1. Introducción a XPath
Para analizar la relación jerárquica de las páginas web, la función de selección de XPath es muy poderosa, proporciona una expresión de selección de ruta muy simple y clara.
Además, también proporciona más de 100 funciones integradas para la coincidencia de cadenas, números y tiempos, así como el procesamiento de nodos y secuencias.
Casi todos los nodos de posicionamiento se pueden seleccionar usando XPath.
Sitio web oficial: https://www.w3.org/TR/xpath
1. Reglas comunes de XPath:
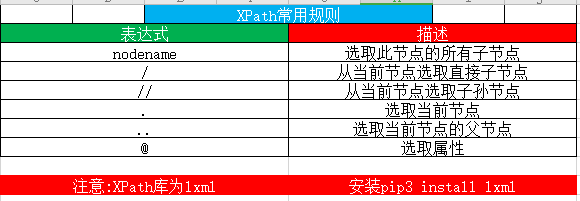
2. Uso básico
from lxml import etree text = '' ' <div> <ul> <li class = "one"> <a href="link1"> 1 </a> </li> <li class = "two"> <a href = "link2"> 2 </a> </li> <li class = "three"> <a href="link3"> 3 </a> </li> <li class = "four"> <a href = "link4"> 4 </a> </li> <li class = "five"> <a href="link5"> 5 </a> </ul> </div> '' ' # 将 文本转换 为 网页 类型 , 并 修复 补 全 html = etree.El HTML (texto) # todo el complemento de la estructura de la página web, el archivo de trazado abierto # HTML etree.parse = ( 'demo.html', etree.HTMLParser ()) Imprimir (HTML) # convertir la página en el tipo de texto, como bytes = Resultado etree.tostring (HTML) # en str Tipo Resultado = result.decode ( " UTF-8. " ) Imprimir (Resultado)
1. Selección de coincidencias (todos los nodos)
from lxml import etree text = '' ' <div> <ul> <li class = "one"> <a href="link1"> 1 </a> </li> <li class = "two"> <a href = "link2"> 2 </a> </li> <li class = "three"> <a href="link3"> 3 </a> </li> <li class = "four"> <a href = "link4"> 4 </a> </li> <li class = "five"> <a href="link5"> 5 </a> </ul> </div> '' ' # 将 文本转换 为 网页 类型 , 并 修复 补 全 html = etree.El HTML (texto) # seleccionada coincidencia de contenidos Resultado = html.xpath ( ' // * ' ) Imprimir (Resultado)

2. Nodos hijos
from lxml import etree text = '' ' <div> <ul> <li class = "one"> <a href="link1"> 1 </a> </li> <li class = "two"> <a href = "link2"> 2 </a> </li> <li class = "three"> <a href="link3"> 3 </a> </li> <li class = "four"> <a href = "link4"> 4 </a> </li> <li class = "five"> <a href="link5"> 5 </a> </ul> </div> '' ' # 将 文本转换 为 网页 类型 , 并 修复 补 全 html = etree.El HTML (texto) # seleccionada coincidencia de contenidos Resultado = html.xpath ( ' // Li / A ' ) Imprimir (Resultado)
Aquí "/" representa nodos secundarios directos, "//" representa todos los nodos descendientes

3. nodo principal
Nodo padre: use " .. ", también puede usar parent :: para representar el padre
from lxml import etree text = '' ' <div> <ul> <li class = "one"> <a href="link1"> 1 </a> </li> <li class = "two"> <a href = "link2"> 2 </a> </li> <li class = "three"> <a href="link3"> 3 </a> </li> <li class = "four"> <a href = "link4"> 4 </a> </li> <li class = "five"> <a href="link5"> 5 </a> </ul> </div> '' ' # 将 文本转换 为 网页 类型 , 并 修复 补 全 html = etree.El HTML (texto) # contenido coincidente seleccionada # atributo es un identificador de atributo de la clase padre link4 Resultado = html.xpath ( ' //a[@href="link4"]/../@class ' ) #@ 表示 属性 resultado1 = html.xpath ( ' // a [@ href = "link4"] / parent :: * / @ class ' ) print (resultado) print (resultado1)

4. Adquisición de texto
from lxml import etree text = '' ' <div> <ul> <li class = "one"> <a href="link1"> 1 </a> </li> <li class = "two"> <a href = "link2"> 2 </a> </li> <li class = "three"> <a href="link3"> 3 </a> </li> <li class = "four"> <a href = "link4"> 4 </a> </li> <li class = "five"> <a href="link5"> 5 </a> </ul> </div> '' ' # 将 文本转换 为 网页 类型 , 并 修复 补 全 html = etree.El HTML (texto) # seleccionada contenido coincidente # atributo es una clase padre atributo de etiqueta link4 Resultado = html.xpath ( ' // a [@ el href = "link4"] / texto () ' ) Imprimir(resultado)

5. Atributo de coincidencia de valores múltiples
from lxml import etree text = '' ' <div> <ul> <li class = "one"> <a href="link1"> 1 </a> </li> <li class = "two"> <a href = "link2"> 2 </a> </li> <li class = "three two"> <a href="link3"> 3 </a> </li> <li class = "four"> < a href = "link4"> 4 </a> </li> <li class = "five"> <a href="link5"> 5 </a> </ul> </div> '' ' # 将文本 转换 为 网页 类型 , 并 修复 补 全 html = etree.El HTML (texto) # coincidencia de contenido seleccionado # la contiene (@ propiedad, valor) Resultado = html.xpath ( ' // Li [la contiene (@class, "Tres")] / A / texto () ' ) imprimir (resultado)
6. Coincidencia de atributos múltiples
Múltiples atributos determinan un nodo, entonces necesita hacer coincidir múltiples atributos
from lxml import etree text = '' ' <div> <ul> <li class = "one"> <a href="link1"> 1 </a> </li> <li class = "two three" name = "item"> <a href="link2"> 2 </a> </li> <li class = "three two"> <a href="link3"> 3 </a> </li> <li class = "cuatro"> <a href="link4"> 4 </a> </li> <li class = "five"> <a href="link5"> 5 </a> </ul> </ div > '' ' # Convierte el texto tipo de página, y fijar el complemento HTML = etree.HTML (texto) # seleccionada contenido coincidente # la contiene (@ propiedad, valor) Resultado = html.xpath ( ' // Li [la contiene (@class, "Tres ") y @ name =" item "] / a / text ()' ) imprimir (resultado)
7. Elija en orden
from lxml import etree text = '' ' <div> <ul> <li class = "one"> <a href="link1"> 1 </a> </li> <li class = "two three" name = "item"> <a href="link2"> 2 </a> </li> <li class = "three two"> <a href="link3"> 3 </a> </li> <li class = "cuatro"> <a href="link4"> 4 </a> </li> <li class = "five"> <a href="link5"> 5 </a> </ul> </ div > '' ' # Convierte el texto tipo de página, y fijar el complemento HTML = etree.HTML (texto) # seleccionado contenido coincidente # primer partido Li RESULT1 = html.xpath ( ' // Li [. 1] / A / texto () ' ) #Por último, una cuenta atrás 2 result2 = html.xpath ( ' // Li [Ultima () - 2] / A / texto () ' ) # última result3 = html.xpath ( ' // Li [Ultima ()] / A / texto () ' ) # . menos de 3 result4 = html.xpath ( ' // Li [posición () <3.] / a / texto () ' ) # funciones integradas 100, http: //www.w3school.com.cn/ xpath / xpath_functions.asp print (resultado1) print (resultado2) print (resultado3) print (resultado4)

8. Selección del eje del nodo
# Atributo de un atributo de clase padre etiqueta link4