Esquema de encadenamiento de datos a gran escala basado en Fabric + IPFS
Más tecnología de cadena de bloques y categoría de aplicación:
cadena de bloques aplicada cadena de bloques para desarrollar
Ethernet Square | Fabric | BCOS | criptografía | algoritmo de consenso | bitcoin | otra cadena a
través de certificados economía | escena financiera tradicional | finanzas descentralizadas | seguridad Trazabilidad | Intercambio de datos | Atestación confiable
Capítulo uno Descripción general del sistema
Blockchain es una máquina que genera confianza, pero la eficiencia del almacenamiento y la lectura de datos es muy baja. Cuando no se pueden lograr los dos al mismo tiempo, una nueva forma de compensar la eficiencia de blockchain, pero también de usar su "confianza" Y función "no manipulable". Esta solución utiliza blockchain + almacenamiento distribuido.
Introducción a Fabric y escenarios aplicables : La aparición de Hyperledger Fabric es una innovación al modelo tradicional de blockchain. Permite la creación de blockchains autorizadas y no autorizadas hasta cierto punto. Hyperledger también proporciona un sistema auditable, auditable y La seguridad de la privacidad y los modelos robustos permiten acortar el ciclo de cálculo, mejorar la eficiencia de la escala y responder a las necesidades de aplicación de diversas industrias.
Introducción a IPFS, escenarios aplicables : almacenamiento distribuido.
Ventajas y escenarios aplicables de Fabric + IPFS : se puede generar confianza sin que todos los datos estén encadenados.
Este sistema toma el desarrollo del servicio en segundo plano como núcleo y sirve como componente de servicio que vincula al cliente, IPFS y la cadena de bloques Fabric, como se muestra en la Figura 1. Cuando es necesario almacenar grandes cantidades de datos de manera confiable y en tiempo real y deben verificarse en el futuro, los datos deben almacenarse en la cadena de bloques de alguna forma. El sistema blockchain tradicional sacrifica la "eficiencia" por la "seguridad", por lo que su capacidad y velocidad de almacenamiento de datos son muy bajas, por lo que no puede almacenar datos a gran escala. Con base en esta consideración, podemos usar blockchain + almacenamiento distribuido para resolver el problema de los datos a gran escala en la cadena, almacenar los datos originales en un sistema distribuido como IPFS y almacenar la dirección del archivo de origen en la cadena de bloques. Conservación permanente, los usuarios pueden obtener estos datos en cualquier momento a través de la información de dirección del archivo en la cadena de bloques. Al mismo tiempo, para asegurar que los datos en IPFS no sean manipulados, la huella digital del archivo (el resultado del algoritmo Hash) también debe almacenarse en la cadena de bloques, de modo que el usuario pueda verificar los datos obtenidos en la cadena para determinar la integridad y confiabilidad de los datos. .
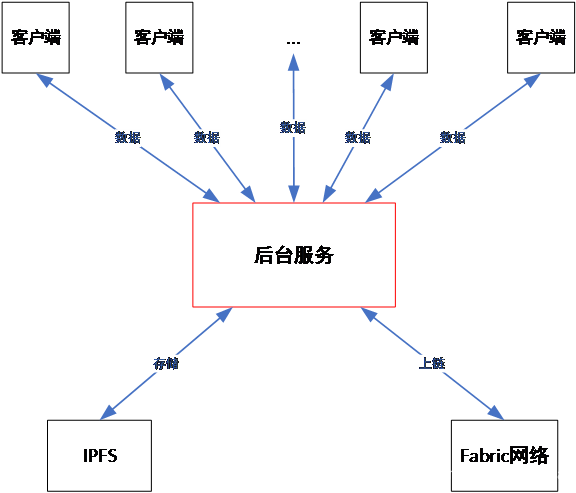
Figura 1-Arquitectura de servicio en segundo plano
El servicio en segundo plano está escrito en nodejs y la función general se puede dividir en dos partes:
- Almacenamiento de datos: los datos se pueden empaquetar en bloques en segundo plano y enviarse a IPFS. Todos los datos se almacenan en IPFS, y luego la dirección de almacenamiento de archivos y la huella digital del archivo en IPFS se almacenan en la red de cadena de bloques de Fabric, de modo que los datos se pueden verificar públicamente.
