Análisis del principio de Elasticsearch: inicio y apagado del nodo
Directorio de artículos
- Análisis del principio de Elasticsearch: inicio y apagado del nodo
-
- 1. ¿Qué hizo el proceso de inicio?
- 2. Análisis del proceso de inicio
-
- 2.1 Iniciar script
- 2.2 Análisis de parámetros de línea de comando y archivos de configuración
- 2.3 Cargar configuración de seguridad
- 2.4 Verificar el entorno interno
- 2.5 Verifique el entorno externo
-
- 2.5.1 Verificación del tamaño del montón
- 2.5.2 Comprobación del descriptor de archivo
- 2.5.3 Verificación de bloqueo de memoria
- 2.5.4 Comprobación del número máximo de subprocesos
- 2.5.5 Comprobación de la memoria virtual máxima
- 2.5.6 Comprobación del tamaño máximo de archivo
- 2.5.7 Comprobación del número máximo de áreas de memoria virtual
- 2.5.8 Comprobación de OnError y OnOutOfMemoryError
- 2.6 Iniciar módulos internos
- 2.7 Iniciar el hilo keepalive
- 3. Proceso de cierre del nodo
- 4. Cerrar el análisis del proceso
- 5. Realice el apagado durante la lectura y escritura del fragmento
- 6. El nodo principal está apagado.
- 7. Resumen
- 8. Sígueme
Este capítulo analiza el proceso de inicio y apagado de un solo nodo. Cómo ver el proceso que analiza la configuración, verificar el entorno, el módulo de inicialización interno , así como cómo manejar el nodo ** "matar" ** de tiempo.
1. ¿Qué hizo el proceso de inicio?
En general, la tarea del proceso de inicio del nodo es realizar los siguientes tipos de trabajo:
- Analice la configuración, incluidos los archivos de configuración y los parámetros de la línea de comandos.
- Verifique los entornos externos e internos, como la versión de JVM, los parámetros del kernel del sistema operativo, etc.
- Inicialice recursos internos, cree módulos internos e inicialice detectores.
- Inicie cada submódulo y manténgase activo.
2. Análisis del proceso de inicio
2.1 Iniciar script
Cuando iniciamos ES a través del script de inicio bin / elasticsearch, el script carga el programa Java a través de exec. el código se muestra a continuación:
exec \ #执行命令
"$JAVA" \ #Java程序路径
$ES_JAVA_OPTS \ #JVM选项
-Des.path.home="$ES_HOME" \ #设置path.home路径
-Des.path.conf="$ES_PATH_CONF" \ #设置path.conf路径
-Des.distribution.flavor="$ES_DISTRIBUTION_FLAVOR" \
-Des.distribution.type="$ES_DISTRIBUTION_TYPE" \
-cp "$ES_CLASSPATH" \ #设置 java classpath
org.elasticsearch.bootstrap.Elasticsearch \ #指定main函数所在类
"$@" #传递给main函数命令行参数
La variable ES_JAVA_OPTS contiene los parámetros de la JVM, cuyo contenido proviene del análisis del archivo de configuración config / jvm.options.
Si se agrega el parámetro -d al ejecutar el script de inicio:
bin/elasticsearch -d
Luego, el script de inicio agregará <& - & en exec. La función de <& - es cerrar la entrada estándar, que es la 0ª fd en el proceso. La función de & es hacer que el proceso se ejecute en segundo plano.
