El surgimiento de un nuevo concepto debe tener sus razones, y cgroup no es una excepción, fue propuesto originalmente por los ingenieros de Google Paul Menage y Rohit Seth [1] : Porque las capacidades del hardware de las computadoras son cada vez más poderosas, con el fin de mejorar la eficiencia. de la máquina, se puede utilizar en los mismos trabajos de ejecución con diferentes modelos informáticos en una máquina. Al principio, recibió el nombre de contenedor de procesos. Más tarde, debido a que Contenedor tiene múltiples significados, es fácil causar malentendidos. En 2007, se le cambió el nombre a Grupos de control y se integró en el kernel 2.6.24. Puede limitar, registrar y aislar los recursos físicos utilizados por los grupos de procesos (como cpu/memory/io, etc.) y la prioridad de controlar el uso de los recursos físicos.Este artículo se refiere principalmente al código fuente del kernel-5.10 para dar una introducción básica a cgroup.
1. Composición de cgroup
Usamos cgroup para procesar recursos para grupos de procesos, que es inseparable de los siguientes componentes:

cgroupv1 puede permitir múltiples niveles. Con la organización de v1, si los subsistemas utilizados están conectados al mismo nivel, no hay forma de desacoplar el control de recursos de los subsistemas, y algunos procesos pueden verse afectados por otros subsistemas. Por lo tanto, V1 requiere múltiples niveles de organización, y un nivel puede considerarse como un árbol, que puede considerarse como un bosque.
Además, la relación entre cgroup, tarea, subsistema y jerarquía y sus reglas básicas son las siguientes:
Se pueden adjuntar uno o más subsistemas a la misma jerarquía.
Un subsistema se puede adjuntar a varias jerarquías si y solo si esas jerarquías tienen solo este subsistema.
Para cada jerarquía que cree, una tarea solo puede existir en uno de los cgroups, es decir, una tarea no puede existir en diferentes cgroups de la misma jerarquía, pero una tarea puede existir en varios cgroups en diferentes jerarquías.
La tarea secundaria creada por el proceso (tarea) cuando se bifurca está por defecto en el mismo cgroup que la tarea original, pero la tarea secundaria puede moverse a un cgroup diferente.
1.1 subsistema de introducción
El subsistema se utiliza principalmente para el control de recursos, por ser un módulo de control específico, se introduce por separado, con el aumento de requisitos y funciones, existen los siguientes subsistemas más importantes y de uso común:
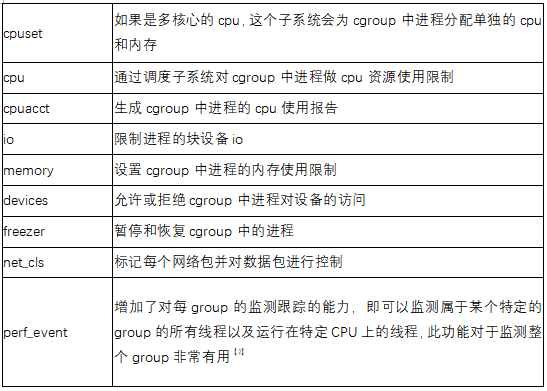
Cgroup que extrae estos subsistemas también está reutilizando estos módulos de administración de recursos. La esencia es adjuntar ganchos a estos módulos de administración de recursos para realizar la limitación de recursos y la asignación de prioridades.
