1. Mapa histórico de la evolución de la estructura CNN

El primer estudio clásico en papel de CNN, el creador de la red neuronal convolucional, el clásico documento de reconocimiento de escritura a mano LeNet: "Aprendizaje basado en gradientes aplicado al reconocimiento de documentos", el autor incluye a Yann Lecun, uno de los tres gigantes del aprendizaje profundo, el libro de flores " Yoshua Bengio, uno de los autores de Deep Learning.
La longitud del texto original es muy larga, elija registrar la parte más importante de los capítulos A y B que presentan la estructura de la red CNN.
2. Redes neuronales convolucionales para el reconocimiento de caracteres Las redes multicapa que
utilizan el método de descenso de gradiente pueden aprender un mapeo complejo, lineal y de alta latitud a partir de una gran cantidad de datos, lo que los convierte en la primera opción para las tareas de reconocimiento de imágenes. En el modelo tradicional de reconocimiento de patrones, un extractor de características diseñado manualmente extrae características relevantes de la imagen para eliminar información irrelevante. El clasificador puede clasificar estas características. Una red multicapa totalmente conectada se puede utilizar como clasificador. Un modo más interesante es tratar de confiar en el extractor de funciones para aprender. Para el reconocimiento de caracteres, la imagen se puede ingresar a la red como un vector de línea como entrada. Aunque estas tareas (como el reconocimiento de caracteres) pueden completarse utilizando una red tradicional de conexión directa hacia adelante. Pero todavía hay algunos problemas.
Primero, la imagen es muy grande y consta de muchos píxeles. Una red totalmente conectada con 100 unidades ocultas contiene decenas de miles de pesos, por lo que muchos parámetros aumentan el consumo del sistema y la huella de memoria, por lo que se requiere un conjunto de entrenamiento más grande. Pero la principal desventaja de una red no estructurada es que no tiene la invariancia de la traducción, la deformación y la distorsión para otras aplicaciones que no sean imagen o audio. En la entrada de dinero de la red a una entrada de tamaño fijo, el tamaño de la imagen del personaje debe normalizarse y colocarse en el medio de la entrada. Desafortunadamente, ningún preprocesamiento puede ser tan perfecto: dado que la escritura a mano usa caracteres como la unidad normalizada, Causará cambios en el tamaño, la inclinación y la posición de cada carácter, además de las diferencias en los estilos de escritura, conducirá a cambios en las posiciones de las características. En principio, una red completamente conectada de tamaño suficiente puede ser robusta para estos cambios, pero para lograr Este propósito requiere más neuronas en diferentes posiciones de la imagen de entrada, de modo que se puedan detectar diferentes características, sin importar dónde aparezcan en la imagen. Aprender estos parámetros de peso requiere una gran cantidad de muestras de entrenamiento para cubrir el posible espacio muestral. En la red neuronal convolucional que se describe a continuación, la invariancia de turno se puede lograr compartiendo el peso.
Punto 2, otra desventaja de una red totalmente conectada es que ignora por completo la topología de entrada. Las imágenes de entrada pueden estar en cualquier orden sin afectar los resultados del entrenamiento. Sin embargo, la imagen tiene una estructura local bidimensional fuerte: los píxeles espacialmente adyacentes están altamente correlacionados. La correlación local tiene una gran ventaja para extraer características locales, porque los pesos de los píxeles adyacentes se pueden dividir en varias categorías. CNN extrae características al restringir el campo receptivo de nodos ocultos a local.