- Consulta de datos: el cliente puede obtener información específica sobre Fabric e IPFS consultando el contenido, es decir, basándose en la recuperación de contenido.
1.3 Entorno operativo
-
Soporte de hardware:
- Este servicio en segundo plano requiere el soporte de la red de cadena de bloques de Fabric y los nodos IPFS.
- Si Fabric se ejecuta en un modo de pseudo-clúster, se recomienda configurar una memoria de CPU de cuatro núcleos 8G, configuración del sistema operativo centos7 / Windows10 o superior.
- IPFS se ejecuta en un solo nodo, y se recomienda configurar una memoria de CPU de un solo núcleo, sistema operativo 2G, configuración centos7 / Windows10 o superior.
- La configuración recomendada del servicio Nodejs es la configuración centos7 / Windows10 del sistema operativo 2G de memoria de CPU de doble núcleo o superior.
-
soporte de software:
- versión de go-ipfs: 0.4.18
- Versión de nodejs: 8.1.0
- go versión: go1.9.2 windows / amd64
- versión de docke: 18.09.2
- versión de docker-compose: 1.23.2
- Versión de Hyperledger Fabric: 1.1.0
- versión de ipfs: 0.4.18
Capítulo 2 Detalles de la función
2.1 Diagrama de flujo de la función del software
El software en segundo plano maneja principalmente la carga de datos a gran escala, por lo que se centra en dos partes de la lógica: el almacenamiento de datos y la consulta de datos. El diagrama de flujo completo se muestra en la Figura 2. Cuando se almacenan datos, cuando el servicio en segundo plano recibe continuamente datos del cliente, necesita determinar si es el formato de transmisión correcto cada vez que recibe un dato y contar la cantidad de datos enviados por el cliente. Cada cliente diferente tiene un ID único y los datos usan el ID como el valor de la clave de índice, por lo que el bloque de datos se empaqueta en la unidad de "día", es decir, los datos de un día se usan como un bloque de datos independiente, lo cual es conveniente para la administración y consulta. Cuando se alcanza el tamaño de bloque predefinido (volumen de datos de un día), los datos del cliente se empaquetan en bloques. Después de empaquetar cada bloque, se almacenan inmediatamente en IPFS y se obtiene la dirección del bloque de almacenamiento IPFS. Luego, la dirección IPFS y la huella digital del archivo del bloque de datos se almacenan en la cadena de bloques de Fabric para su conservación.
Al consultar los datos, el cliente inicia una solicitud para obtener los datos originales y el servicio inicia la cadena Fabric y luego consulta si el código de la cadena tiene la información de la dirección IPFS debajo del ID y la fecha. Si no existe, significa que no hay datos; de lo contrario, continúe consultando IPFS. Obtenga los datos originales de IPFS de acuerdo con la dirección Hash del archivo de bloque de datos correspondiente en IPFS, y compare y verifique la huella digital del archivo en Fabric con los datos originales en IPFS. Si los dos son consistentes, se puede determinar que el bloque de datos no ha sido manipulado.

Figura 2-Diagrama de flujo del software
2.2 Descripción detallada del diseño funcional
1 almacenamiento de datos
El diagrama de flujo de implementación de la función de almacenamiento de datos se muestra en la Figura 3. Los siguientes son los pasos detallados:
(1) El cliente envía datos al
servicio back-end en un formato de datos específico (Json) a través de http-post. El servicio back-end registrará cada cliente conectado El terminal envía el número de datos y actualiza su huella dactilar del archivo de datos.Cuando se alcanza el valor preestablecido, se realiza la operación del paquete y los datos se envían a IPFS mediante un flujo.
(2) El bloque de datos se almacena en IPFS y luego se devuelve la dirección de almacenamiento.
(3) El servicio en segundo plano combina la huella digital del archivo calculada previamente con la dirección de almacenamiento del archivo IPFS y genera una nueva pieza de datos en la cadena, y luego almacena la información en la cadena llamando al código de la cadena Fabric. Libro mayor de nodos de pares.
