Séptima semana
Objetivos de aprendizaje
Descripción del punto de conocimiento: regresión logística-algoritmo de clasificación binaria ampliamente utilizada
Objetivos de aprendizaje:
-
La esencia de la regresión logística y su derivación matemática.
-
Implementación de código de regresión logística y llamadas
-
Límites de decisión, polinomios y regularización en regresión logística.
1. Regresión logística
1. Introducción
1.1 ¿Puede la regresión lineal resolver el problema de clasificación?
De hecho, la regresión lineal no puede resolver el problema de clasificación. Porque cuando usamos el modelo de regresión lineal, en realidad hicimos 3 supuestos (de hecho, hay más supuestos, aquí solo se analizan los tres más básicos):
- Existe una correlación lineal entre variables dependientes e independientes .
- La variable independiente y el término de interferencia son independientes entre sí.
- Los factores aleatorios no capturados por el modelo lineal siguen una distribución normal.
En teoría, cualquier dato colocado en cualquier modelo obtendrá las estimaciones de los parámetros correspondientes y luego pronosticará los datos a través del modelo. Sin embargo, esto no garantiza necesariamente el efecto del modelo, y a veces se obtiene un modelo "incorrecto e inútil", por lo que es necesario presentar constantemente hipótesis y probar hipótesis durante el proceso de modelado.
1.2 Uso de la regresión logística para resolver problemas de clasificación: esencialmente una solución de clasificación binaria
2. Derivación de algoritmo
(Tres clasificaciones binarias en la medición: regresión logit, regresión probit, regresión de probabilidad lineal)
Para un problema de clasificación, debido a la "utilidad de ventana", solo podemos ver el comportamiento de compra del cliente, pero detrás de la clasificación está el juego entre variables ocultas. Construimos el modelo de variables ocultas para encontrar la probabilidad de compra del cliente .
La regresión probit es matemáticamente perfecta, pero la función de distribución acumulativa de la distribución normal es muy complicada y no tiene expresión analítica, por lo que es difícil estimar los parámetros directamente en la regresión probit. Afortunadamente, podemos aproximarlo

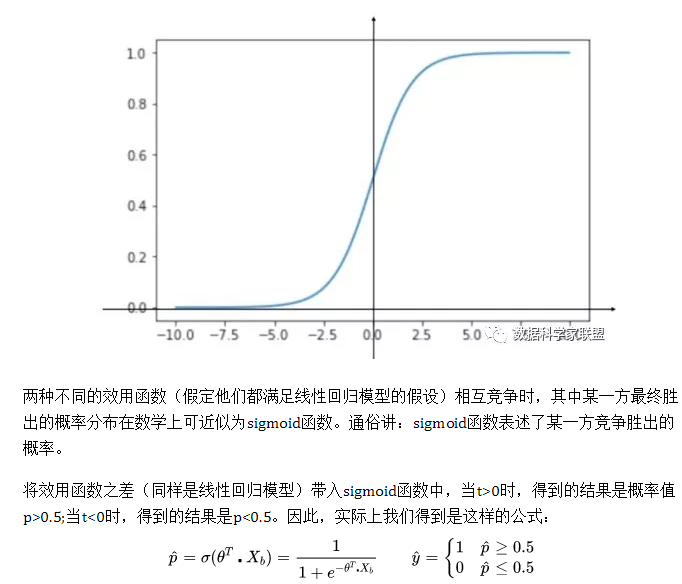
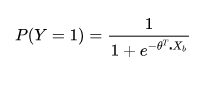
2. Regresión logística en términos de probabilidad logarítmica.
La regresión logística supone que los datos obedecen a la distribución de Bernoulli, y utiliza el descenso de gradiente para resolver los parámetros mediante el método de la función de máxima verosimilitud para lograr el propósito de clasificar los datos.

1.2 Preguntas de la entrevista
Después de la derivación anterior, mire otra pregunta de la entrevista:
¿Por qué usar la función sigmoidea como una suposición?
Ahora puedes responder:
Debido a que el valor predicho del modelo de regresión lineal es un número real, y la etiqueta de clase de la muestra es (0,1), necesitamos asociar la etiqueta verdadera y de la tarea de clasificación con el valor predicho del modelo de regresión lineal, es decir, encontrar la conexión en el modelo lineal generalizado Función . Si se elige la función de paso unitario, es discontinua y no es diferenciable. Si elige la función sigmoidea, es continua y puede convertir z a un valor cercano a 0 o 1.
Función de pérdida:
- Si la verdadera categoría y = 1 para una muestra dada, cuanto menor es la probabilidad estimada p, mayor es la función de pérdida (error estimado)
- Si la categoría verdadera y = 0 para una muestra dada, cuanto mayor es la probabilidad estimada p, mayor es la función de pérdida (error de estimación)

Implementación de tres códigos de regresión logística y llamada
Pasos para desmontar!
El contenido principal es:
- Defina el método sigmoide, use el método sigmoide para generar el modelo de regresión logística
- Defina la función de pérdida y utilice el método de descenso de gradiente para obtener los parámetros.
- Sustituya los parámetros en el modelo de regresión logística para obtener la probabilidad.
- Convertir probabilidad a clasificación
Cuatro límites de decisión en la clasificación
1.1 Límite de decisión
Significado literal

1.3 Límites de decisión lineales y no lineales
El llamado límite de decisión es un límite que puede clasificar correctamente las muestras. Existen principalmente límites de decisión lineales y límites de decisión no lineales.
Nota: El límite de decisión es el atributo de la función hipotética, determinada por los parámetros, no por las características del conjunto de datos.
2.1 Conversión de regresión lineal a regresión polinómica
Para linealidad, esta línea recta azul puede dividir perfectamente los datos en dos categorías. Pero el método de clasificación en línea recta es demasiado simple.

5. Regresión logística y regularización en sklearn
Agregue términos polinómicos a la regresión logística para obtener límites de decisión irregulares y luego clasifique bien los datos no lineales. Pero como todos sabemos, después de agregar términos polinómicos, el modelo se volverá muy complicado y es muy fácil de sobreajustar. Por lo tanto, es necesario usar la regularización, y la regresión logística en sklearn es usar la regularización.
