**hadoop搭建集群**1. Apague el cortafuegos
1) Verifique el estado del
cortafuegos firewall-cmd - estado
2) Detenga el cortafuegos
systemctl stop firewalld.service
3) Desactive el cortafuegos para iniciar
systemctl deshabilite firewalld.service
2.
Entrada de línea de comando de sincronización de hora : yum install ntp Descargue el complemento ntp
Una vez completada la descarga, ingrese la línea de comando: ntpdate -u ntp1.aliyun.com
y luego ingrese la línea de comando: fecha
Si aparecen las siguientes condiciones, la configuración es exitosa: 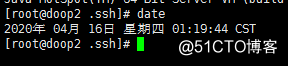
3. Configure el servidor (aquí tomo 4 como ejemplo)
1 nodo maestro: doop1 ( 192.168.0.103), 2 nodos secundarios (esclavos), doop2 (192.168.0.104), doop3 (192.168.0.105), doop4 (192.168.0.106)
2. Configure el nombre del nodo maestro (192.168.0.103)
en la línea de comando e ingrese: vi / etc / sysconfig / network
add content:
NETWORKING = yes
HOSTNAME = doop1
configura tres nombres de nodo secundario (192.168.0.104), (192.168.0.105), (192.168.0.106):
vi / etc / sysconfig / network
add content:
NETWORKING = si
HOSTNAME = doop2
vi / etc / sysconfig / network
add content:
NETWORKING = yes
HOSTNAME = doop3
vi / etc / sysconfig / network
add content:
NETWORKING = yes
HOSTNAME = doop4
4. Configure hosts para
abrir el archivo hosts del nodo maestro Comente dos líneas (comente la información del host actual) y agregue toda la información del host del clúster hadoop en el archivo.
Ingrese en la línea de comando: vi / etc / hosts
agregue la información de nombre de nodo de 3 servidores
192.168.0.103 doop1
192.168.0.104 doop2
192.168.0.105 doop3
192.168.0.106 doop4
guardar, copie los hosts del nodo maestro a los otros dos
comandos de subnodos Ingrese las siguientes líneas:
scp / etc / hosts [email protected]: / etc /
scp / etc / hosts [email protected]: / etc /
scp / etc / hosts [email protected]: / etc /
y luego ejecute ( (Reinicie el servidor sin ejecutar la siguiente instrucción): / bin / hostname hostsname
5, configure el acceso sin contraseña ssh para
generar un par de claves de clave pública
Ejecute en cada nodo por separado:
Entrada de línea de comando: ssh-keygen -t rsa y
presione Entrar hasta que se complete la generación. Una vez completada la
ejecución, se generan dos archivos id_rsa e id_rsa en el directorio /root/.ssh/ en cada nodo pub
La primera es la clave privada, y la segunda es la clave pública
ejecutada en el nodo maestro:
scp /root/.ssh/id_rsa.pub root @ doop2: /root/.ssh/
scp /root/.ssh/id_rsa.pub root @ doop3: /root/.ssh/
scp /root/.ssh/id_rsa.pub root @ doop4: /root/.ssh/Introduzca
el siguiente comando en todas las sesiones de la ventana xshell : 
cd /root/.ssh/
cp id_rsa.pub Authorizedkeys
Finalmente, compruebe si la configuración es exitosa.
Ejecute
ssh doop2 en doop1 y
ssh doop3
puede saltar a la interfaz de operación de los dos nodos secundarios correctamente. Del mismo modo, inicie sesión en el nodo maestro y otros nodos secundarios de la misma manera en cada nodo secundario. Significa que la configuración es exitosa.
