Recientemente, he aprendido sobre series de tiempo. A continuación se presenta un estudio de caso de redes neuronales híbridas aplicadas a series de tiempo.
Artículo: " Redes neuronales híbridas para aprender la tendencia en series de tiempo "
TreNet: una novedosa red neuronal híbrida de extremo a extremo para aprender características de fondo locales y globales para predecir tendencias en series de tiempo.
Use LSTM de red neuronal recurrente de memoria larga-corta (RNN) para capturar la dependencia de largo alcance en secuencias de tendencias históricas.
CNN se usa generalmente para extraer características distintivas de los datos originales y extraer características de los datos de series temporales originales para el reconocimiento de actividad / acción. La
capa de fusión de características aprenderá a predecir la representación conjunta de tendencias.
TreNet demostró la efectividad de TreNet a través de la cascada de CNN, LSTM, CNN y LSTM, el método basado en el modelo oculto de Markov y varias líneas de base basadas en el núcleo basadas en conjuntos de datos reales.
Una serie temporal es una serie de puntos de datos cronológicos que se generan en una amplia gama de campos, como observaciones de experimentos médicos y biológicos, fluctuaciones diarias en el mercado de valores, registros de consumo de energía, monitoreo del rendimiento de los centros de datos, etc.
Representación básica:
Secuencia de puntos de datos:
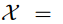
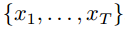
Tendencia real
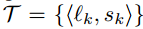
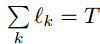
en X: una función lineal que representa una cierta subsecuencia, correspondiente a la tendencia. lk y sk representan respectivamente la duración y la pendiente de tendencia k, los valores continuos y T no se superponen entre sí.
Defina cada tendencia histórica de datos locales como un conjunto de puntos de datos de tamaño w:
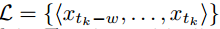
Objetivo: Proponer un método basado en redes neuronales para aprender funciones para predecir tendencias posteriores.
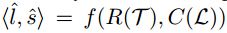
El punto está aquí:
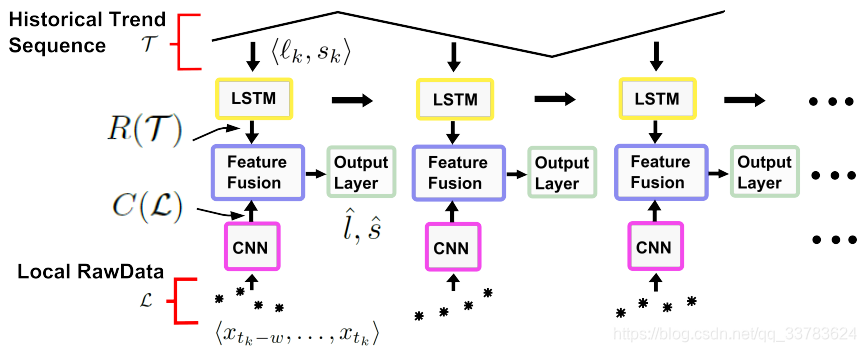
la idea de TreNet es combinar CNN y LSTM para aprovechar sus capacidades de representación en diferentes aspectos de los datos (es decir, L y T) y aprender características conjuntas para la predicción de tendencias. Predecir y calcular el tiempo T y la pendiente L respectivamente.
Funciones relacionadas con tendencias y R (T) y C (L).
R (T): Entrene al LSTM en la secuencia L para capturar la dependencia en los cambios de tendencia históricos.
C (L): corresponde a las características locales extraídas por CNN del conjunto de datos local en L.
Las capas de fusión de entidades combinan entidades utilizadas para predecir tendencias posteriores. Finalmente, la predicción de tendencia se implementa mediante una función, que corresponde a la fusión de características y la capa de salida.
Aprenda las dependencias en la secuencia de tendencia histórica Primero explique la
fórmula
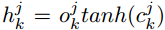
: representa el almacenamiento de la neurona jth en la capa LSTM en el paso k. Para salida.
Es la puerta de salida de la neurona LSTM.
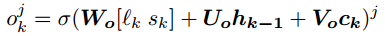
Es la concatenación de la duración de la tendencia k y la pendiente, y hk-1 y ck son la vectorización de, respectivamente.
σ es una función sigmoidea logística, puedes Baidu si no la entiendes.
Actualice de la siguiente manera, elimine algunos registros existentes y agregue nuevos registros:
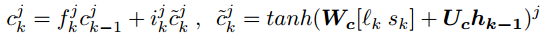
olvidando el control (olvidando lo existente) y el control de entrada (obteniendo nuevos):
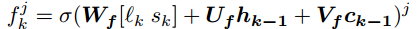
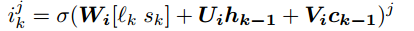
Vf, Vi son matrices diagonales.
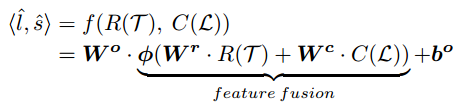
Es la función de activación ReLU de fuga de elementos, Wo y bo son el peso y la desviación de la capa de salida.
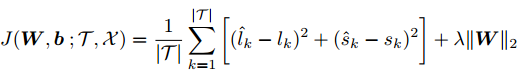
W yb representan los parámetros de peso y desviación.
λ es el hiperparámetro del término de regularización. La función de costo es diferenciable, y la arquitectura de TreNet permite que el gradiente de la función de pérdida se propague a las partes LSTM y CNN.
Análisis experimental:
TreNet se compara con CNN, LSTM, ConvNet + LAT (CLSTM), SVR, HMM basado en patrones y Naïve.
Los parámetros de evaluación son: RMSE, error cuadrático medio.
Los conjuntos de datos son: Consumo de energía (PC), Sensor de gas (Sensor de gas), Transacción de stock (Stock).
Los resultados de la comparación se publican directamente a continuación:

RMSE predice la duración de la tendencia y la pendiente de cada conjunto de datos.
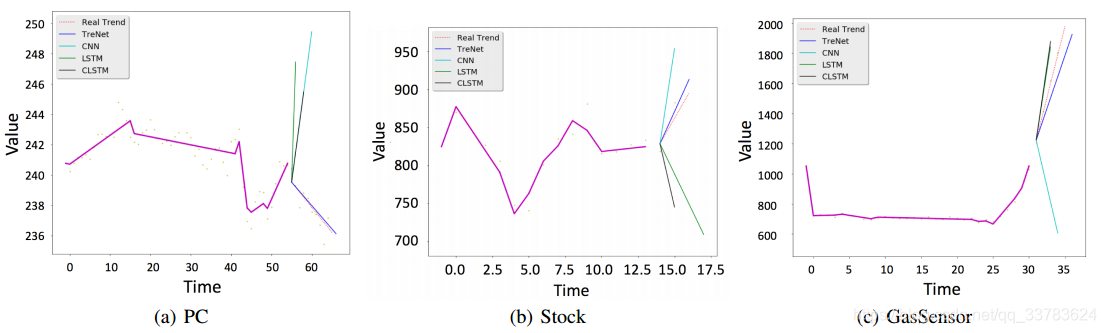
TreNet visualiza predicciones de tendencias para ejemplos de conjuntos de datos de PC, Stock y GasSensor. Los puntos amarillos representan series temporales, y la línea púrpura en cada gráfico representa las series de tendencias históricas relacionadas.
TreNet muestra mejores características de predicción y estabilidad.
Finalmente terminé de escribir, listo para descansar el fin de semana.
