Hoy en día, el aprendizaje profundo puede producir resultados sorprendentes en el campo de la síntesis y el procesamiento de imágenes. Ya hemos visto ejemplos de sitios web que ilusionan a las personas con imaginación, videos que muestran celebridades que dicen cosas que nunca han dicho y herramientas que hacen bailar a las personas. Estos ejemplos son lo suficientemente ciertos como para engañar a la mayoría de nosotros. Una de las nuevas hazañas es FaceShifter [1], que es un modelo de aprendizaje profundo que puede intercambiar caras en imágenes superiores a la última tecnología. En este artículo, entenderemos cómo funciona.
Planteamiento del problema
Tenemos una imagen de cara de origen Xₛ y una imagen de cara de destino Xₜ. Queremos generar una nueva imagen de cara Yₛ, que tenga los atributos de Xₜ (postura, iluminación, gafas, etc.), pero que tenga la identidad de la persona en Xₛ. La Figura 1 resume esta declaración del problema. Ahora, seguimos explicando el modelo.

Figura 1 Cambiar la declaración del problema facial. Los resultados mostrados son del modelo FaceShifter. Adaptado de [1].
Modelo FaceShifter
FaceShifter consta de dos redes, llamadas red AEI y red HEAR. La red AEI genera un resultado de intercambio facial preliminar, y la red HEAR optimiza la salida. Analicemos los dos por separado.
Red AEI
La red AEI es la abreviatura de "Adaptive Embedded Integrated Network". Esto se debe a que la red AEI consta de 3 subredes:
- Codificador de identidad: un codificador que incorpora Xₛ en un espacio que describe la identidad de una cara en una imagen.
- Codificador de atributos multinivel: un codificador que incorpora Xₜ en un espacio que describe los atributos que se deben retener al intercambiar caras.
- Generador AAD: un generador que integra la salida de las dos primeras subredes para generar el intercambio de caras en el logotipo de Xₜ y Xₛ.
La red AEI se muestra en la Figura 2. Vamos a concretar sus detalles.

Figura 2 La arquitectura de la red AEI. Adaptado de [1].
Codificador de identidad
Esta subred proyecta la imagen de origen Xₛ en un espacio de características de baja dimensión. La salida es solo un vector, que llamamos zᵢ, como se muestra en la Figura 3. Este vector codifica la identidad de la cara en Xₛ, lo que significa que debe extraer las características que los humanos usamos para distinguir las caras de diferentes personas, como la forma de los ojos, la distancia entre los ojos y la boca, la curvatura de la boca, etc.
El autor utiliza un codificador pre-entrenado. Utilizaron una red de reconocimiento facial capacitada. Se espera que esto cumpla con nuestros requisitos, porque la red para distinguir rostros debe extraer características relacionadas con la identidad.

Figura 3 Codificador de identidad. Adaptado de [1].
Codificador de atributo multinivel
La subred codifica la imagen de destino X. Genera múltiples vectores, cada uno de los cuales describe los atributos de Xₜ con diferentes resoluciones espaciales.En general, hay 8 vectores de características, llamados zₐ. El atributo aquí se refiere a la estructura facial en la imagen objetivo, como la postura, el contorno, la expresión facial, el peinado, el color de la piel, el fondo, la iluminación de la escena, etc. de la cara. Como se muestra en la Figura 4, es un ConvNet con una estructura de red en forma de U, en la que el vector de salida es solo un mapa de características de cada nivel en la sección de decodificación / escala superior. Tenga en cuenta que esta subred no está preformada.

Figura 4 Arquitectura de codificador de atributos multinivel. Adaptado de [1].
Representar a Xₜ como incrustaciones múltiples es necesario porque usar una incrustación en una única resolución espacial dará como resultado la pérdida de información en la imagen de salida deseada que genera la superficie de intercambio (es decir, queremos retener demasiados detalles finos de Xₜ, lo que hace que la compresión La imagen no es factible). Esto es evidente en los estudios de ablación realizados por los autores, que trataron de utilizar solo las primeras 3 incrustaciones zₐ en lugar de las 8 incrustaciones zₐ para representar Xₜ, lo que provocó que el resultado de la Figura 5 fuera más borroso.

Figura 5 Use múltiples incrustaciones para representar el efecto del objetivo. Si se utilizan las primeras 3 incrustaciones zₐ, la salida se comprime; si se usan las 8 incrustaciones, la salida es AEI Net. Adaptado de [1].
Generador de AAD
El generador AAD es una abreviatura de "Generador de desnormalización de atención adaptativa". Sintetiza la salida de las dos primeras subredes para mejorar la resolución espacial, produciendo así la salida final de la red AEI. Se logra superponiendo un nuevo bloque AAD Resblock, como se muestra en la Figura 6.

Figura 6 La arquitectura del generador AAD en la imagen de la izquierda y el AAD Resblock en la imagen de la derecha. Adaptado de [1].
La nueva parte de este bloque es la capa AAD. Lo dividimos en 3 partes, como se muestra en la Figura 7. En un nivel superior, la Parte 1 nos dice cómo editar el mapa de características de entrada hᵢ para que se parezca más a Xₜ en términos de atributos. Específicamente, genera dos tensores del mismo tamaño que hᵢₙ, un tensor contiene el valor de escala multiplicado por cada celda en hᵢₙ, y el otro tensor contiene el valor de desplazamiento. La entrada de la capa 1 es uno de los vectores de atributos. Del mismo modo, la Parte 2 nos dirá cómo editar el mapa de características hᵢ para que se parezca más a Xₛ.