6. Instale jdk (las cuatro máquinas deben estar instaladas)
Instale en la misma ubicación /usl/local/jdk1.8.0_191
Descargue JDK: https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads 2133151.html
Descomprima el JDK: tar -zxvf /usr/local/jdk-8u73-linux-x64.gz
Configure las variables de entorno, edite el archivo de perfil:
vi / etc / profile
Agregue el siguiente código al final del archivo de perfil:
export JAVA_HOME = / usr / local / jdk1 .8.0_191
export PATH = $ JAVA_HOME / bin: $ PATH
export CLASSPATH = $ JAVA_HOME / lib: $ JAVA_HOME / jre / lib para
guardar el archivo que acaba de editar: source / etc / profile para
probar si la instalación fue exitosa: java -version
7. Instale hadoop. La
ubicación de instalación es personalizada. Por ejemplo, instálela en el directorio / usr / local para
descargar el paquete hadoop:
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.7/hadoop- 2.7.7.tar.gz se
coloca en el directorio / usr / local, extraiga el hadoop
tar -zxvf hadoop-2.7.7.tar.gz
para generar el directorio hadoop-2.7.7 en usr.
Configure las variables de entorno:
vi / etc / profile
en Agregar al final:
exportar HADOOP_HOME = / usr / local / hadoop-2.7.7
export PATH = $ PATH: $ HADOOP_HOME / bin: $ HADOOP_HOME / sbin
Guarde el perfil recién editado para que tenga efecto:
source / etc / profile
8. Configure el archivo de
configuración hadoop de configuración hadoop
La ubicación del archivo a configurar es / usr / local / hadoop -2.7.7 / etc / hadoop, los siguientes archivos deben modificarse:
hadoop-env.sh
yarn-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
esclavos
maestros
Tanto en hadoop-env.sh como en yarn-env.sh, agregue la variable de entorno
jdk hadoop-env.sh y
agregue el siguiente código:
exporte JAVA_HOME = / usr / local / jdk1.8.0_191 a la siguiente ubicación: 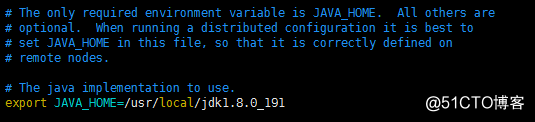
yarn-env.
Agregue el siguiente código en sh :
export JAVA_HOME = / usr / local / jdk1.8.0_191 a la siguiente ubicación: agregue el siguiente código 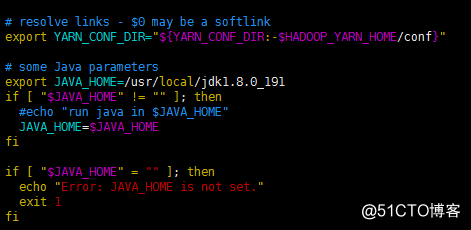
en core-site.xml
:
<configuración> puerto de
transmisión de datos- >
<propiedad>
<name> fs.defaultFS </name>
<value> hdfs: // doop1: 9000 </value>
</property>
<property>
<name> io.file.buffer.size </name>
<value> 131072 < / value>
</property>
<! - hadoop 临时 目录 , fsimage 临时 文件 也会 存在 这个 目录 , 数据 不能 丢 ->
<property>
<name> hadoop.tmp.dir </name>
<value> archivo: / usr / temp </value>
</property>
<property>
<name> hadoop.proxyuser.root.hosts </name>
<value> </value>
</property>
<property>
<name> hadoop.proxyuser. root.groups </name>
<value> </value>
</property>
</ configuration>
Nota: la carpeta temporal debajo de la ruta después del archivo en el código anterior debe ser creada por él mismo
.