2.2 Análisis de parámetros de línea de comando y archivos de configuración
Los parámetros de la línea de comandos admitidos actualmente son los siguientes y no se utilizan en el inicio de forma predeterminada, como se muestra en la siguiente tabla:
| parámetro | sentido |
|---|---|
| -MI | Establezca una configuración. Por ejemplo, para establecer el nombre del clúster: -E "cluster.name = my_cluster", que generalmente se establece a través del archivo de configuración, no en la línea de comandos |
| -V, --versión | Imprimir información del número de versión |
| -d, - demonizar | Inicio de fondo |
| -h, --ayuda | Imprimir información de ayuda |
| -p, --pidfile | Cree un archivo pid en la ruta especificada al inicio, que guarda el pid del proceso actual, y luego puede cerrar el proceso viendo el archivo pid |
| -q, - silencioso | Apague la salida estándar y la salida de error estándar de la consola |
| -s, - silencioso | Información mínima de salida del terminal (el valor predeterminado es normal) |
| -v, --verbose | Información detallada de la salida del terminal |
En aplicaciones de ingeniería reales, se recomienda agregar -d y -p a los parámetros de inicio, por ejemplo:
bin/elasticsearch -d -p es.pid
Aquí se analizan los dos archivos de configuración siguientes, jvm.options se analiza en el script de inicio.
- elasticsearch.yml # Archivo de configuración principal
- log4j2.properties #Archivo de configuración de registro
2.3 Cargar configuración de seguridad
¿Qué es una configuración de seguridad? Esencialmente es información de configuración y, dado que es información de configuración, generalmente se escribe en un archivo de configuración. En los capítulos anteriores se mencionaron varios archivos de configuración de ES. La "configuración de seguridad" aquí es para solucionar que cierta información sensible no es apta para ser colocada en el archivo de configuración, porque el archivo de configuración está almacenado en texto plano, aunque el sistema de archivos está protegido en base a derechos de usuario, todavía no es suficiente. Por lo tanto, ES cifra esta información confidencial de configuración y la coloca en un archivo separado: config / elasticsearch.keystore. Luego proporcione algunos comandos para ver, agregar y eliminar configuraciones.
¿Qué tipo de información de configuración es adecuada para colocar en el archivo de configuración de seguridad? Por ejemplo, la configuración relacionada con la seguridad en X-Pack, LDAP base_dn y otra información (equivalente al nombre de usuario y la contraseña para iniciar sesión en el servidor).
2.4 Verificar el entorno interno
El entorno interno se refiere a la integridad y corrección del propio paquete de software ES. incluir:
- Verifique la versión de Lucene. Cada versión de ES requiere el uso de la versión de Lucene. Verifique la versión de Lucene aquí para evitar que alguien reemplace el paquete jar incompatible.
- Verifique el conflicto de jar y salga del proceso si se encuentra el conflicto.
2.5 Verifique el entorno externo
El "nodo" en ES se encapsula como un módulo de nodo cuando se implementa. Llame a otros componentes internos de la clase Node y proporcione métodos de inicio y apagado al exterior. La inspección del entorno externo se realiza en Node.start ().
El entorno externo se refiere a la JVM y los parámetros relacionados con el sistema operativo en tiempo de ejecución, que se denominan " Boostrap Check " en ES . En la primera versión de ES, ES detectó una configuración poco razonable y la registró en el registro para continuar ejecutándose. Pero a veces los usuarios pierden estos registros. Para no descubrir problemas más adelante, ES comprueba esos parámetros importantes durante la fase de inicio, algunas configuraciones que afectan el rendimiento serán marcadas como errores, para que los usuarios presten suficiente atención a estos parámetros.
Todas estas comprobaciones se encapsulan individualmente en la clase BoostrapChecks. Actualmente existen los siguientes elementos de detección:
2.5.1 Verificación del tamaño del montón
Si el tamaño de pila inicial de JVM (Xms) es diferente del tamaño de pila máximo (Xmx), puede haber una pausa cuando el tamaño de pila de JVM se ajusta durante el uso . Por lo tanto, debe establecerse en el mismo valor.
Si bootstrap.mempry_block está habilitado , la JVM bloqueará el tamaño inicial del par al inicio. Si el tamaño de pila inicial es diferente del tamaño máximo de pila, después de que cambia el tamaño de pila, es posible que no se garantice que todas las pilas de JVM estén bloqueadas en la memoria.
Para pasar esta verificación, se debe configurar el tamaño del montón.