Figura 7 Arquitectura de capa AAD. Adaptado de [1].
La tarea de la Parte 3 es seleccionar la parte (2 o 3) en la que deberíamos centrarnos en cada celda / píxel. Por ejemplo, en la celda / píxel relacionado con la boca, la red nos dirá que nos centremos más en la Parte 2 porque la boca está más relacionada con la identidad. Esto se demuestra empíricamente mediante un experimento que se muestra en la Figura 8.

Figura 8 Un experimento que muestra lo aprendido en la Parte 3 de la capa AAD. La imagen de la derecha muestra la salida de la tercera parte del número asíncrono / resolución espacial en todo el generador AAD. El área brillante indica que debemos prestar atención a la identidad de la célula (es decir, parte 2), el área negra significa que debemos prestar atención a la parte 1. Tenga en cuenta que a alta resolución espacial, nuestro enfoque principal está en la Parte 1.
De esta manera, el generador de AAD podrá construir la imagen final paso a paso y, en cada paso, determinará la mejor manera de ampliar el mapa de características actual para una identidad y un código de atributo determinados.
Ahora tenemos una red, la red AEI, que puede integrar Xₛ y Xₜ e integrarlos de una manera que logre nuestros objetivos. Llamamos a la salida de AEI Net Yₛₜ *.
Función de pérdida de entrenamiento
En términos generales, la pérdida es una fórmula matemática que esperamos que la red logre su propósito. Hay 4 pérdidas en el entrenamiento de la red AEI:
- Queremos que muestre un rostro humano real, por lo que tendremos una pérdida de confrontación, al igual que cualquier red de confrontación.
- Esperamos que la cara generada tenga la identidad de Xₛ. Nuestro único objeto matemático que puede representar la identidad es zᵢ. Por lo tanto, este objetivo puede expresarse mediante las siguientes pérdidas:
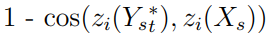
- Queremos que la salida tenga atributos Xₜ. Las pérdidas son:
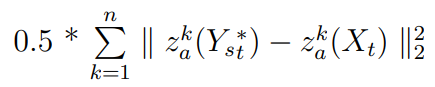
- El autor agrega otra pérdida basada en la opinión de que la red debería generar Xₜ (si Xₜ y Xₛ son en realidad la misma imagen):

Creo que esta última pérdida es necesaria para conducir el atributo de codificación real zₐ, porque no está pre-entrenado como zᵢ. Sin ella, la red AEI puede ignorar Xₜ y hacer que zₐ solo produzca 0.
Nuestra pérdida total es solo una suma ponderada de pérdidas anteriores.
Escuchar red
La red AEI no es solo una red completa capaz de cambiar de cara. Sin embargo, no es lo suficientemente bueno para ser consistente. Específicamente, cada vez que algo en la imagen de destino oscurece parte de la cara (como anteojos, sombrero, cabello o manos) que debería aparecer en la salida final, la red AEI lo elimina. Estas cosas aún deberían existir, porque no tiene nada que ver con el logotipo que se va a cambiar. Por lo tanto, el autor ha implementado una red adicional llamada "red de refinamiento de confirmación de error heurístico", que tiene la única tarea de recuperar dicha oclusión.
Se dieron cuenta de que cuando configuraban la entrada de la red AEI (es decir, Xₛ y Xₜ) en la misma imagen, todavía no conservaba la oclusión como se muestra en la Figura 9.

Figura 9 La salida de AEI Net cuando ingresamos la misma imagen que Xₛ y Xₜ. Observe cómo se pierde la cadena en el pañuelo en la salida. Adaptado de [1].
Por lo tanto, no utilizaron Yₛₜ * y Xₜ como entrada a la red HEAR, sino que lo configuraron en Yₛₜ * & (Xₜ-Yₜₜ *), donde Yₜₜ * es la salida de la red AEI cuando Xₛₜ * y Xₜ son la misma imagen. Esto dirigirá a la red HEAR para que ocluya píxeles no reservados. Como se muestra en la Figura 10.

Figura 10 La estructura de la red HEAR. Adaptado de [1].
Función de pérdida de entrenamiento
La función de pérdida de la red HEAR es:
- Pérdidas por retención de identidad:

- No cambia sustancialmente la pérdida de Yₛₜ *:
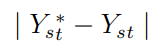
- Si Xₛ y Xₜ son la misma imagen, entonces la salida de la red HEAR debería ser Xₜ:
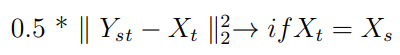
La pérdida total es la suma de estas pérdidas.
El resultado
El efecto del cambiador de cara es asombroso. En la Figura 11, puede encontrar algunos ejemplos de su rendimiento de generalización en imágenes distintas del conjunto de datos en el que está diseñado (es decir, de un conjunto de datos más amplio). Observe cómo funciona correctamente en condiciones diferentes y difíciles.

Figura 11 Los resultados muestran que el convertidor tiene un buen rendimiento. Adaptado de [1].
Autor: Ahmed Maher
Traducido por: tensor-zhang