Una red de convolución
CNN por campo receptivo local (receptivo campos local) , los pesos compartidos (pesos compartidos) , muestreo descendente (submuestreo) invariancia lograr el desplazamiento, escalado, y la deformación (desplazamiento, escala, distorsión invariancia) . Una estructura de red típica utilizada para el reconocimiento de caracteres se muestra en la Figura 2, que se llama LeNet-5. La capa de entrada tiene una imagen de caracteres cuyo tamaño está normalizado y los caracteres se encuentran en el medio. Cada neurona en cada capa (cada unidad) recibe la entrada de un grupo de neuronas en el campo local en la capa anterior (es decir, el campo receptivo local). La idea de conectar múltiples neuronas en campos receptivos locales se remonta al perceptrón de la década de 1960, que está casi sincronizada con las neuronas de la selección local receptiva y de dirección descubiertas por Hubel y Wiesel en el sistema visual del gato (red neuronal y neuronal La ciencia está estrechamente relacionada). Los campos receptivos parciales se utilizan muchas veces en modelos neuronales de aprendizaje visual. Mediante el uso de campos receptivos locales, las neuronas pueden extraer características visuales como bordes y esquinas. Estas características se combinan en la siguiente capa para formar características de nivel superior. Como se mencionó anteriormente, la deformación Y el desplazamiento provocará el cambio de la posición destacada de la característica. Además, el detector de características locales de la imagen también se puede utilizar para toda la imagen. Con base en esta característica, podemos establecer un grupo de neuronas con campos receptivos locales en diferentes posiciones de la imagen con el mismo peso ( Esto es compartir peso).Todas las neuronas en cada capa forman un plano, y todas las neuronas en este plano comparten pesos. Todas las salidas de la neurona (unidad) constituyen un mapa de características. Todas las unidades en el mapa de funciones realizan la misma operación en diferentes posiciones de la imagen, para que puedan detectar la misma característica en diferentes posiciones de la imagen de entrada. Una capa convolucional completa consta de múltiples Un mapa de características (usando diferentes vectores de peso), de modo que cada ubicación pueda extraer una variedad de características. Un ejemplo específico es la primera capa en la Figura 2 LeNet-5. Todas las celdas en la primera capa oculta forman 6 planos, cada uno de los cuales es un mapa de características. Una celda en un mapa de características corresponde a 25 entradas. Estas 25 entradas están conectadas al área 5x5 de la capa de entrada. Esta área es el campo receptivo local. Cada unidad tiene 25 entradas, por lo que hay 25 parámetros entrenables más un desplazamiento. Dado que las unidades adyacentes en el mapa de entidades se centran en unidades consecutivas en la capa anterior, los campos receptivos locales de las unidades adyacentes se superponen. Por ejemplo, en LeNet-5, los campos receptivos de unidades continuas horizontalmente se superponen con 5 filas y 4 columnas. Como se mencionó anteriormente, todas las unidades en un mapa de características comparten 25 pesos y un desplazamiento, por lo que son La misma característica se detecta en diferentes ubicaciones, y los otros mapas de características de cada capa usan diferentes conjuntos de pesos y compensaciones para extraer diferentes tipos de características locales. En LeNet, se extraen 6 características diferentes para cada ubicación de entrada. Una forma de realizar el mapa de características es usar una unidad con un campo receptivo para escanear la imagen completa y mantener el estado de cada posición correspondiente en el mapa de características. Esta operación es equivalente a la convolución, seguido de la adición de un parcial Configurar y una función, por lo tanto, llamada la red convolucional, el núcleo de convolución es el peso de la conexión. El núcleo de la capa convolucional es un conjunto de pesos de conexión utilizados por todas las unidades en el mapa de características. Una característica importante de la capa convolucional es que si la imagen de entrada se desplaza, el mapa de características se desplazará correspondientemente; de lo contrario, el mapa de características permanece sin cambios. Esta característica es la base para que CNN mantenga la robustez contra el desplazamiento y la deformación.
Una vez que se calcula el mapa de características, la ubicación precisa deja de ser importante y la ubicación aproximada en relación con otras características es relevante. Por ejemplo, sabemos que el área superior izquierda tiene un punto final de un segmento de línea horizontal, la esquina superior derecha tiene una esquina y el segmento de línea vertical inferior tiene un punto final. Sabemos que el número es 7. La ubicación precisa de estas características no solo no ayuda al reconocimiento, sino que no es propicio para el reconocimiento, porque para diferentes caracteres escritos a mano, la ubicación a menudo cambiará. La forma de reducir la precisión de la posición de la característica en el mapa de características es reducir la resolución espacial del mapa de características. Esto se puede lograr mediante la capa de disminución de muestreo. La capa de disminución de resolución reduce la resolución del mapa de características tomando el promedio local y reduce la traducción de salida y la deformación. Sensibilidad La segunda capa oculta en LeNet-5 es la capa de disminución de resolución. Esta capa contiene 6 mapas de características, correspondientes a los 6 mapas de características de la capa anterior. El campo receptivo de cada neurona es 2x2. Cada neurona calcula el promedio de las cuatro entradas, luego lo multiplica por un coeficiente, y finalmente agrega una paranoia, y finalmente pasa el valor a una función sigmoidea. Los campos receptivos de las neuronas adyacentes no se superponen. Por lo tanto, las filas y columnas del mapa de características de la capa de muestreo descendente son la mitad del mapa de características de la capa anterior. Los coeficientes y las compensaciones afectan el efecto de la función sigmoidea. Si el coeficiente es relativamente pequeño, la capa de disminución de resolución es equivalente a difuminar la entrada. Si el coeficiente es grande, la capa de disminución de resolución se puede considerar como una operación "o" o "y" de acuerdo con el valor de compensación. La capa convolucional y la capa de disminución de resolución aparecen alternativamente.Esta forma forma una pirámide: para cada capa, la resolución del mapa de entidades disminuye gradualmente y el número de mapas de entidades aumenta gradualmente. La entrada de cada neurona de la tercera capa oculta (capa C3) en LeNet-5 puede provenir de múltiples mapas de características de la capa anterior (S2). La inspiración para la combinación de convolución y reducción de muestras proviene del concepto de Hubel y Wiesel de células "simples" y "complejas", aunque en ese momento no había un proceso de aprendizaje supervisado global como la propagación hacia atrás. La disminución de resolución y la combinación de múltiples características pueden mejorar enormemente la invariabilidad de la red a la transformación geométrica.