2.5.2 Comprobación del descriptor de archivo
En los sistemas basados en UNIX, los "archivos" pueden ser archivos físicos ordinarios o archivos virtuales, y los sockets de red también son descriptores de archivos. El proceso de ES requiere muchos descriptores de archivos. Por ejemplo, cada fragmento tiene muchos segmentos y cada segmento tiene muchos archivos. También incluye muchas conexiones de red con otros nodos.
Para pasar esta verificación, debe ajustar la configuración predeterminada del sistema. En Linux, ejecute ulimit -n 65536 (válido solo para el terminal actual), o configure " - nofile 65536" en el archivo ** / etc / security / limits.conf * (válido para todos los usuarios). Limits.conf en Ubuntu se ignora de forma predeterminada y el módulo pam_limits.so debe estar habilitado.
Dado que la versión de Ubuntu se actualiza con relativa rapidez y el entorno de producción no es adecuado para actualizaciones frecuentes, recomendamos utilizar CentOS como sistema operativo del servidor.
* soft nofile 131072
* hard nofile 131072
2.5.3 Verificación de bloqueo de memoria
ES permite que los procesos utilicen solo memoria física y evita el uso de particiones de intercambio. De hecho, recomendamos deshabilitar directamente la partición de intercambio del sistema operativo en un entorno de producción. Ahora hemos implementado la era en la que la memoria debe cambiarse al disco duro debido a la falta de memoria.Para los servidores, cuando la memoria está realmente agotada, el cambio al disco duro causará más problemas.
Habilite la opción bootstrap.memory_lock para permitir que ES bloquee la memoria. Cuando esta verificación está activada y el bloqueo falla, la ejecución de esta verificación falla.
2.5.4 Comprobación del número máximo de subprocesos
ES descompone la solicitud en ejecución en cada nodo y cada etapa utiliza un grupo de subprocesos diferente para ejecutarse. Por lo tanto, el proceso de ES necesita crear muchos subprocesos. Esta verificación es para garantizar que el proceso de ES tenga la autoridad para crear suficientes subprocesos. Esta verificación solo se realiza en sistemas Linux. Debe ajustar el número máximo de subprocesos que puede crear un proceso. Este valor es al menos 2048.
Para pasar esta verificación, puede modificar el nproc en el archivo ** /etc/security/limits.conf para completar la configuración
* soft nproc 131072
* hard nproc 131072
Y /etc/security/limits.d/90-nproc.conf
* soft nproc 131072
* hard nproc 131072
2.5.5 Comprobación de la memoria virtual máxima
Lucene utiliza mmap para asignar parte del índice al espacio de direcciones del proceso. La verificación de memoria virtual máxima asegura que el proceso ES tenga suficiente espacio de direcciones. Esta verificación solo se realiza en Linux.
Para pasar esta verificación, se puede modificar la seguridad ** / etc / / limits.conf archivo y conjunto como a ilimitada **.
* soft as unlimited
* hard as unlimited
2.5.6 Comprobación del tamaño máximo de archivo
Los archivos de segmento y los archivos de registro de transacciones se almacenan en el disco local y pueden ser muy grandes. En un sistema operativo con un límite máximo de tamaño de archivo, puede provocar errores de escritura. Se recomienda establecer el tamaño del archivo más grande en ilimitado.
Para pasar esta verificación, puede modificar el archivo ** / etc / security / limits.conf y modificar el fsize a ilimitado **.
* soft fsize unlimited
* hard fsize unlimited
2.5.7 Comprobación del número máximo de áreas de memoria virtual
El proceso ES necesita crear una gran cantidad de áreas mapeadas en memoria Esta verificación es para asegurar que el kernel permite que se creen al menos 262144 áreas mapeadas en memoria. Esta verificación solo se realiza en Linux.