(4) Fabric devuelve el valor hash de esta transacción de almacenamiento al servidor.
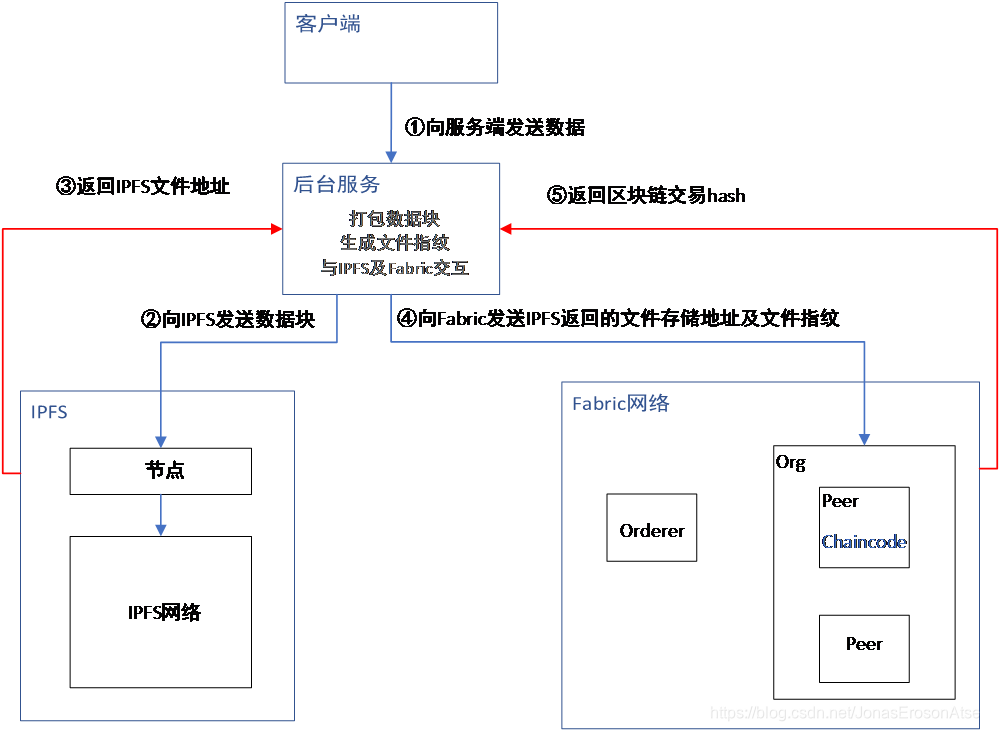 Figura 3 Diagrama de flujo de la realización de la función de almacenamiento de datos
Figura 3 Diagrama de flujo de la realización de la función de almacenamiento de datos
2 Consulta de datos
El diagrama de flujo de implementación de la función de consulta de datos se muestra en la Figura 4. Los siguientes son los pasos detallados:
(1) El cliente consulta información relacionada a través del valor de ID único y la fecha, y solicita datos del fondo del servicio mediante http-get. Por ejemplo, la URL de solicitud: http: // localhost: 60003 / querydata? Obdid = X7777-S6665 & date = 2019-4-3 es la interfaz para la consulta del usuario, lo que significa que el ID es X7777-S6665 y la fecha es 2019-4-3. Bloque de datos diario.
(2) El fondo iniciará automáticamente el contenedor del código de la cadena Fabric y ejecutará el método de consulta correspondiente en el código de la cadena.
(3) Fabric devolverá los datos correctos coincidentes (incluida la dirección de almacenamiento de archivos IPFS y la huella digital del archivo). Por ejemplo, la siguiente información:
{ "obdid": "X7777-S6665", "dataDate": "03.04.2019", "ipfsAddr": "QmfQJujeYWgX2Fn15nSLY7xApG7qQo3imz9S3UVxRcRiTi", "fileFingerprint": "21358B2F61C5B5DDD515F7046765BA43E8B643DCE26985BFD45A1BD02E9201A8"}
(4). Atrás a través de los datos Tela La dirección de almacenamiento del archivo IPFS para consultar la red IPFS y devolver el bloque de datos completo coincidente.
