Directorio
6. La parte de convolución intermedia de la red.
7. Implementación de bloque residual
10. Resumido de la siguiente manera
1. El problema
Los problemas de desaparición de gradiente y explosión de gradiente evitan la convergencia inicial, que se resuelve mediante la normalización de la inicialización y la normalización de la capa intermedia. Después de resolver el problema de la convergencia, vuelve a ocurrir un fenómeno de degradación: a medida que se profundiza el número de capas, la precisión aumenta y luego disminuye bruscamente. Y esta degradación no es causada por el sobreajuste, y agregar capas apropiadas a la red da como resultado mayores errores de entrenamiento. A medida que aumenta la profundidad de la red, la precisión del modelo no siempre mejora, y este problema no es causado por el sobreajuste, porque no solo el error de prueba aumenta después de que la red se profundiza, sino que su error de entrenamiento también aumenta. . El autor propone que esto puede deberse a que la red más profunda estará acompañada de problemas de desaparición / explosión de gradiente, lo que obstaculizará la convergencia de la red. Este fenómeno de profundizar la profundidad de la red pero degradar el rendimiento de la red se llama un problema de degradación. Es decir, a medida que aumenta la profundidad, hay una degradación significativa, y el error de entrenamiento y el error de prueba de la red aumentan significativamente. ResNet nació para resolver este problema de degradación.
2 、Como arreglar
Entonces, el autor propone una solución: agregar más capas en una arquitectura menos profunda. Para modelos más profundos: la capa agregada es el mapeo de identidad, y las otras capas se copian del modelo superficial aprendido. En este caso, el modelo más profundo no debería producir errores de entrenamiento más altos que su red menos profunda correspondiente. La unidad básica de aprendizaje residual:
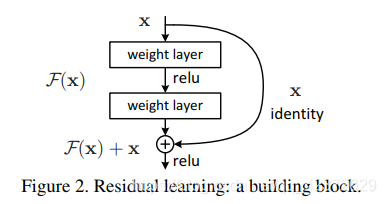
La entrada de red original x, espero que salga H (x). Ahora dejamos que H (x) = F (x) + x, entonces nuestra red solo necesita aprender a generar un F (x) = H (x) -x residual.
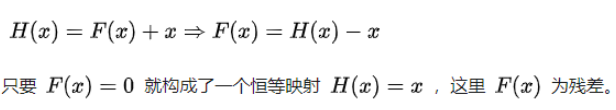
Suponiendo que la entrada es x, el mapeo aprendido por dos capas completamente conectadas es H (x), lo que significa que las dos capas se pueden ajustar asintóticamente a H (x). Suponiendo que las dimensiones de H (x) yx son las mismas, ajustar H (x) es equivalente a ajustar la función residual H (x) -x. Deje que la función residual F (x) = H (x) -x, luego el original La función se convierte en F (x) + x, por lo que una conexión de capa cruzada se agrega directamente a la red original. La conexión de capa cruzada aquí también es muy simple, es decir, el mapeo de identidad de x se pasa al pasado .
3 、Por que funciona
- Profundidad adaptativa: el problema de la degradación de la red ejemplifica la dificultad de ajustar mapas de identidad en redes de múltiples capas, lo que significa que H (x) es difícil de ajustar x, pero después de usar la estructura residual, los mapas de identidad se convierten Es fácil aprender directamente todos los parámetros de red a 0, dejando solo la conexión de capa cruzada del mapeo de identidad. Entonces, cuando la red no necesita ser tan profunda, el mapeo de identidad en el medio puede ser un poco más, de lo contrario puede ser un poco menos.
- "Amplificador diferencial": suponiendo que la H (x) óptima esté más cerca del mapa de identidad, entonces es más probable que la red encuentre pequeñas fluctuaciones que no sean el mapa de identidad
- El gradiente de mitigación desaparece: se puede conocer la derivación de la entrada x para una estructura residual, debido a la existencia de conexiones entre capas, el gradiente total agregará 1 a la derivada de F (x) a x
La mayor diferencia entre la red ordinaria y la red residual profunda es que la red residual profunda tiene muchas ramas de derivación que conectan directamente la entrada a la capa posterior, de modo que la capa posterior puede aprender directamente la residual. Estas ramas se denominan atajos. En la capa convolucional tradicional o en la capa totalmente conectada, existen más o menos problemas de pérdida y pérdida de información cuando se transmite información. ResNet resuelve este problema hasta cierto punto: al pasar directamente la información de entrada a la salida para proteger la integridad de la información, toda la red solo necesita aprender la parte de la diferencia entre la entrada y la salida, simplificando los objetivos de aprendizaje y la dificultad.