Para pasar esta verificación, puede ejecutar el siguiente comando (temporalmente efectivo, no válido después de reiniciar):
sysctl -w vm.max_map_count = 262144
O agregue una línea vm.max_map_count = 262144 ** al archivo ** / etc / sysctl.conf , y luego ejecute el siguiente comando (inmediata y permanentemente):
vm.max_map_count=262144
sysctl -p
2.5.8 Comprobación de OnError y OnOutOfMemoryError
Si la JVM encuentra un error fatal (OnError) o (OnOutOfMemoryError), entonces las opciones de JVM OnError y OnOutOfMemoryError pueden ejecutar comandos arbitrarios.
Sin embargo, de forma predeterminada, el filtro de llamadas del sistema ES está habilitado (seccomp) y la bifurcación se bloqueará. Por lo tanto, el uso de OnError u OnOutOfMemoryError no es compatible con los filtros de llamadas del sistema.
Para pasar esta verificación, no habilite OnError u OnOutOfMemoryError, pero actualice a Java 8u92 y use ExitOnOutOfMemoryError.
Evite que el nodo ES esté en un estado inactivo y no pueda recuperarse después del desbordamiento de la memoria, lo que afecta a todo el clúster. Cuando el proceso aparece OOM, el proceso se cerrará, saldrá del clúster ES y provocará una alarma, y luego se reiniciará.
Agregue los parámetros de inicio de la JVM en config / jvm.options:
-XX:+ExitOnOutOfMemoryError
2.6 Iniciar módulos internos
Una vez completada la verificación del entorno, inicie cada submódulo. Los submódulos se crean en la clase Node y sus respectivos métodos start () se llaman cuando se inician, por ejemplo:
- discovery.start ();
- clusterServer.start ();
- nodeConnectionsService.start ();
El método de inicio del submódulo es básicamente inicializar datos internos, crear un grupo de subprocesos, iniciar el grupo de subprocesos y otras operaciones.
2.7 Iniciar el hilo keepalive
Llame al método keepAliveThread.start () para iniciar el hilo keepalive, el hilo en sí no hace un trabajo específico. El hilo principal se cerrará después de ejecutar el proceso de inicio. El hilo keepalive es el único hilo del usuario y su función es mantener el proceso en ejecución. En un programa Java, solo hay un hilo de usuario. Salga del proceso cuando el número de hebras de yogur sea cero.
3. Proceso de cierre del nodo
Ahora discutimos el proceso de apagado de un solo nodo. Imagine que cuando actualizamos la configuración y actualizamos la versión del clúster ES, necesitamos "matar" el proceso ES para cerrar el nodo. ¿Pero es segura la operación de matar? ¿Cuál será el impacto si el nodo está realizando operaciones de lectura y escritura en este momento? Si el nodo es el maestro, ¿qué debe hacer el maestro? ¿Cómo se logra el proceso de apagado? ¿Qué riesgos traerán los nodos de eliminación?
La respuesta es: el proceso ES capturará la señal SIGTERM (la señal predeterminada del comando kill) para su procesamiento, llamará al método de detención de cada módulo y les dará la oportunidad de detener el servicio y salir de manera segura.
-
El nodo maestro está apagado
Durante el reinicio del clúster, si el nodo maestro se apaga , el clúster volverá a elegir al maestro. Durante este período, el clúster tiene un estado de corta duración sin maestro. Si el nodo maestro en el clúster se implementa por separado, después de elegir el nuevo maestro, puede omitir la puerta de enlace y el proceso de recuperación; de lo contrario, el nuevo maestro debe redistribuir los fragmentos en poder del antiguo maestro: promover otras réplicas para que sean los fragmentos maestros y asignar El nuevo fragmento de réplica.
-
El nodo de datos está cerrado
Si el nodo de datos está cerrado, la conexión TCP para la solicitud de lectura y escritura también se cerrará y la operación de escritura falla para el cliente. Sin embargo, si el proceso de escritura ha llegado al enlace del motor, la escritura se completará normalmente, pero el cliente no puede percibir el resultado. En este momento, el cliente vuelve a intentarlo. Si se utiliza el ID generado automáticamente, el contenido de los datos se repetirá.