(5) IPFS devuelve la información del archivo del bloque de datos completo correspondiente de acuerdo con la dirección Hash, y luego el archivo se puede verificar en el servidor para verificar si los datos almacenados han sido manipulados.
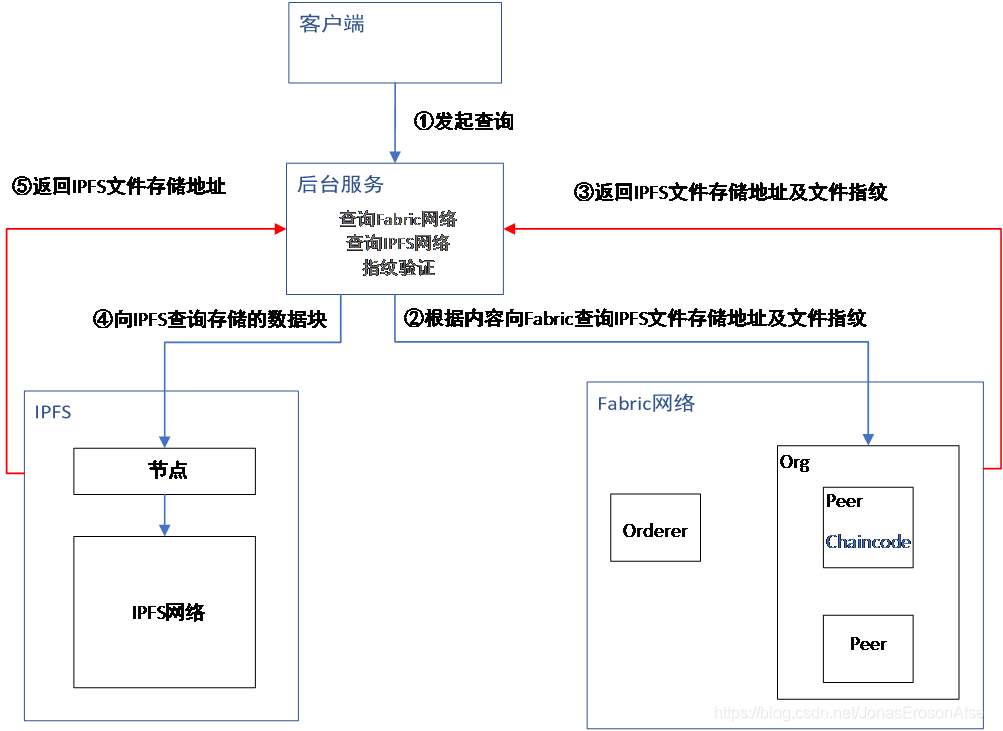
Figura 4 Diagrama de flujo de la realización de la función de consulta de datos
2.3 Estructura de almacenamiento
(1) Estructura del libro mayor Fabric La estructura del libro mayor
Fabric se refiere al formato de los datos almacenados por los nodos Peer en el canal correspondiente en la red Fabric, como se muestra en la Figura 5. Fabric almacena y consulta datos en forma de pares clave-valor <k, v>, por lo que la ID única se usa como la "clave" principal, y toda la información se almacena bajo esta clave (usando el formato anidado Json). De esta manera, toda la información relacionada con ese ID se almacena bajo cada ID. Al realizar una consulta, utilice el valor de ID único para averiguar todos los valores bajo ese ID.
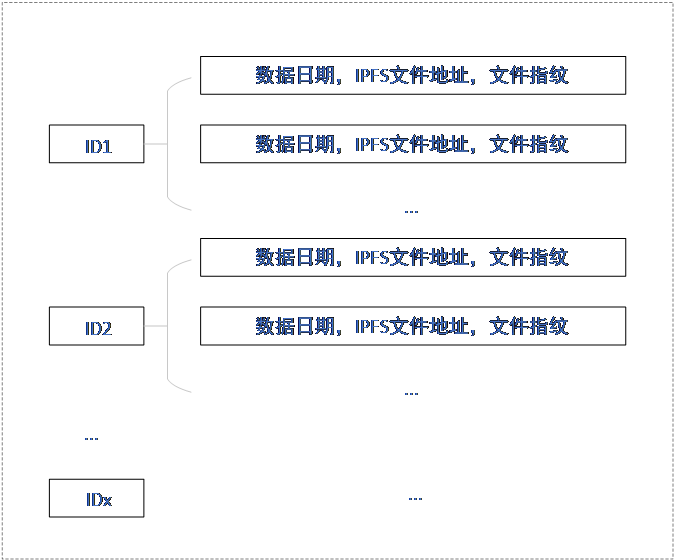
Figura 5 Estructura del larguero de tela
(2) Estructura de almacenamiento de IPFS:
IPFS almacena todos los bloques de datos de los datos de origen. Los bloques de datos se almacenan sin orden, pero la relación entre cada bloque de datos y la dirección hash corresponde a uno, como se muestra en la Figura 6. La relación de mapeo entre direcciones hash e información específica se almacena en la cadena de bloques de Fabric.
