El problema
Cuando sea necesario, un intervalo debe asignarse a otro intervalo. Si 0-1 se asigna a 10-32, ¿cómo se debe diseñar el algoritmo?
Escena 1
Por ejemplo, un profesor universitario lleva a cabo un examen final bajo la probabilidad de suspender las materias prescritas por la escuela.Si todos los estudiantes aprueban mal el examen, entonces necesita ajustar las calificaciones de los estudiantes de acuerdo con la forma apropiada.
Por ejemplo, las calificaciones de los estudiantes son generalmente bajas, distribuidas entre 20 y 65 puntos, luego deben asignarse a entre 55 y 100 para aumentar la tasa de aprobación.
Escena 2
Un estudiante es un estudiante de intercambio en un país determinado, pero el puntaje en un país es 5-18, pero el puntaje en el país es 0-100. Es necesario reflejar el puntaje del examen extranjero en la transcripción nacional. También es para 5-18ser asignado a 0-100, le [5-18] -5 = [0, 13], se supone logro Bob es 12, por lo que es los logros nacionales 12*(100/13), el principio es 先归零,然后再同比例缩放.
Principio
Suponiendo que los datos a escalar son X y el rango a mapear es [a, b], entonces se puede usar la siguiente fórmula.
Código
def map_rate(X:list, to_min:float, to_max:float)->list:
"""区间映射
Attribute:
- X: 需要映射的列表
- to_min: 要映射到的最小值
- to_max: 要映射到的最大值
"""
x_min=min(X)
x_max=max(X)
return list([round(to_min+((to_max - to_min) / (x_max - x_min)) * i - x_min,1) for i in X])
Este código es relativamente simple, y los parámetros son los tres parámetros mencionados anteriormente: la lista a mapear, el inicio y el fin a mapear, y el resultado final se redondea (x, 2) un poco, mantenga un decimal, de lo contrario el resultado obtenido Demasiado preciso
Experimento
Por ejemplo, resultados de estudiantes generados aleatoriamente =, y luego asignarlos a un cierto rango.
X=[67, 45, 81, 95, 23, 77, 65, 32, 55, 22]
map_rate(X, 60, 100)
El resultado es
[74.7, 62.7, 82.4, 90.1, 50.6, 80.2, 73.6, 55.5, 68.1, 50.1]
Problema de distribución
Tengo un poco de curiosidad sobre si esto afectará su distribución, supongo que no lo hará, porque es la misma escala. Así que utilicé el conjunto de datos de los puntajes escolares de un estudiante de secundaria en Portugal, la URL es: https://www.mldata.io/dataset-details/school_grades/#customize_download
Usando el método anterior, se verificó la distribución de los resultados matemáticos.
data1=pd.read_csv("./学生成绩.csv",encoding='utf8')
with open("./result.csv",'w',encoding='utf8') as f:
result_list="\n".join([str(i) for i in map_rate(list(data1['G3']),60,100)])
f.writelines(result_list)
Los resultados se muestran en la figura.
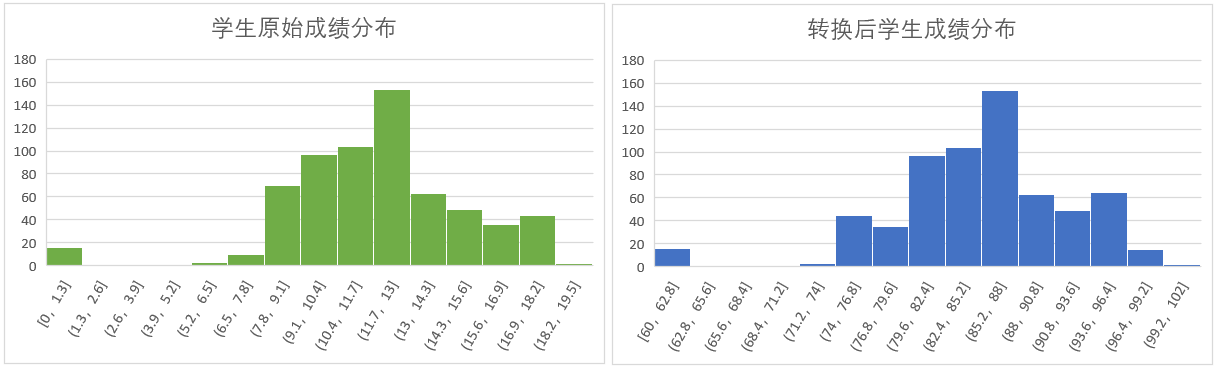
Se puede ver que básicamente no hay cambios, pero habrá algunos cambios, que son causados por el diferente binning de la distribución.