¿Es la conversión de voz AI realmente lo más complicada posible? Este documento propone un modelo de conversión de idioma simple pero igualmente poderoso, que es tan natural y claro como el método de línea de base, y la similitud ha mejorado mucho.
El mundo de la voz en el que participa la IA es realmente asombroso, puede cambiar la voz de una persona por la de cualquier otra persona, y también puede intercambiar voces con animales.
Sabemos que el objetivo de la conversión de voz es convertir la voz de origen en la voz de destino, manteniendo el contenido sin cambios. Los métodos recientes de conversión de voz de cualquiera a cualquier han mejorado la naturalidad y la similitud del hablante, pero a expensas de una complejidad sustancialmente mayor. Esto significa que el entrenamiento y la inferencia se vuelven más costosos, lo que dificulta la evaluación y el establecimiento de mejoras.
La pregunta es, ¿la conversión de voz de alta calidad requiere complejidad? En un artículo reciente de la Universidad de Stellenbosch en Sudáfrica, varios investigadores exploraron esta pregunta.

Dirección en papel: https://arxiv.org/pdf/2305.18975.pdf
Dirección de GitHub: https://bshall.github.io/knn-vc/
Lo más destacado de la investigación es que presentan K-Nearest Neighbor Voice Conversion (kNN-VC), un método simple y poderoso para la conversión de voz de cualquiera a cualquier . No se entrena ningún modelo de transformación explícito en el proceso, sino que simplemente se utiliza la regresión K-vecinos más cercanos.
Específicamente, los investigadores primero usan un modelo de representación de voz autosupervisado para extraer las secuencias de características de la expresión de origen y la expresión de referencia, luego convierten cada cuadro de la representación de origen en el hablante de destino reemplazando a su vecino más cercano en la referencia y finalmente usan un codificador de voz neuronal para sintetizar las características transformadas para obtener el habla transformada.
A partir de los resultados, a pesar de su simplicidad, KNN-VC iguala o incluso mejora la inteligibilidad y la similitud del hablante en evaluaciones subjetivas y objetivas en comparación con varios sistemas de conversión de voz de referencia.
Apreciemos el efecto de la conversión de voz KNN-VC. Veamos primero la conversión vocal, aplicando KNN-VC a hablantes de origen y de destino invisibles en el conjunto de datos de LibriSpeech.
Voz de la fuente : Empújame para escuchar el audio
Voz Sintética 1 : Empújame para escuchar el audio
Discurso Sintético 2 : Empújame para escuchar el audio
KNN-VC también admite la conversión de voz en varios idiomas, como español a alemán, alemán a japonés y chino a español.
Fuente chino : Empújame para escuchar el audio.
Español objetivo : tócame para escuchar el audio
Discurso Sintético 3 : Empújame para escuchar el audio
Lo que es aún más sorprendente es que KNN-VC también puede intercambiar voces humanas con ladridos de perros.
Fuente perro ladrando : pinchame para escuchar el audio
Voz de origen : Empújame para escuchar el audio.
Discurso Sintético 4 : Empújame para escuchar el audio
Discurso Sintético 5 : Empújame para escuchar el audio
A continuación, vemos cómo funciona KNN-VC y comparamos los resultados con otros métodos jixian.
Descripción general del método y resultados experimentales
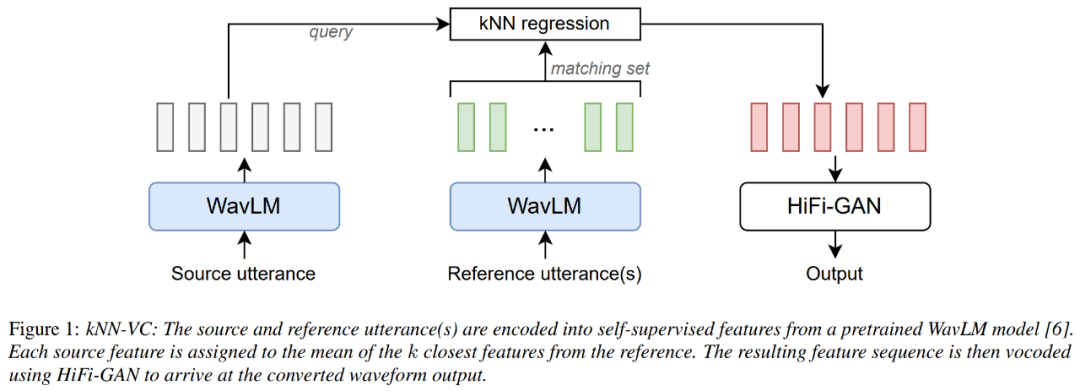
A continuación se muestra el diagrama de arquitectura de kNN-VC, que sigue la estructura codificador-convertidor-vocodificador. Primero, un codificador extrae representaciones autosupervisadas de la fuente y el habla de referencia, luego un transformador asigna cada cuadro fuente a sus vecinos más cercanos en la referencia y, finalmente, un codificador de voz genera formas de onda de audio basadas en las características transformadas.
