Desde la perspectiva de la optimización en sí , BatchSize y la tasa de aprendizaje (y el impacto de la estrategia de reducción de la tasa de aprendizaje) en la capacitación de aprendizaje profundo son los
parámetros más importantes que afectan la convergencia del rendimiento del modelo.
La tasa de aprendizaje afecta directamente el estado de convergencia del modelo, y el tamaño de lote afecta el rendimiento de generalización del modelo. Los dos están directamente relacionados con el numerador y el denominador, y también pueden afectarse entre sí.
Directorio de artículos
- 1 El efecto de Batchsize en los resultados del entrenamiento (mismo número de rondas de época)
- Comparación de resultados
- 1. Alexnet 2080s train_batchsize = 32, val_batchsize = 64。lr = 0.01 GHIMyousan
- 2. Alexnet 2080 train_batchsize = 64, val_batchsize = 64, lr = 0.01 GHIM-me 14k itera
- 3. Alexnet 2080s train_batchsize = 64, val_batchsize = 64, lr = 0.02 GHIM-yousan
- 4 Squeezenet 2080s train_bs = 64 val-bs = 64 lr 0.01 GHIMyousan
- 4- Experimento de repetibilidad Squeezenet 2080s train_bs = 64 val-bs = 64 lr 0.01 GHIM-me, el resultado sigue siendo demasiado ajustado 87% acc
- 5 == mobilenetv1 2080s t-bs: 64, v-bs: 64 lr: 0.01, GHIM-me == sobreajuste
- 5 == mobilenetv2 2080s t-bs: 64, v-bs: 64 lr: 0.01, GHIM-me == sobreajuste
- 6 mobilenetv1 2080 t-bs: 64 v-bs: 64 lr: 0.01 GHIM-me equipado
- 6 mobilenetv2 2080 t-bs: 64 v-bs: 64 lr: 0.01 GHIM-me equipado
- 10 predecesores hablan de lotes
- 1 ** Dentro de cierto rango, en términos generales, cuanto mayor sea el Batch_Size, más precisa será la dirección hacia abajo que determine y menor será la oscilación de entrenamiento. ** **
- 2 == El rendimiento del lote grande se reduce porque el tiempo de entrenamiento no es lo suficientemente largo, lo que no es esencialmente un problema con el tamaño del lote. Las actualizaciones de los parámetros bajo las mismas épocas se reducen, por lo que se requiere un mayor número de iteraciones. ==
- 3 == El tamaño de lote grande converge al mínimo agudo, mientras que el tamaño de lote pequeño converge al mínimo plano, que tiene una mejor capacidad de generalización. ==
- 4 El tamaño del lote aumenta, la tasa de aprendizaje debería aumentar con los demás
- 5 Aumentar el tamaño de Batchsize es equivalente a agregar atenuación de la tasa de aprendizaje
- Conclusión
- 1 Si se aumenta la tasa de aprendizaje, el tamaño del lote también debería aumentar, de modo que la convergencia sea más estable.
- 2 Intente utilizar una tasa de aprendizaje grande, porque muchos estudios han demostrado que una tasa de aprendizaje mayor es propicia para mejorar la capacidad de generalización. Si realmente desea decaer, puede probar otros métodos, como aumentar el tamaño del lote, la tasa de aprendizaje tiene un gran impacto en la convergencia del modelo y ajustarlo cuidadosamente.
- 3 La desventaja de usar bn es que no puede usar un tamaño de lote demasiado pequeño, de lo contrario, la media y la varianza estarán sesgadas. Así que ahora es generalmente tanto como la memoria de video puede poner. Además, cuando el modelo se usa realmente, es realmente más importante distribuir y preprocesar los datos. Si los datos no son buenos, es inútil jugar más trucos.