Agregue el siguiente código a hdfs-site.xml :
<configuración>
<! - secundario namenode 配置 ->
<property>
<name> dfs.namenode.secondary.http-address </name>
<value> doop4: 50090 </value>
</property>
<property>
<name> dfs .namenode.secondary.https-address </name>
<value> doop4: 50091 </value>
</property>
<property>
<name> dfs.namenode.name.dir </name>
<value> archivo: / usr / dfs / name </value>
</property>
<property>
<name> dfs.datanode.data.dir </name>
<value> archivo: / usr / dfs / data </value>
</property>
<propiedad >
<name> dfs.replication </name>
<value> 2 </value>
</property>
<property>
<name> dfs.webhdfs.enabled </name>
<value> true </value>
</property>
<property>
<name> dfs.permissions </ name>
<value> false </ value>
</ property>
<property>
<name> dfs.web.ugi </ name>
<value> supergroup </ value>
</ propiedad>
</ configuration> La
configuración del nombre de host DataNode en esclavos se
modifica a:
doop2
doop3
doop4
masters La configuración del nombre de host SecondaryNameNode se
modifica a:
doop4 en
mapred-site.xml
(tenga en cuenta que mapred-site.xml.template debe renombrarse a .xml Archivo mv mapred-site.xml.template mapred-site.xml)
agregue el siguiente código:
<configuración>
<propiedad>
<nombre> mapreduce.framework.name </ nombre>
<valor> hilo </ valor>
</ propiedad>
<propiedad>
<nombre> mapreduce.jobhistory.address </nombre>
<value> doop1: 10020 </value>
</property>
<property>
<name> mapreduce.jobhistory.webapp.address </name>
<value> doop1: 19888 </value>
</property>
</configuration>
hilo -site.xml 中
添加 如下 代码 :
<configuración>
<propiedad>
<nombre> yarn.nodemanager.aux-services </name>
<value> mapreduce_shuffle </value>
</property>
<property>
<name> yarn.nodemanager .aux-services.mapreduce.shuffle.class </name>
<value> org.apache.hadoop.mapred.ShuffleHandler </value>
</property>
<property>
<name> yarn.resourcemanager.address </name>
<value> doop1: 8032 </value>
</property>
<property>
<name> yarn.resourcemanager.scheduler.address </name>
<value> doop1: 8030 </value>
</property>
<property>
<name> yarn.resourcemanager.resource-tracker.address </name>
<value> doop1: 8031 </value>
</property>
<property>
<name> yarn.resourcemanager.admin.address </name>
<value> doop1: 8033 </value>
</property>
<property>
<name> hilo. resourcemanager.webapp.address </name>
<value> doop1: 8088 </value>
</property>
</configuration>
拷贝 hadoop 安装 文件 到 子 节点
主 节点 上 执行 :
rm -rf /usr/local/hadoop-2.7 .7 / share / doc /
scp -r /usr/local/hadoop-2.7.7 root @ doop2: / usr / local /
scp -r /usr/local/hadoop-2.7.7 root @ doop3: / usr / local /
scp -r /usr/local/hadoop-2.7.7 root @ doop4: / usr / local /
Copie el perfil en el
nodo maestro del nodo secundario y ejecute:
scp / etc / profile root @ doop2: / etc /
scp / etc / profile root @ doop3: / etc /
scp / etc / profile root @ doop4: / etc /
valide el nuevo perfil en los tres nodos secundarios:
fuente / etc / profile
Configure la variable de entorno Hadoop
vi ~ / .bash_profile
al final y agregue:
export HADOOP_HOME = / usr / local / hadoop-2.7.7
export PATH = $ PATH: $ HADOOP_HOME / bin: $ HADOOP_HOME / sbin
scp ~ / .bash_profile root @ doop2: / root /
scp ~ / .bash_profile root @ doop3: / root /
scp ~ / .bash_profile root @ doop4: / root /
加载 配置
source ~ / .bash_profile
Formatee el namenode del masternode
, ingrese el directorio hadoop en el masternode y ejecute:
hdfs namenode -format
Consejo: Formateado con éxito indica formateo exitoso
Inicie el
nodo maestro de Hadoop y ejecútelo en el directorio de Hadoop:
start-all.sh
stop Hadoop
stop-all.sh
El proceso jps en el nodo maestro es el siguiente: El proceso jps en cada nodo secundario del
NameNode
ResourceManager
es el siguiente:
Doop DataNode
NodeManager
tendrá múltiples procesos
SecondaryNameNode.