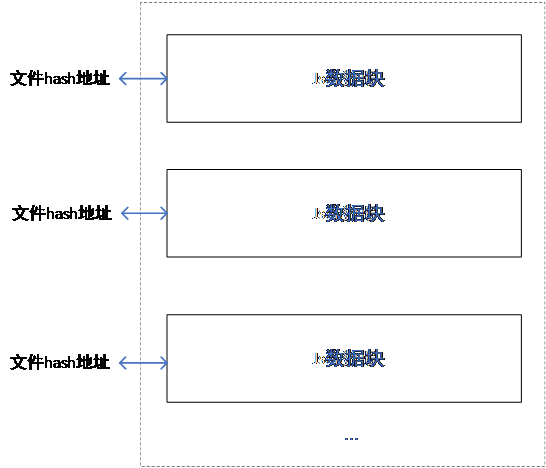
Figura 6 Estructura de almacenamiento de IPFS
Capítulo 3 Descripción de la operación
3.1 Instrucciones de funcionamiento
(1) El cliente carga datos. El
usuario transmite datos Json al fondo del servicio a través de http-post. El nuevo cliente envía continuamente datos al servidor, inicia el servicio de datos simulados (envía datos al fondo una vez por segundo) y carga los datos obd del vehículo a la cadena Como ejemplo, el registro de impresión se muestra en la Figura 7:
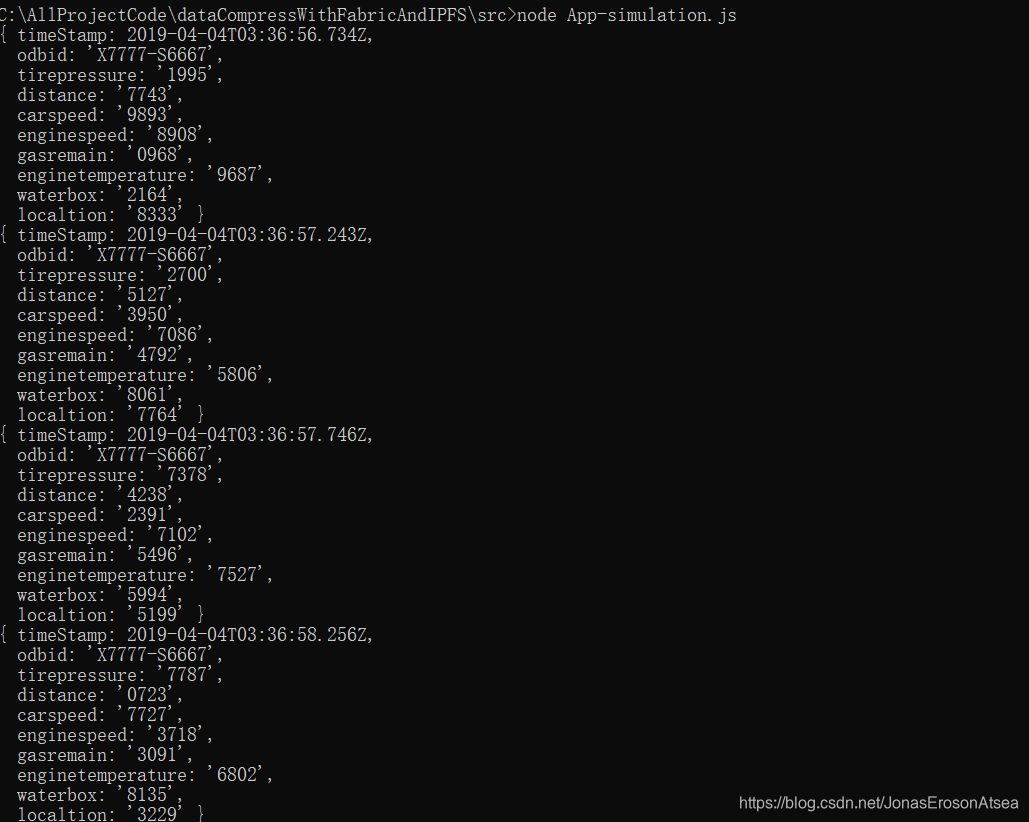
Figura 7 Registro de envío de datos simulados
(2) El back-end acepta datos y los procesa
. Después de que se inician todas las redes del sistema back-end (se inicia la red Fabric, se inicia IPFS), use el comando para ejecutar el demonio nodejs: node server.js
Cuando el bloque de datos está empaquetado, el registro de fondo se muestra en la Figura 8. :
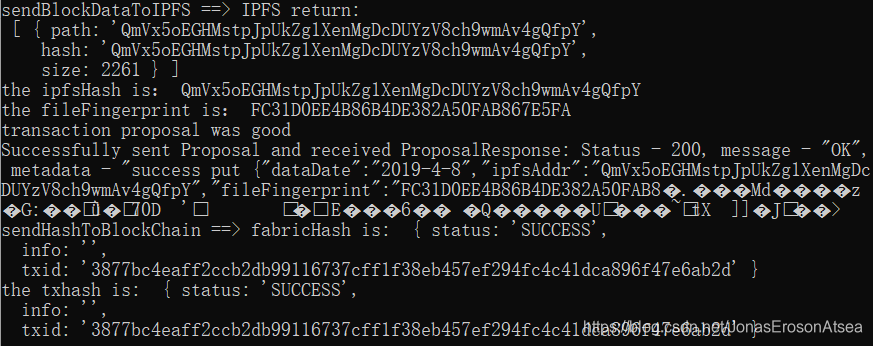
Figura 8 Registro cuando el servicio en segundo plano empaqueta el bloque