1.2 estructura de datos clave de cgroup
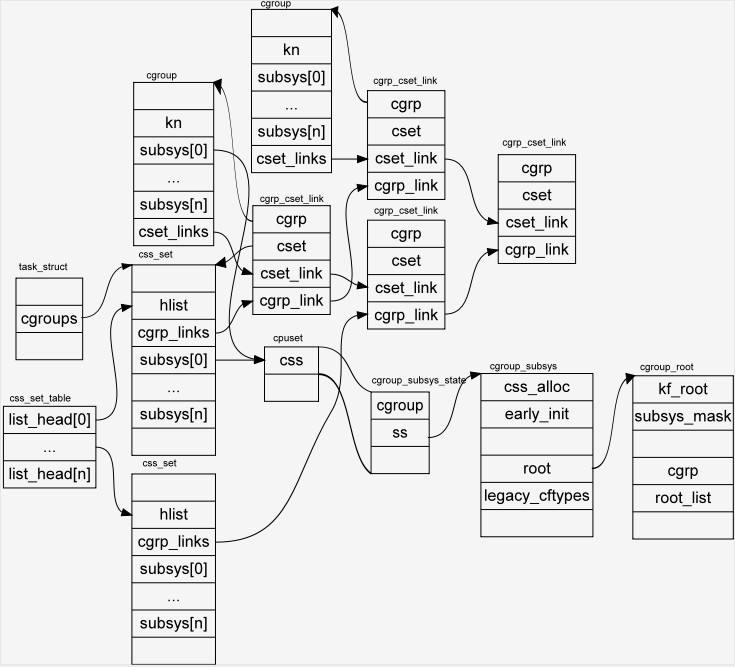
Lo que nos interesa es cómo se mapean las tareas y los cgroups, porque el sistema puede tener múltiples niveles, y cada tarea también puede estar restringida por múltiples subsistemas, por lo que una tarea puede existir en múltiples cgroups; y cada cgroup también controla múltiples tareas. Por lo tanto, las tareas y los cgroups están en una relación de muchos a muchos. Para registrar esta relación, puede agregar más listas enlazadas, pero la eficiencia de búsqueda y modificación es demasiado baja.Linux usa dos estructuras de datos intermedias, css_set y cgrp_cset_link, para completar este mapeo.
Imagine que cuando un proceso clona un proceso secundario, si no especifica un cgroup específico, el proceso secundario predeterminado permanecerá en los mismos cgroups que el proceso, y el grupo de procesos que comparten los mismos cgroups se extraerá e identificará con css_set, cada proceso solo existe en un css_set, un css_set puede contener varios procesos, todos los css_set se organizan a través de una tabla hash, cuando el proceso se migra entre cgroups, porque css_set se basa en la comunidad de cgroups creados, por lo que css_set también se puede reutilizar.
Información del grupo C en el proceso:
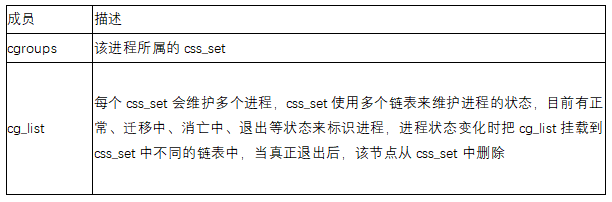
Con css_set, aunque el mismo tipo de proceso está vinculado a un css_set, seguirá existiendo un problema de asignación de muchos a muchos entre css_set y cgroup, pero la cantidad de css_set será menor que la cantidad de tareas. , cgrp_cset_link está llegando Nuevo La tercera tabla agregada puede mejorar en gran medida la eficiencia de cgroup y css_sets para encontrarse entre sí.
Relación de conexión general:
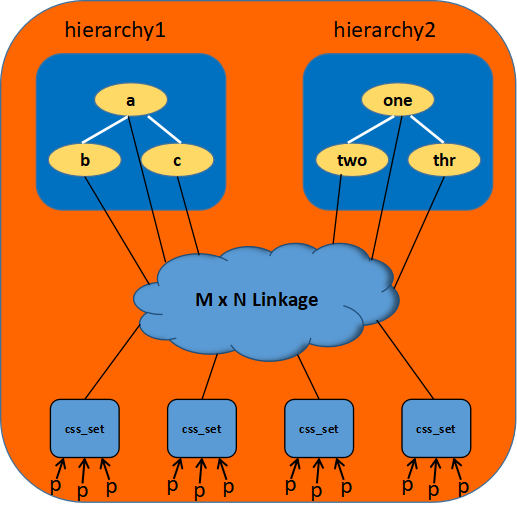
Además, por un lado, css_set registra la información del proceso en el cset, y también mantiene la información del subsistema subsys (css para abreviar), que también se puede considerar como un enlace entre ambos.