El codificador usa WavLM, el convertidor usa K regresión de vecino más cercano y el vocoder usa HiFiGAN. El único componente que necesita ser entrenado es el codificador de voz.
Para el codificador WavLM, solo usamos el modelo WavLM-Large previamente entrenado y no lo entrenamos en este documento. Para el modelo de conversión kNN, kNN no es paramétrico y no requiere ningún entrenamiento. Para el codificador de voz HiFiGAN, las características de WavLM se codificaron mediante el repositorio del autor original de HiFiGAN, convirtiéndose en la única parte que requirió capacitación.
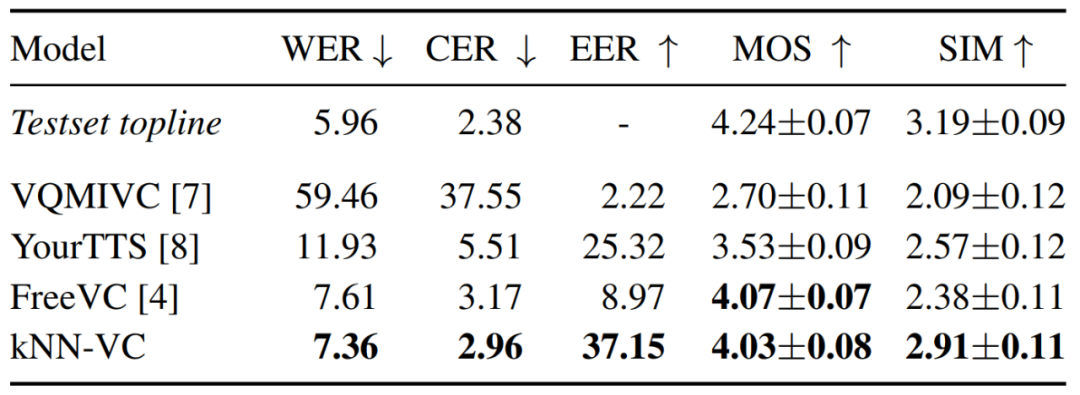
En los experimentos, los investigadores primero compararon KNN-VC con otros métodos de referencia, utilizando los datos objetivo más grandes disponibles (aproximadamente 8 minutos de audio por altavoz) para probar el sistema de conversión de voz.
Para KNN-VC, los investigadores utilizan todos los datos objetivo como conjunto coincidente. Para el método de referencia, promedian las incrustaciones de hablantes para cada expresión de destino.
La Tabla 1 a continuación informa los resultados de inteligibilidad, naturalidad y similitud del hablante para cada modelo. Como puede verse, kNN-VC logra una naturalidad e inteligibilidad similares a las del mejor FreeVC básico, pero con una similitud de altavoz significativamente mayor. Esto también confirma la tesis de este documento: la conversión de voz de alta calidad no necesita aumentar la complejidad.
