RDB VS AOF
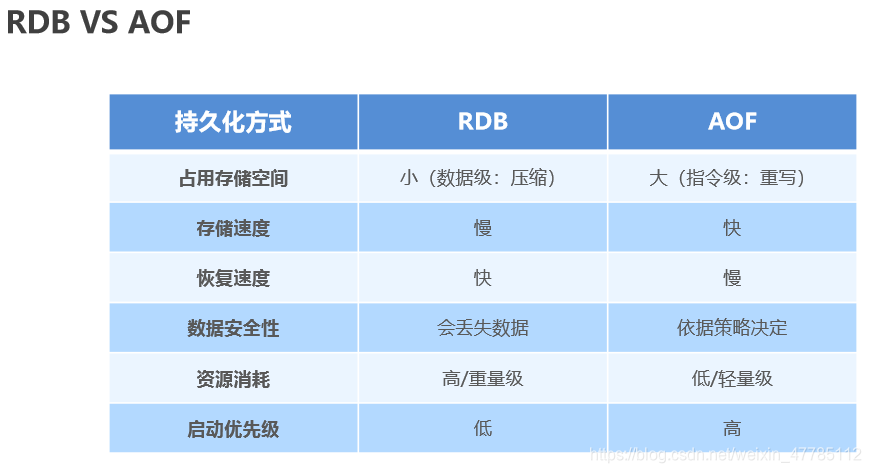
La confusión de elección entre RDB y AOF
-
Muy sensible a los datos, se recomienda utilizar el esquema de persistencia AOF predeterminado
-
La estrategia de persistencia AOF usa everysecond, fsync una vez cada segundo. Esta estrategia de redis aún puede mantener un buen rendimiento de procesamiento.Cuando ocurre un problema, los datos dentro de 0-1 segundos como máximo pueden perderse.
-
Nota: Debido al gran volumen de almacenamiento de archivos AOF, la velocidad de recuperación es lenta
-
La validez de la etapa de presentación de datos, se recomienda utilizar el esquema de persistencia RDB
-
Los datos pueden estar bien garantizados para que no haya pérdidas en la etapa (la etapa es mantenida manualmente por el desarrollador o el personal de operación y mantenimiento), y la velocidad de recuperación es relativamente rápida. La recuperación de datos del punto de etapa generalmente adopta el esquema RDB
-
Nota: El uso de RDB para lograr una persistencia de datos compacta hará que Redis sea muy bajo. Resuma cuidadosamente:
-
Comparación completa
-
La elección de RDB y AOF es en realidad una compensación. Cada una tiene sus ventajas y desventajas, como no poder soportar la pérdida de datos en unos pocos minutos y ser muy sensible a los datos comerciales. Elija AOF.
-
Si puede soportar la pérdida de datos en unos minutos y perseguir la velocidad de recuperación de grandes conjuntos de datos, elija RDB
-
RDB para recuperación ante desastres
-
Doble estrategia de seguro, abre RDB y AOF al mismo tiempo, después del reinicio, Redis dará prioridad al uso de AOF para recuperar datos, reduciendo la cantidad de datos perdidos.
El contenido anterior está sesgado, ¡corrígeme!