miembros clave css_set:
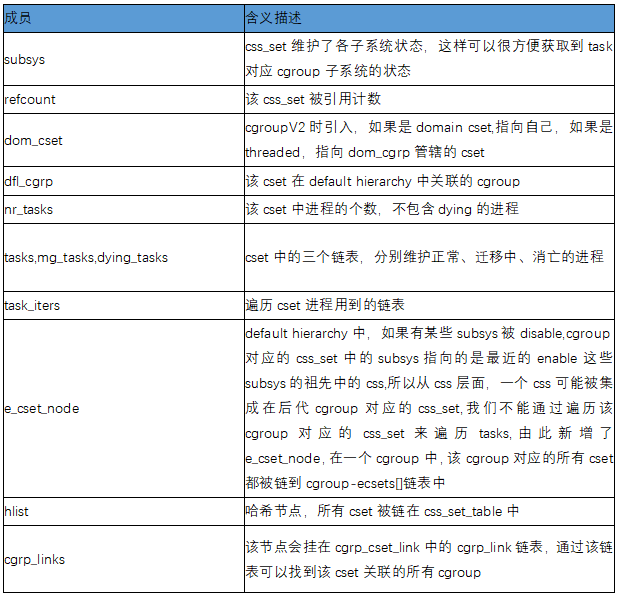
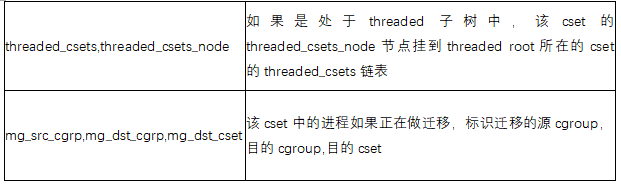
Miembros clave del grupo C:
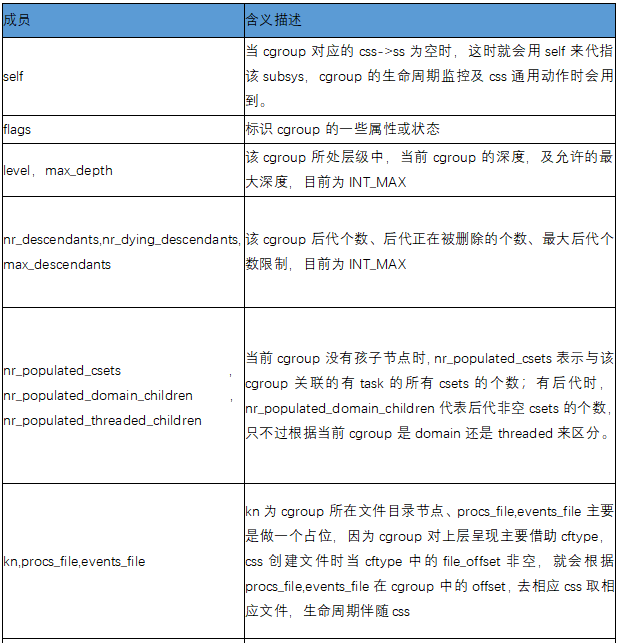
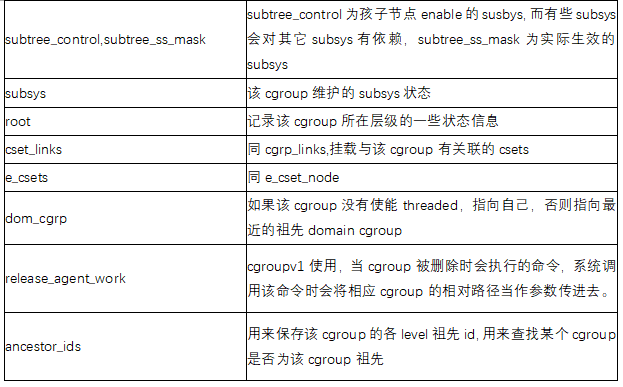
cgroup_subsys_state, el objeto clave de la operación de cgroup, incluida la exposición de archivos, relacionada con la operación del subsistema.