Como todos los pesos se aprenden a través de la propagación hacia atrás, la red convolucional se puede considerar como un extractor de características. La tecnología de peso compartido tiene un impacto importante en la reducción del número de parámetros, mientras que la tecnología de peso compartido reduce la brecha entre el error de prueba y el error de entrenamiento. LeNet-5 contiene 340,908 conexiones, pero debido al peso compartido solo se incluyen 60,000 parámetros entrenables. Las redes neuronales convolucionales se utilizan en muchos campos, incluido el reconocimiento de escritura a mano, el reconocimiento de caracteres impresos, el reconocimiento de escritura a mano en línea y el reconocimiento facial. Las redes neuronales convolucionales con pesos compartidos en una sola dimensión de tiempo se denominan redes neuronales de retardo (TDNN). Las TDNN se han utilizado en el reconocimiento de escenas (sin disminución de resolución) [40], reconocimiento de voz (sin disminución de resolución), independiente Reconocimiento de caracteres escritos a mano [44] y verificación de gestos [45].
B LeNet-5
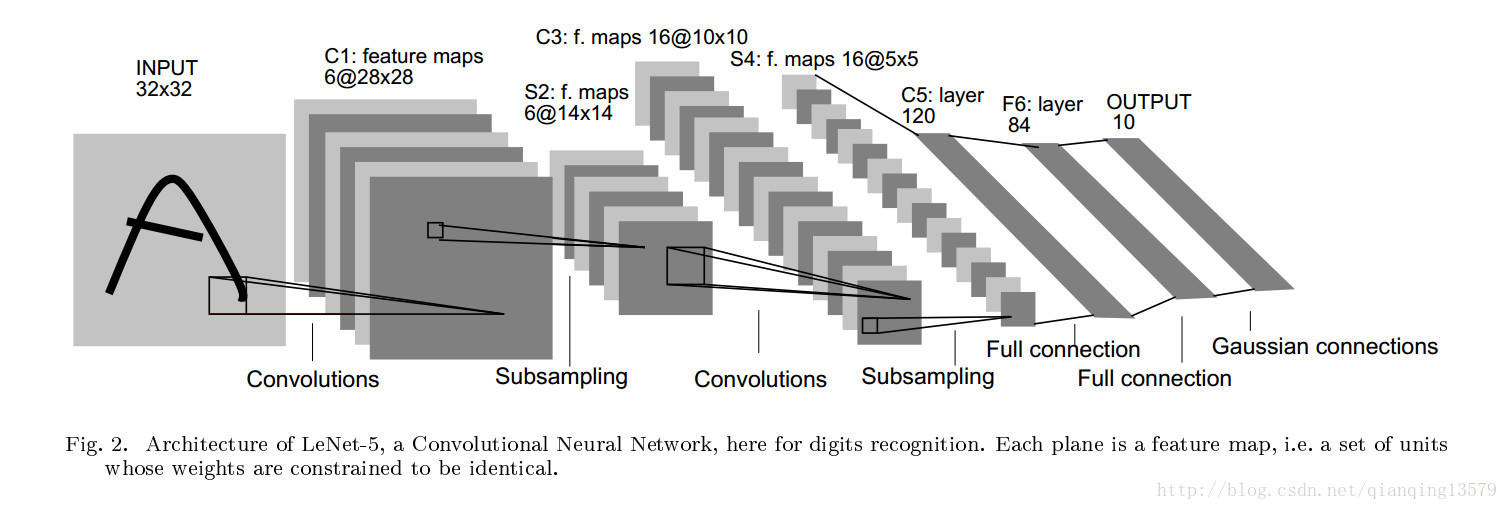
LeNet-5 tiene un total de 7 capas y no incluye entradas, cada capa contiene parámetros entrenables (pesos de conexión). La imagen de entrada tiene un tamaño de 32 * 32. Esto es más grande que la letra más grande en la base de datos Mnist (una base de datos de escritura a mano reconocida) (28 * 28). La razón de esto es esperar que las características potencialmente obvias, como los puntos finales de trazo o los puntos de esquina, puedan aparecer en el centro del campo receptivo del monitor de características de nivel más alto. En LeNet-5, el centro del campo receptivo de la última capa convolucional forma un área de 20x20 en la imagen de entrada de 32x32. Los valores de los píxeles de entrada se normalizan para que el fondo (blanco) corresponda a -0.1 y el primer plano ( Negro) corresponde a 1.175. Esto hace que la media de la entrada sea aproximadamente igual a 0 y la varianza aproximadamente igual a 1, lo que puede acelerar el aprendizaje [46].