En resumen, el impacto de la actualización continua es la interrupción de la solicitud de escritura actual y el proceso de asignación de fragmentos que puede ser causado por el reinicio del nodo maestro. Por lo general, es más rápido actualizar un nuevo fragmento primario, por lo que tiene poco impacto en la disponibilidad de escritura del clúster.
Cuando no se asigna el fragmento primario de la parte del índice, si se usa el ID generado automáticamente, si la escritura continúa, el cliente puede volver a intentar el error (la solicitud llega al fragmento primario que se ha asignado correctamente), pero estará en una diferente La desviación de datos se produce entre los sectores y el grado de desviación depende del número de períodos.
4. Cerrar el análisis del proceso
Durante el proceso de inicio del nodo, se agrega un gancho de apagado al método de configuración Bootstrap #. Cuando el proceso recibe el sistema SIGTERM (señal predeterminada de eliminación) o la señal SIGINT, se llama al proceso de apagado del nodo.
Hay doStop y doClose en el Servicio de cada módulo, que se utilizan para manejar el proceso de cierre normal de este módulo. El proceso de cierre general del nodo se encuentra en Node # cloase. En la implementación del método close, primero llame al doStop de cada módulo, y luego recorra cada módulo nuevamente para ejecutar doClose. El código de implementación principal es el siguiente:
if(lifecycle.started()){
stop();//调用各个模块的dostop方法
}
List<Closeable> toClose = new ArrayList<>();
//在toClose中添加所需要关闭的Service,以nodeService为例
toClose.add(nodeService);
......
//调用各模块doClose方法
IOUtils.close(toClose);
El cierre de cada módulo tiene una cierta relación de secuencia. Tomando doStop como ejemplo, llame al método doStop de cada módulo en el orden que se muestra en la siguiente tabla.
| Servicio | Introducción |
|---|---|
| ResourceWatcherService | Servicio de supervisión de recursos generales |
| HttpServerTransport | Servicio de transmisión HTTP, que proporciona un servicio de interfaz REST. |
| Servicio de instantáneas | Servicio de instantáneas |
| SnapshotShardsService | Responsable de iniciar y detener instantáneas a nivel de fragmentos |
| IndicesClusterStateService | Después de recibir la información del estado del clúster, procese las operaciones relacionadas con el índice |
| Descubrimiento | Gestión de topología de clústeres |
| RoutingService | Manejo de redireccionamiento (migración de fragmentos entre nodos) |
| ClusterService | Servicio de gestión de clústeres. Maneja principalmente las tareas del clúster y publica el estado del clúster |
| NodeConnectionsService | Servicio de canalización de conexión de nodo |
| MonitorService | Proporcionar servicios de supervisión de JVM a nivel de proceso, de sistema, de sistema de archivos |
| GatewayService | Responsable de la persistencia y recuperación de metadatos del clúster |
| SearchService | Procesando solicitud de búsqueda |
| Servicio de transporte | Servicio de transporte subyacente |
| complementos | Todos los complementos actuales |
| IndicesService | Responsable de las operaciones de índice, como crear y eliminar índices. |
En conjunto, la secuencia de cierre es aproximadamente la siguiente:
- Cierre la instantánea y HTTPServer y deje de responder a las solicitudes REST del usuario.
- Cierre la administración de la topología de la máquina y deje de responder a las solicitudes de ping.
- Cierre el módulo de red y deje que el nodo se desconecte.
- Realice el proceso de cierre de cada complemento.
- Cerrar IndicatorsService.
Finalmente, el IndicatorService está cerrado porque los recursos que deben liberarse durante este período son los más y los más largos.
5. Realice el apagado durante la lectura y escritura del fragmento
A continuación se analizan los nodos que están cerrados durante el proceso de ejecución de lectura y escritura.