Sus miembros clave:
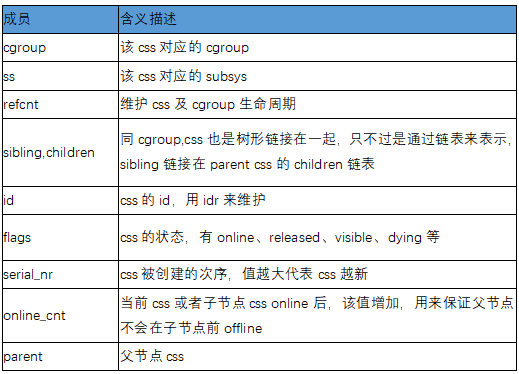
El subsistema cgroup_subsys incluye principalmente los métodos generales de operación de cada subsistema.
Miembros clave:
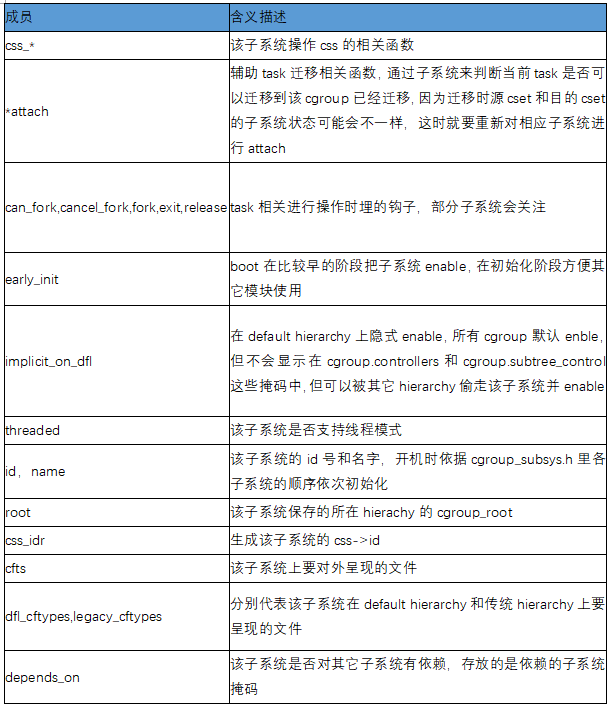
El diagrama de relaciones de cada estructura de datos de cgroup:
2. inicialización de cgroup
La inicialización de Cgroup es relativamente simple, principalmente dividida en dos pasos, cgroup_init_early y cgroup_init.
2.1 cgroup_init_early
Debido a que se encuentra en una etapa muy temprana de arranque, realiza principalmente el siguiente trabajo:
Al igual que init_task, el sistema también inicializa cgrp_dfl_root como cgroup_root de la jerarquía predeterminada. De manera similar, también hay un init_css_set para inicializar tareas relacionadas en la fase de inicio. En esta etapa, por defecto, los procesos secundarios bifurcados por el proceso init se bloquearán en init_css_set.
Si hay subsistemas relacionados que necesitan ser utilizados por otros módulos en la fase de inicio, se construirá la estructura de datos de cgroup relacionada con el subsistema, se establecerá la relación entre el ss/css/cgroup/css_set relacionado y, finalmente, se creará online_css. ser llamado para hacer que el css surta efecto, pero aún no se haya renderizado en el sistema de archivos, e inicialice el subsistema de init_css_set.