(3) Consulta del cliente / datos de verificación
relacionados con la consulta de datos en la red de la cadena de bloques de la tela: consulte los registros de almacenamiento de archivos en la tela a través de la ID única (obdid) y la fecha, puede obtener la dirección de almacenamiento de archivos ipfsAddr en IPFS, el hash de huella digital del archivo de archivo . Los datos obtenidos por http-get se muestran en la Figura 9:
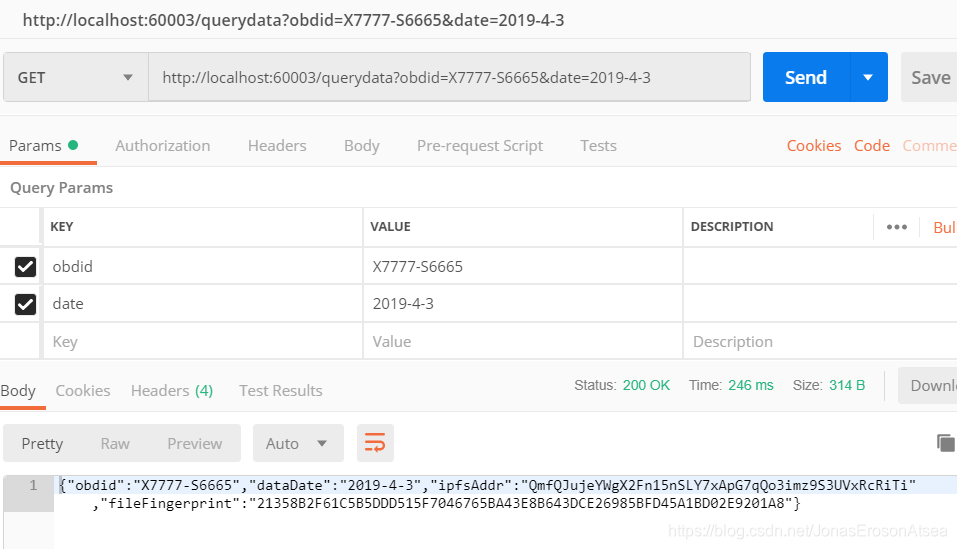
Figura 9 Los usuarios obtienen datos de Fabric a través del contenido
Consultar datos relacionados en IPFS: Pase ipfsAddr como parámetro de http-post al servidor, y todo el bloque de datos en IPFS se puede consultar nuevamente a través de este ipfsAddr, como se muestra en la Figura 10. El cliente puede realizar la verificación de huellas dactilares en todo el bloque de datos y comparar la huella dactilar del bloque de datos calculado con el parámetro fileFingerprint. Si son consistentes, demuestra que los datos están completos y no han sido manipulados.
