Análisis de uso de la biblioteca BeautifulSoup
I. Introducción
BeautifulSoup es una biblioteca de análisis de documentos html, que es muy útil cuando los rastreadores analizan datos. A continuación, documente su uso.
2. Preparación
importar biblioteca
- de bs4 importar BeautifulSoup
Crear un objeto beautifulSoup
- A través del archivo, cree un objeto beautifulSoup
file = open("./Test.html",encoding="utf-8")
soup = BeautifulSoup(file,"html.parser")
- A través del contenido de texto, cree un objeto BeautifulSoup
content = '''
<!DOCTYPE html>
<html>
<head>
<meta content="text/html;charset=utf-8" http-equiv="content-type" />
<meta content="IE=Edge" http-equiv="X-UA-Compatible" />
<meta content="always" name="referrer" />
<link href="https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css" rel="stylesheet" type="text/css" />
<title attr1="val1" attr2="val2">百度一下,你就知道 </title>
<ha attr1="val1" attr2="val2"><!--我是注释里的内容--></ha>
</head>
<body link="#0000cc">
<div id="wrapper">
<div id="head">
<div class="head_wrapper">
<div id="u1">
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻 </a>
<a class="mnav" href="https://www.hao123.com" name="tj_trhao123">hao123 </a>
<a class="mnav" href="http://map.baidu.com" name="tj_trmap">地图 </a>
<a class="mnav" href="http://v.baidu.com" name="tj_trvideo">视频 </a>
<a class="mnav" href="http://tieba.baidu.com" name="tj_trtieba">贴吧 </a>
<a class="bri" href="//www.baidu.com/more/" name="tj_briicon" style="display: block;">更多产品 </a>
</div>
</div>
</div>
</div>
</body>
</html>
'''
soup = BeautifulSoup(content,"html.parser")
Esto se usa más comúnmente, pero en el uso real, el contenido será reemplazado por el contenido de texto capturado en tiempo real por la página web.
A continuación, usaremos el texto anterior como fuente de datos para ilustrar, y todos los métodos siguientes se basan en el análisis de este texto.
3. Tipo
- HermosaSopa
- Etiqueta
- cadena navegable
- Comentario
HermosoTipo de sopa
El objeto de sopa que acabamos de crear es del tipo BeautifulSoup. puede imprimirlo
print(type(soup))
输出:<class 'bs4.BeautifulSoup'>
Tipo de etiqueta
El tipo de etiqueta es un tipo muy importante, entonces, ¿qué es Tag? Es similar a una etiqueta en xml, como se muestra en la figura a continuación.
<div id="u1"> <!-- 这是一个Tag-->
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻 </a> <!--这也是一个Tag-->
<a class="mnav" href="https://www.hao123.com" name="tj_trhao123">hao123 </a> <!--俺也一样-->
</div>
La etiqueta se puede dividir en tres partes: nombre, atributos y cadena. La estructura se muestra en la figura.
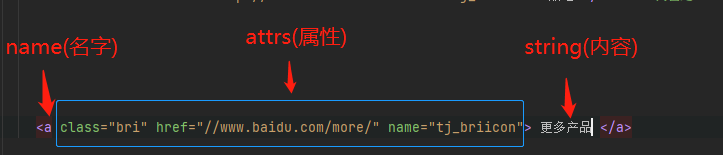
#获得找到的第一个名字为a的标签
print(soup.a)
#结果: <a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻 </a>
#打印名字
print(soup.a.name)
#结果:a
#打印属性
print(soup.a.attrs)
#结果:{'class': ['mnav'], 'href': 'http://news.baidu.com', 'name': 'tj_trnews'}
#打印内容
print(soup.a.string)
#结果:新闻
Tipos NavigableString y Comment
Estos dos son en realidad el contenido de la cadena de Tag. La diferencia es que si el contenido está completamente comentado, es del tipo Comentario; de lo contrario, es del tipo NavigableString
<title attr1="val1" attr2="val2">百度一下,你就知道 </title> <!--这里的string是NavigableString类型-->
<ha attr1="val1" attr2="val2"><!--我是注释里的内容--></ha> <!--这里的string是Comment类型-->
print(type(soup.title.string))
#结果:<class 'bs4.element.NavigableString'>
print(type(soup.ha.string))
#结果:<class 'bs4.element.Comment'>
print(soup.title.string)
#结果:百度一下,你就知道
print(soup.ha.string)
#结果:我是注释里的内容
#注意上面这里直接获得了注释里的内容
Cuatro, transversal
Podemos obtener la etiqueta por su nombre.