2.2 cgroup_init
La inicialización ha venido aquí, se han inicializado vfs y sysfs, el trabajo principal:
Llame a cgroup_setup_root para inicializar cgrp_dfl_root y cree archivos relacionados que cgroup expone a los usuarios, porque en la jerarquía predeterminada, los archivos relacionados en la matriz cgroup_base_files se crearán en /sys/fs/cgroup y luego llame a rebind_subsystems. el subsistema no está realmente involucrado El movimiento de diferentes jerarquías no habilita CSS relacionado y expone archivos relacionados con ss. Luego conecte todos los css_sets existentes al cgroup raíz, después de todo, todos están bajo la jerarquía predeterminada en este momento.
Inicialice cada subsistema definido en cgroup_subsys.h, vea 2.1.
Monte init_css_set en cgrp_dfl_root, de modo que pueda colgar todos los procesos en init_css_set a través de cgrp_dfl_root.
Para que cada subsistema se inicialice, los archivos que se expondrán en el espacio del usuario se inicializarán y crearán.
Debido a que el subsistema de init_css_set se inicializa y cambia, vuelva a hacer el enlace hash en css_set_table.
Registre los tipos de sistemas de archivos cgroup y cgroup2.
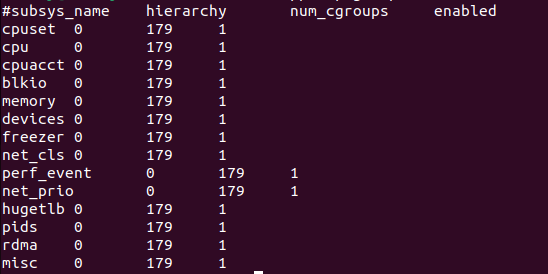
Cree un archivo /proc/cgroups para ver una descripción general de los cgroups del sistema actual. Tomemos ubuntu como ejemplo.Después de arrancar, solo hay una jerarquía, en la que se crean 179 cgroups y se habilitan 14 subsistemas.
3.ctarea de creación y asignación de grupos
cgroup vfs se basa en kernfs. El proceso de montaje utiliza principalmente kernfs para inicializar el superbloque y el directorio raíz. Además, se distinguen cgroupv1 y cgroupv2. v2 admite el modo de subprocesos y solo hay una "jerarquía unificada predeterminada". Debido a la diferencia de forma, v1 necesita encontrar o crear una jerarquía, pero no v2.Además, existen algunas diferencias en el procesamiento de parámetros durante el montaje, que no se detallarán aquí.
3.1 creación de cgroup
Después de que el montaje sea exitoso, puede crear un cgroup a través de mkdir en el directorio de archivos montados.
El proceso principal es el siguiente:
Encuentre el nodo principal del cgroup y verifique si algunas restricciones del nivel actual pueden cumplir con los requisitos, principalmente el número de descendientes y el límite de profundidad.
Llame a cgroup_create para realizar una inicialización específica, inicialice el refcnt que administra su ciclo de vida, cree el directorio del kernfs donde se encuentra, herede el estado congelado actual del nodo principal, para que la congelación pueda tener efecto automáticamente, y luego vincúlese. a la lista de hijos del nodo padre, lo cual es conveniente Establezca la estructura de árbol de cgroup, que se usará más adelante para recorrer sus descendientes. Porque en la jerarquía predeterminada, cgroup v2 puede estar habilitado, por lo que su subtree_control no se inicializará. En otros niveles, se inicializarán subtree_control y subtree_ss_mask del cgroup actual y sus descendientes Para conocer las diferencias específicas entre los dos, consulte la introducción de parámetros anterior.
Llame a css_populate_dir para crear archivos comunes de cgroup en el directorio actual.
Para cada subsistema habilitado, cree css y el archivo de inicialización del subsistema actual (dfl_cftypes
y legacy_cftypes, pero se creará en función de si se selecciona en la jerarquía predeterminada), por lo que cuando mkdir cgroup manualmente, verá muchos archivos creados automáticamente.