A continuación, la capa convolucional se identifica como Cx, la capa de muestreo descendente se identifica como Sx, la capa completamente conectada se identifica como Fx y el índice de la capa de identificación x.
C1层是一个卷积层,由6个特征图Feature Map构成。特征图中每个神经元与输入中5*5的邻域相连。特征图的大小为28*28,这样能防止输入的连接掉到边界之外。C1有156个可训练参数(每个滤波器5*5=25个unit参数和一个bias参数,一共6个滤波器,共(5*5+1)*6=156个参数),共122,304个连接(26*28*28*6,每个神经元对应26个连接,每个feature map有28*28个unit, 一共有6个feature map)。(25个输入和1个偏置共26个连接,得到输出特征图里一个像素。)
S2层是一个下采样层,有6个14*14的特征图。特征图中的每个单元与C1中相对应特征图的2*2邻域相连接。S2层每个单元的4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid函数计算。可训练系数和偏置控制着sigmoid函数的非线性程度。如果系数比较小,那么运算近似于线性运算,下采样相当于模糊图像。如果系数比较大,根据偏置的大小下采样可以被看成是有噪声的“或”运算或者有噪声的“与”运算。每个单元的2*2感受野并不重叠,因此S2中每个特征图的行列分别是C1中特征图的一半。S2层有12个(池化层没有要学习的参数)可训练参数(每个feature map有一个系数和偏置)和5880(5*14*14*6)个连接。
C3是一个有16个特征图的卷积层。C3层的卷积核大小为5*5,每个特征图中的每个单元与S2中的多个特征图相连,表1显示了C3中每个特征图与S2中哪些特征图相连。
那为什么不把S2中的每个特征图连接到每个C3的特征图呢?原因有2点。
第一,不完全的连接机制将连接的数量保持在合理的范围内。
第二,也是更加重要的,其破坏了网络的对称性。不完全连接能够保证C3中不同特征图提取不同的特征(希望是互补的),因为他们的输入不同。
表1中展示了一个合理的连接方式:C3的前6个特征图以S2中3个相邻的特征图为输入。接下来6个特征图以S2中4个相邻特征图为输入,下面的3个特征图以不相邻的4个特征图为输入。最后一个特征图以S2中所有特征图为输入。这样C3层有1516个可训练参数((25*3+1)*6+(25*4+1)*9+(25*6+1))和151600个(C3层特征图大小10*10)连接。
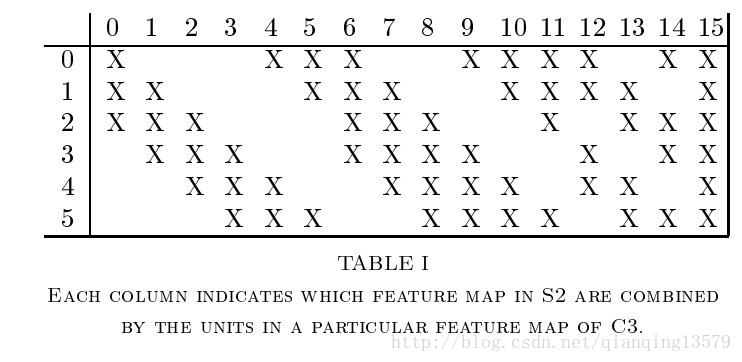
(表1中第1列表示C3的第0个特征图,与S2中的第0,1,2个特征图连接)
S4层是一个下采样层,由16个5*5大小的特征图构成。特征图中的每个单元与C3中相应特征图的2*2邻域相连接,跟C1和S2之间的连接一样。S4层有32个可训练参数(每个特征图1个系数和一个偏置)和2000个连接(5*5*5*16,对于S4的每个unit,对应感受野4个参数,加上一个偏置)。
C5层是一个卷积层,有120个特征图。每个单元与S4层的全部16个特征图的5*5领域相连。由于S4层特征图的大小也为5*5(同滤波器一样),故C5特征图的大小为1*1:这构成了S4和C5之间的全连接。之所以仍将C5标示为卷积层而非全连接层,是因为如果LeNet-5的输入变大,而其他的保持不变,那么此时特征图的维数就会比1*1大。C5层有48120个可训练连接((5*5*16+1)*120)。