4. Implementación de la red
Hay cinco formas principales de ResNet: Res18, Res34, Res50, Res101, Res152;
como se muestra en la siguiente figura, cada red incluye tres partes principales: la parte de entrada, la parte de salida y la parte de convolución intermedia (la parte de convolución intermedia incluye, por ejemplo, (Etapa1 a Etapa4 que se muestran en la figura son un total de cuatro etapas) . Aunque las variantes de ResNet son ricas, todas siguen las características estructurales anteriores. La diferencia entre las redes se debe principalmente a la diferencia en los parámetros del bloque y al número de partes de convolución intermedias. Tomemos ResNet18 como ejemplo para ver cómo se implementa toda la red.
class ResNet(nn.Module):
def forward(self, x):
# 输入
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
# 中间卷积
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# 输出
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
# 生成一个res18网络
def resnet18(pretrained=False, **kwargs):
model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet18']))
return model(1) Después de ingresar a la red, los datos primero pasan a través de la parte de entrada (conv1, bn1, relu, maxpool);
(2) Luego ingresa a la parte de convolución intermedia (capa1, capa2, capa3, capa4, la capa aquí corresponde a la etapa que mencionamos anteriormente) ;
(3) Finalmente, los datos se generan después de una agrupación promedio y una capa totalmente conectada (avgpool, fc);
específicamente, la diferencia entre resnet18 y otras redes de la serie res es principalmente capa1 ~ capa4, y otros componentes son similares.
5. Parte de entrada de red
La parte de entrada de todas las redes ResNet es un núcleo de convolución grande con tamaño = 7x7, stride = 2 y un tamaño máximo de agrupación = 3x3, stride = 2. A través de este paso, una imagen de entrada de 224x224 tendrá un tamaño de 56x56 El mapa de características reduce en gran medida el tamaño requerido para el almacenamiento.
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)6. La parte de convolución intermedia de la red.
La parte de convolución media es principalmente la parte del marco azul en la figura a continuación, y la información se extrae mediante el apilamiento de convoluciones 3 * 3. [2, 2, 2, 2] y [3, 4, 6, 3] en el cuadro rojo representan los tiempos repetidos de apilamiento de bolck.
Hay una oración ResNet (BasicBlock, [2, 2, 2, 2], * kwargs) en la función resnet18 () que acabamos de llamar. El [2, 2, 2, 2] aquí es consistente con el cuadro rojo en la figura, si Cambia esta línea de código a ResNet (BasicBlock, [3, 4, 6, 3], * kwargs), luego obtendrá una red res34.
7. Implementación de bloque residual
Echemos un vistazo más de cerca a cómo se implementa un bloque residual. En el bloque básico que se muestra en la figura a continuación, los datos de entrada se dividen en dos rutas, una ruta pasa a través de dos convoluciones 3 * 3, la otra ruta se acorta directamente La suma es producida por relu, que es muy simple.
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out8. Parte de salida de red
La parte de salida de la red es muy simple: a través de la agrupación global adaptativa, todos los mapas de características se extraen en 1 * 1. Para res18, los datos de entrada de 1x512x7x7 se extraen en 1x512x1x1 y luego se conectan a la capa completamente conectada para la salida, y el número de nodos de salida De acuerdo con el número de categorías predichas.
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)9. Características de la red.
Toda la ResNet no usa la deserción, todos usan BN. Además
- Inspirado por VGG, la capa convolucional es principalmente convolución 3 × 3;
- Para capas del mismo tamaño de mapa de características de salida, es decir, la misma etapa, con el mismo número de filtros 3x3;
- Si el tamaño del mapa de entidades se reduce a la mitad, el número de filtros se duplica para mantener la complejidad temporal de cada capa;
- Cada etapa realiza un muestreo descendente a través de una capa convolucional con un tamaño de paso de 2, pero este muestreo descendente solo se completará en la primera circunvolución de cada etapa, solo una vez.
- La red termina con una capa de agrupación promedio y la capa totalmente conectada de 1000 vías de softmax. En la práctica, la agrupación promedio global adaptativa generalmente se usa en ingeniería;
De la estructura de red en la figura, después de la convolución, hay una estructura de Agrupación promedio global (GAP) antes de la capa completamente conectada.
10. Resumido de la siguiente manera
- En comparación con la red de clasificación tradicional, aquí está conectado a la agrupación, en lugar de la capa totalmente conectada. La agrupación no requiere parámetros, en comparación con la capa totalmente conectada, se puede cortar una gran cantidad de parámetros. Para un mapa de características 7x7, la agrupación directa puede ahorrar casi 50 veces los parámetros en comparación con el cambio a una capa totalmente conectada. Tiene dos efectos: uno es ahorrar recursos informáticos y el otro es evitar el sobreajuste del modelo y mejorar la capacidad de generalización;
- Aquí se utiliza la agrupación promedio global. Los resultados experimentales de algunos documentos muestran que el efecto de la agrupación promedio es ligeramente mejor que el de la agrupación máxima, pero el efecto de la agrupación máxima no es mucho peor. ** En el proceso de uso real, puede hacer algunos ajustes de acuerdo con sus propias necesidades. Por ejemplo, el problema de clasificación múltiple es más adecuado para usar la agrupación máxima global.