3.2 Asignar tarea a cgroup
Aquí hablamos brevemente sobre el modo de subprocesos, solo podemos crear cgroups de dominio, pero podemos escribir 'threaded
' Vaya al archivo "cgroup.type" del cgroup actual para hacer que el cgroup esté encadenado. Cuando el cgroup se convierte en un cgroup encadenado, no se puede cambiar a un cgroup de dominio. Después de convertirse en subprocesos, su nodo principal cgroup de dominio más cercano será responsable de las estadísticas de recursos y se convertirá en el dom_cgrp del cgroup subprocesos. Si selecciona el nodo "cgroup.type" del cgroup del nodo principal actual en este momento, encontrará que escriba los cambios de dominio a For domain threaded, y si se eliminan todos los descendientes del nodo principal, se restaurará al dominio.
El modo de subprocesos puede ayudarnos a controlar mediante la agrupación en la granularidad del subproceso, pero debe estar en un dominio subproceso.
Los nodos como "cgroup.procs" y "tasks" de cgroupv1, "cgroup.procs" y "cgroup.threads" de cgroupv2 pueden realizar el control de cgroup escribiendo identificadores de tareas específicos en los nodos.
Tomando "cgroup.procs" como ejemplo, el proceso específico es el siguiente:
Obtenga el cgroup de destino para asignar a partir de la entrada del usuario. Debido a que está operando en modo v2, existe una distinción entre procesos y subprocesos para un control separado. El nodo "cgroup.procs" encontrará el líder del grupo de procesos de la tarea que se va a operar y luego migrará todos los subprocesos en el grupo de procesos a el grupo c de destino.
Obtenga el cgroup donde se encuentra actualmente la tarea, ya que está en la jerarquía predeterminada y el método de búsqueda es fácil de entender a través de cset_group_from_root.
cgroup_attach_task realiza la acción de migración principal, donde cgroup_migrate_add_src vinculará los csets a los que pertenecen todas las tareas del grupo de subprocesos a la lista vinculada preloaded_src_csets de la estructura de datos mgctx que registra el proceso de migración.
cgroup_migrate_prepare_dst primero saca el cset de origen de la lista vinculada de preloaded_src_csets, superpone y migra el cgroup de destino correspondiente para obtener el cset de destino y luego registra la relación correspondiente entre el cset de origen y el cset de destino. cset y el cset de destino son inconsistentes, significa que el estado del subsistema es diferente, debe volver a ejecutar can_attach y adjuntar devoluciones de llamada durante la migración, y reincorporarlas a la administración de recursos del subsistema.
cgroup_migrate_add_task migrará la cg_list de la tarea en el grupo de subprocesos a la lista enlazada mg_tasks del cset al que pertenece, y marcará la tarea para iniciar el proceso de migración. Luego vincule el cset a la lista vinculada src_csets de mgctx.
cgroup_migrate_execute primero llama a can_attach para detectar el estado modificado del subsistema, luego obtiene el cset que se va a migrar de la lista vinculada src_csets, recorre las tareas en la lista vinculada mg_tasks en el cset y saca el cset de destino correspondiente, llama a css_set_move_task para migrar, rcu_assign_pointer ( task->cgroups, to); para completar la migración.
4. Resumen
Este artículo se centra en la descripción de la estructura de datos de cgroup y sus conceptos básicos. Debido a que la estructura de datos de cgroup es un poco más complicada, se describe en foco. Los lectores pueden sentirse más cómodos al leerla contra el código. El espacio es limitado y los subsistemas específicos de cgroup no están involucrados, los estudiantes interesados pueden compensarlo.
Referencias:
【1】https://lwn.net/Articles/199643/
【2】Documentación/cgroup-v1/*
【3】Documentación/cgroup-v2.txt
【4】Código fuente Kernel-5.10

Mantenga presionado para seguir Kernel Craftsman WeChat
Tecnología Linux Kernel Black | Artículos técnicos | Tutoriales destacados