F6层有84个单元(之所以选这个数字的原因来自于输出层的设计,下面会有说明),与C5层全相连。有10164个可训练参数。
如同经典神经网络,F6层计算输入向量和权重向量之间的点积,再加上一个偏置。神经元i的加权和表示为aiai,然后将其传递给sigmoid函数产生单元i的一个状态,表示为xi,
xi=f(ai)
Sigmoid函数是一个双曲线正切函数:
f(a)=Atanh(Sa)
A表示函数的振幅,S决定了斜率,这个函数是一个奇函数,水平渐近线为+A,-A。常量A通常取1.7159。选择该函数的原因见附录A。
最后,输出层(其实就是softmax loss)由欧式径向基函数(Euclidean Radial Basis Function,RBF)单元组成,每类一个单元,每个单元有84个输入,每个RBF单元yiyi的输出按照如下方式计算:
yi=∑(xj−ωij)2
yi=∑(xj−ωij)2
换句话说,每个输出RBF单元计算输入向量和参数向量之间的欧式距离。输入离参数向量越远,RBF输出的越大。一个RBF输出可以被理解为衡量输入模式和与RBF相关联类的一个模型的匹配程度的惩罚项。用概率术语来说,RBF输出可以被理解为F6层配置空间的高斯分布的负的log似然(log-likelihood)。给定一个输入模式,损失函数应能使得F6的配置与RBF参数向量(即模式的期望分类)足够接近。这些单元的参数是人工选取并保持固定的(至少初始时候如此)。这些参数向量的成分被设为-1或1。虽然这些参数可以以-1和1等概率的方式任选,或者构成一个纠错码,但是被设计成一个相应字符类的7*12大小(即84)的格式化图片。这种表示对识别单独的数字不是很有用,但是对识别可打印ASCII集中的字符串很有用。基本原理就是字符是相似的,容易混淆,比如大小的O,小写的o和数字0或者小写的l与数字1,方括号和大写的I,会有相似的输出编码。如果一个系统与一个能够纠正此混淆的语言处理器相结合,这个就非常有用了。由于容易混淆的类别的编码是相似的,有歧义的字符的RBF输出是相似的,这个语言处理器就能够选择出合适的解释。图3给出了所有ASCII字符集的输出编码。

使用这种分布编码而非更常用的“1 of N”编码(又叫位置编码或者细胞编码)用于产生输出的另一个原因是,当类别比较大的时候,非分布编码的效果比较差。原因是大多数时间非分布编码的输出必须是关闭状态。这使得用sigmoid单元很难实现。另一个原因是分类器不仅用于识别字母,也用于拒绝非字母。使用分布编码的RBF更适合该目的,因为与sigmoid不同,他们在输入空间的较好得限制区域内兴奋,而非典型模式更容易落到外边。
RBF参数向量起着F6层目标向量的角色。需要指出这些向量的成分是+1或-1,这正好在F6 sigmoid的范围内,因此可以防止sigmoid函数饱和。实际上,+1和-1是sigmoid函数的最大曲率的点。这使得F6单元运行在最大非线性范围内。必须避免sigmoid函数的饱和,因为这将会导致损失函数较慢的收敛和病态问题。
3、重要的点
神经元是一个包含完整输入和输出完整过程的计算模型。
一个神经元对应一组权值(卷积神经网络中的卷积核+偏置,全连接网络中的权重w和偏置),执行一次计算 (CNN中的卷积计算,全连接网络中的权重计算),产生一个输出(CNN中特征图的一个像素,全连接网络中的下一层的一个神经元)的过程。
————————————————
转载,原文链接:https://blog.csdn.net/qianqing13579/article/details/71076261