- Por ejemplo, de acuerdo con el contenido html anterior, podemos obtener una etiqueta como esta
- cabeza de sopa conseguir cabeza
- Soup.head.title obtiene la etiqueta
, pero si desea atravesar, debe usar otros métodos. A continuación, veamos cómo
atravesar nodos secundarios inmediatos
contenido
- Usar contenido para devolver nodos secundarios directos, tipo de lista
for item in soup.head.contents:
print(item.name)
'''
结果:
None
meta
None
meta
None
meta
None
link
None
title
None
ha
None
'''
Puede ver que todas las subetiquetas están impresas (habrá algunos nodos ninguno en ellas)
niños
- Use niños para devolver nodos secundarios directos, el tipo de iterador de listiterator
es similar a los contenidos, pero el tipo de devolución es diferente
iterar sobre todos los nodos secundarios
descendientes
Los nodos secundarios directos obtenidos por el contenido anterior y los secundarios no pueden obtener nodos secundarios. Y los descendientes pueden obtener todos los nodos secundarios
for item in soup.body.descendants:
print(item.name)
atravesar el nodo padre
- padre obtiene el nodo padre
- los padres obtienen todos los nodos principales
atravesar nodos hermanos
-
next_sibling siguiente nodo hermano
-
next_siblings Todos los nodos hermanos debajo de ti
-
anterior_hermano anterior nodo hermano
-
previous_siblings Nodos hermanos encima de ellos mismos
recorrido hacia adelante y hacia atrás
A diferencia del recorrido de los nodos hermanos, el recorrido hacia adelante y hacia atrás aquí puede llegar a los nodos secundarios. Atravesar hacia atrás desde el nodo raíz puede llegar a todos los nodos.
- siguiente_elemento siguiente nodo
- next_elements todos los nodos debajo de sí mismo
- elemento_anterior nodo anterior
- anterior_elementos todos los nodos por encima de sí mismo
5. Buscar
encuentra todos()
- Especificar búsqueda por palabra clave
especificar nombre
#查找 name=“a” 的所有标签
alla = soup.find_all(name="a")
for a in alla:
print(a)
resultado
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻 </a>
<a class="mnav" href="https://www.hao123.com" name="tj_trhao123">hao123 </a>
<a class="mnav" href="http://map.baidu.com" name="tj_trmap">地图 </a>
<a class="mnav" href="http://v.baidu.com" name="tj_trvideo">视频 </a>
<a class="mnav" href="http://tieba.baidu.com" name="tj_trtieba">贴吧 </a>
<a class="bri" href="//www.baidu.com/more/" name="tj_briicon"> 更多产品 </a>
Lo anterior también se puede escribir como sopa.find_all("a"), si no se especifica ninguna palabra clave, el valor predeterminado es el nombre como condición
Especificar texto
allItem = soup.find_all(text="新闻 ")
for item in allItem:
print(item)
resultado
新闻
Tenga en cuenta que todo lo que se encuentra aquí son cadenas, no etiquetas.
especificar atributos
Además de palabras clave como nombre, texto y atributos, otras representan atributos. Por ejemplo
allItem = soup.find_all(href="//www.baidu.com/more/")
for item in allItem:
print(item)
resultado
<a class="bri" href="//www.baidu.com/more/" name="tj_briicon"> 更多产品 </a>
Si el atributo coincide con la palabra clave de python, como clase, debe agregar un guión bajo _, como
allItem = soup.find_all(class_="mnav")
for item in allItem:
print(item)
resultado
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻 </a>
<a class="mnav" href="https://www.hao123.com" name="tj_trhao123">hao123 </a>
<a class="mnav" href="http://map.baidu.com" name="tj_trmap">地图 </a>
<a class="mnav" href="http://v.baidu.com" name="tj_trvideo">视频 </a>
<a class="mnav" href="http://tieba.baidu.com" name="tj_trtieba">贴吧 </a>
Se pueden agregar varias condiciones, como
allItem = soup.find_all(class_="mnav",href="http://news.baidu.com",name="a")
for item in allItem:
print(item)
resultado
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻 </a>
lista especificada
list = {
"mnav","bri"}
allItem = soup.find_all(class_=list)
for item in allItem:
print(item)
resultado
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻 </a>
<a class="mnav" href="https://www.hao123.com" name="tj_trhao123">hao123 </a>
<a class="mnav" href="http://map.baidu.com" name="tj_trmap">地图 </a>
<a class="mnav" href="http://v.baidu.com" name="tj_trvideo">视频 </a>
<a class="mnav" href="http://tieba.baidu.com" name="tj_trtieba">贴吧 </a>
<a class="bri" href="//www.baidu.com/more/" name="tj_briicon"> 更多产品 </a>
Especificar una expresión regular
allItem = soup.find_all(href =re.compile("www."))
for item in allItem:
print(item)
resultado
<link href="https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css" rel="stylesheet" type="text/css"/>
<a class="mnav" href="https://www.hao123.com" name="tj_trhao123">hao123 </a>
<a class="bri" href="//www.baidu.com/more/" name="tj_briicon"> 更多产品 </a>
método especificado
Especifique un método, puede pasar un método como parámetro, pero este método necesita tomar Tag como parámetro. Por ejemplo:
def has_attr_name(tag):
return tag.has_attr('name')
allItem = soup.find_all(has_attr_name)
for item in allItem:
print(item)
resultado
<meta content="always" name="referrer"/>
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻 </a>
<a class="mnav" href="https://www.hao123.com" name="tj_trhao123">hao123 </a>
<a class="mnav" href="http://map.baidu.com" name="tj_trmap">地图 </a>
<a class="mnav" href="http://v.baidu.com" name="tj_trvideo">视频 </a>
<a class="mnav" href="http://tieba.baidu.com" name="tj_trtieba">贴吧 </a>
<a class="bri" href="//www.baidu.com/more/" name="tj_briicon"> 更多产品 </a>
buscar()
BeautifulSoup también puede usar search() para buscar, pero como recién comencé a usar BeautifulSoup, generalmente uso find_all() para completar la búsqueda. No estoy familiarizado con esto. No lo escribiré...