5.1 Cerrado durante la escritura
Cuando un hilo escribe datos, agregará un bloqueo de escritura al motor. El método doStop de IndicesService indexa todos los índices de este nodo y ejecuta removeIndex. Cuando se ejecuta flushAndClose del motor (primero descarga y luego cierra el motor), también agregará un bloqueo de escritura al motor. Dado que el bloqueo de escritura se ha agregado a la operación de escritura, el bloqueo de escritura esperará hasta que se complete la escritura. Por lo tanto, el proceso de escritura de datos no se interrumpirá. Pero debido a que el módulo de red está cerrado, la conexión del cliente se desconectará. El cliente debe manejar la falla, aunque el proceso de escritura del servidor ES aún continúa.
5.2 Cerrar el proceso de lectura
Cuando un hilo lee datos, agregará un bloqueo de lectura al motor. El bloqueo de escritura en flushAndClose esperará a que se complete el proceso de lectura. Sin embargo, debido a que la conexión está cerrada, no se puede enviar al cliente, lo que hace que el cliente no pueda leer.
La siguiente figura muestra el proceso de lavado y cierre del motor: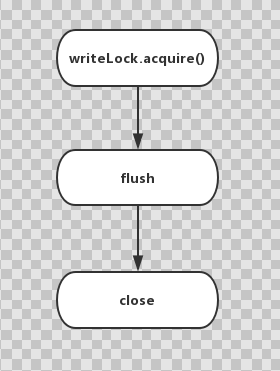
Durante el proceso de apagado del nodo, doStop de IndicatorService establece un tiempo de espera para el motor. Si flushAnd ha estado esperando, CountDownLatch.await continuará el siguiente proceso de forma predeterminada durante 1 día.
6. El nodo principal está apagado.
Cuando se apaga el nodo maestro, no hay un procesamiento especial como se imagina. El nodo ejecuta el proceso de apagado normalmente. Cuando se apaga el módulo TransportSerice, el clúster re-elige un nuevo maestro. por lo tanto. Durante el reinicio continuo, habrá un período de tiempo en un estado sin propietario.
7. Resumen
- En general, el proceso de inicio del nodo consiste en inicializar y verificar, después de que cada submódulo se inicia de forma asincrónica, carga datos locales, o selecciona el maestro, se une al clúster, etc., que se presentan por separado en los siguientes capítulos.
- El nodo tiene la oportunidad de procesar datos incompletos cuando se apaga, pero puede que no sea demasiado tarde para notificar al cliente después de que se escriben. Incluidas las tareas que aún no se han ejecutado en el grupo de subprocesos, tienen la posibilidad de ejecutarse dentro de un cierto período de tiempo de espera.
El tiempo para que la salud del clúster cambie de rojo a verde se consume principalmente para mantener la consistencia de los fragmentos primarios y secundarios. También podemos optar por permitir que el cliente escriba cuando el estado del clúster sea amarillo, pero se sacrificará parte de la seguridad de los datos.
/etc/security/limits.conf
文件描述符配置
* soft nofile 131072
* hard nofile 131072
最大线程数检查
* soft nproc 131072
* hard nproc 131072
/etc/security/limits.d/90-nproc.conf
* soft nproc 1024
最大虚拟内存检查
* soft as unlimited
* hard as unlimited
最大文件大小检查
* soft fsize unlimited
* hard fsize unlimited
虚拟内存区域最大数量检查
/etc/sysctl.conf
vm.max_map_count=262144
件描述符配置
* soft nofile 131072
* hard nofile 131072
最大线程数检查
* soft nproc 131072
* hard nproc 131072
/etc/security/limits.d/90-nproc.conf
* soft nproc 1024
最大虚拟内存检查
* soft as unlimited
* hard as unlimited
最大文件大小检查
* soft fsize unlimited
* hard fsize unlimited
虚拟内存区域最大数量检查
/etc/sysctl.conf
vm.max_map_count=262144
8. Sígueme
Buscar en la cuenta pública de WeChat: el camino hacia una arquitectura java sólida