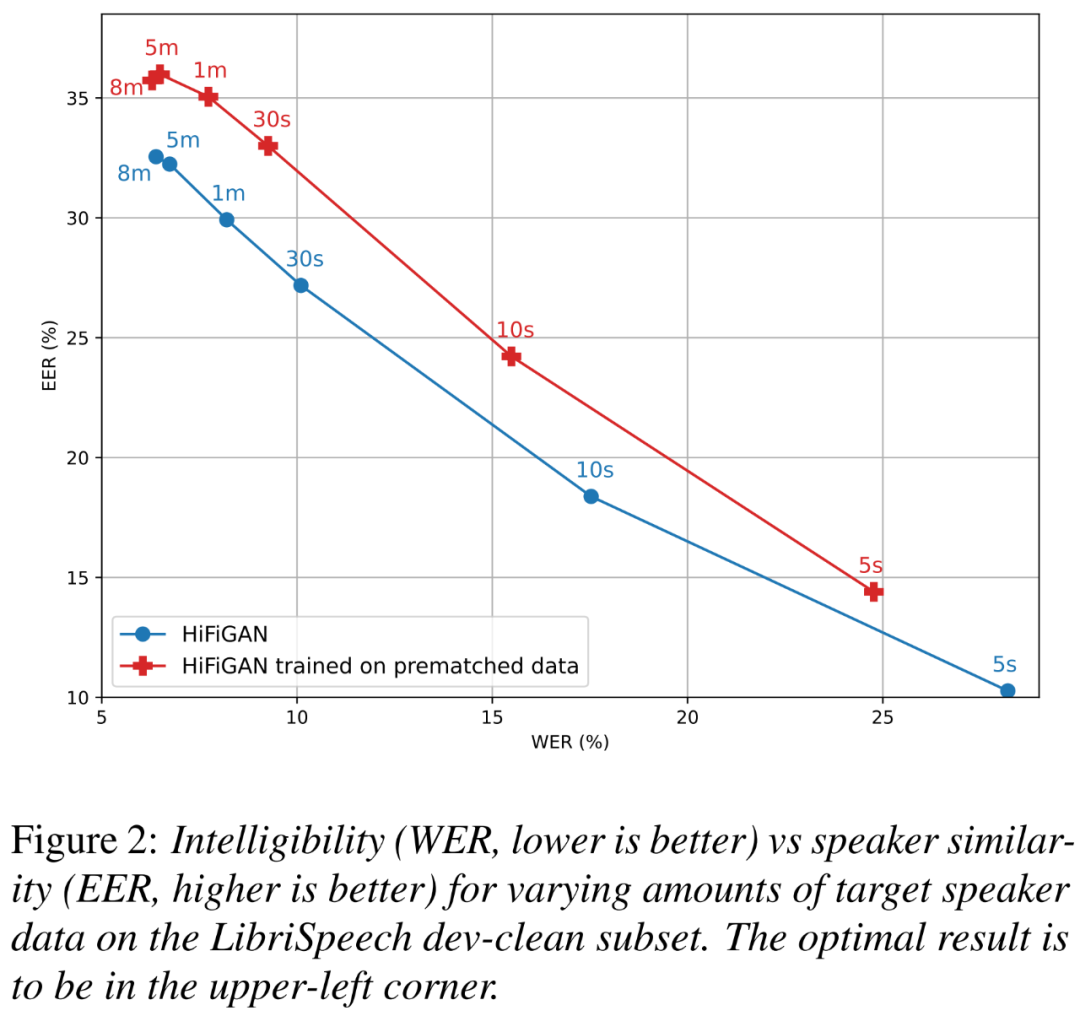
Además, los investigadores querían comprender cuánta mejora se debe a HiFi-GAN entrenado con datos precoincidenciales, y cuánto afecta el tamaño de los datos del altavoz objetivo a la inteligibilidad y la similitud del altavoz.
La Figura 2 a continuación muestra los gráficos WER (más pequeño es mejor) y EER (más alto es mejor) para dos variantes de HiFi-GAN en diferentes tamaños de altavoces de destino.
Comentarios calientes de los internautas
Para este nuevo método de conversión de voz kNN-VC que "usa solo el vecino más cercano", algunas personas piensan que el modelo de voz preentrenado se usa en el artículo, por lo que no es exacto usar "solo". Pero es innegable que kNN-VC sigue siendo más simple que otros modelos.
Los resultados también demuestran que kNN-VC es igual de efectivo, si no el mejor, en comparación con los muy complejos métodos de conversión de voz de cualquiera a cualquiera.

Otros dijeron que el ejemplo de la voz humana intercambiándose con el ladrido del perro es muy interesante.