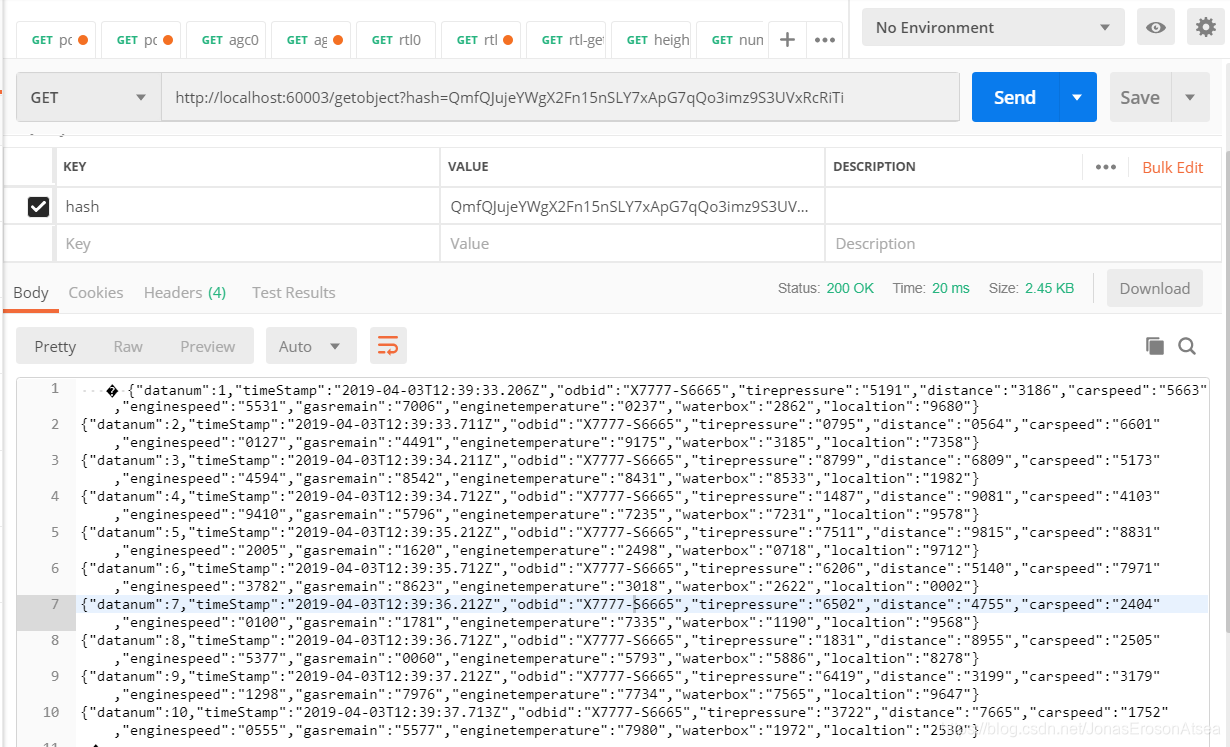
Figura 10 El usuario obtiene datos IPFS a través de Hash
La base del código se puede verificar y probar:
https://github.com/wanghaoyi1/dataCompressWithFabricAndIPFS.git
Enlace original: basado en el esquema de encadenamiento de datos a gran escala de Fabric + IPFS