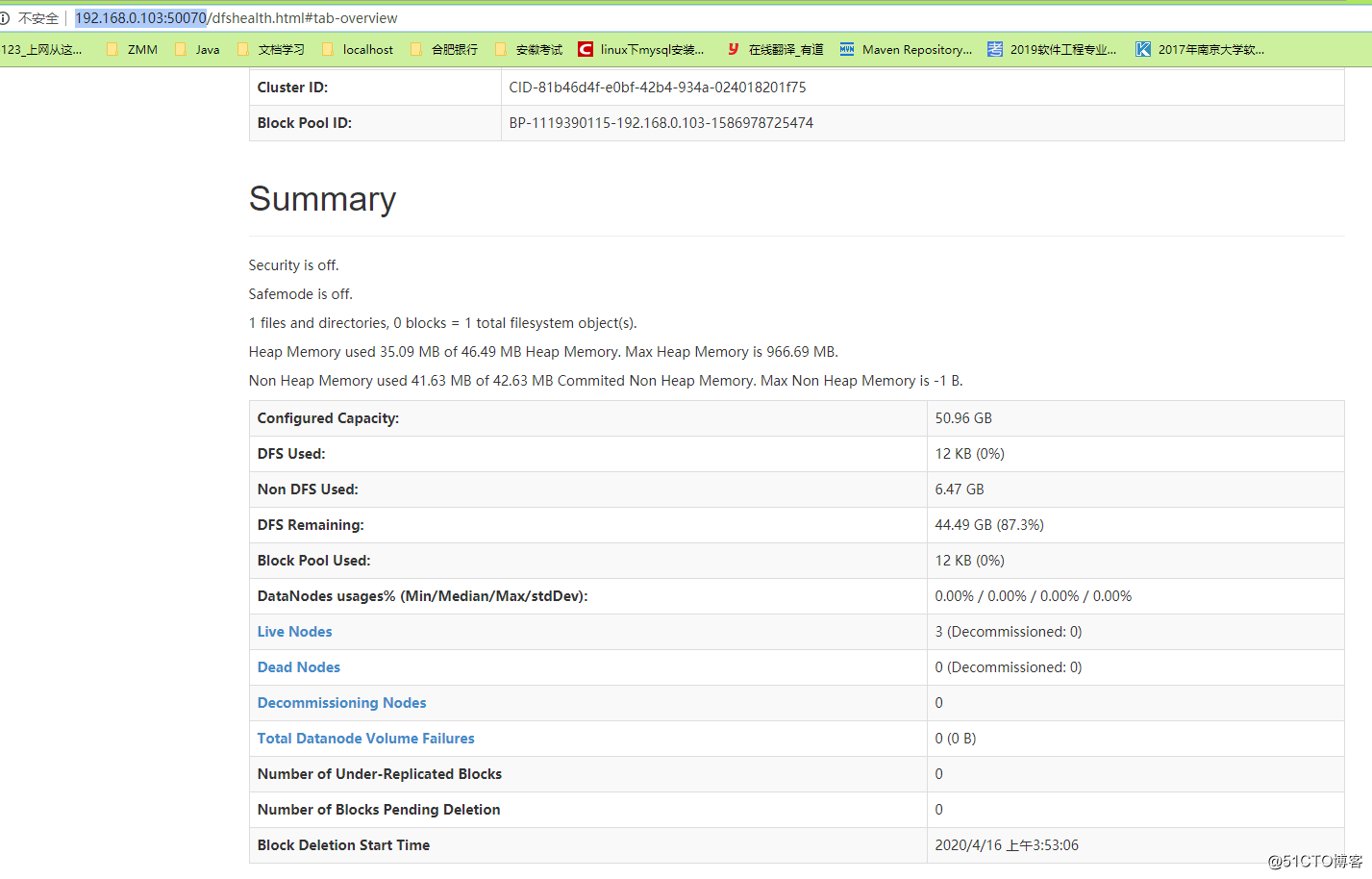
Si esto significa que la configuración del clúster Hadoop es exitosa
Dirección de acceso http://192.168.0.103:50070/
Si desea acceder por nombre de host, debe configurar el archivo de host de Windows
y luego ver la página