1 El efecto de Batchsize en los resultados del entrenamiento (mismo número de rondas de época)
Aquí usamos GHIM-20, 20 imágenes de cada tipo en 20 categorías, un total de 10000 (train9000) (val1000) y
un total de 100 épocas (equivalente a recorrer 9000 imágenes 100 veces, de las cuales acc (el recorrido se imprime 10 veces por iteración) Un total de 1000 val_list)

Alexnet usó aquí (train_batchsize = 32 y train_batchsize = 64 respectivamente)
Comparación de resultados
1. Alexnet 2080s train_batchsize = 32, val_batchsize = 64。lr = 0.01 GHIMyousan
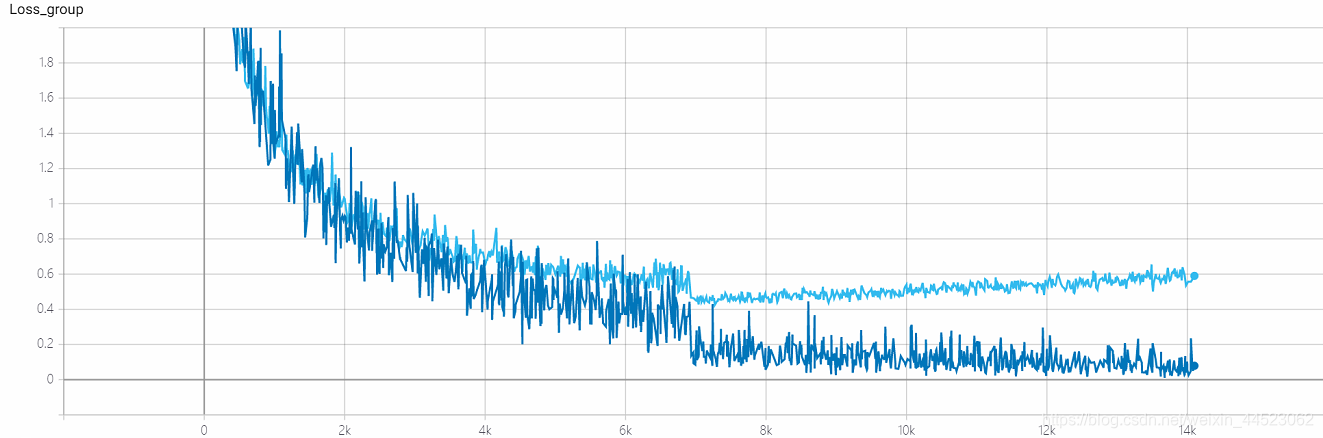
- Entrenamiento de la década de 2080 s 4.68h, casi 28k iteraciones == 100epoch x 9000/32, cada lote de trenes registra una pérdida azul oscuro
- val-batch registra un azul claro con pérdida de val
Pregunta: ¿La pérdida es convergente?
acc-loss siempre es mayor que train-loss para ver que es un problema de sobreajuste
Comprueba algunas respuestas
1. Teóricamente, no converge , es decir, hay un problema con la red que diseñó, que también es el primer factor que debe considerarse: si existe el gradiente, es decir, si la propagación inversa se ha roto,
2. Teóricamente, es convergente :-
La configuración de la tasa de aprendizaje no es razonable (en la mayoría de los casos). Si la configuración de la tasa de aprendizaje es demasiado grande, causará no convergencia. Si es demasiado pequeña, la tasa de convergencia será muy lenta;
-
El tamaño de lote es demasiado grande, cae en el óptimo local y no puede alcanzar el óptimo global, por lo que no puede continuar convergiendo;
-
La capacidad de la red, es cierto que la pérdida de la red superficial para completar tareas complejas no disminuye. El diseño de la red es demasiado simple. En general, cuanto mayor es el número de capas y nodos de la red, mayor es la capacidad de ajuste. Incapaz de adaptarse a situaciones complejas, también provocará la no convergencia.
La base de la disminución del paso de la tasa de aprendizaje no es demasiado grande, y el tamaño de lote = 32 no es grande, por lo que es convergente. ? (Después de todo, la pérdida = 0.0008 no es demasiado grande.) La
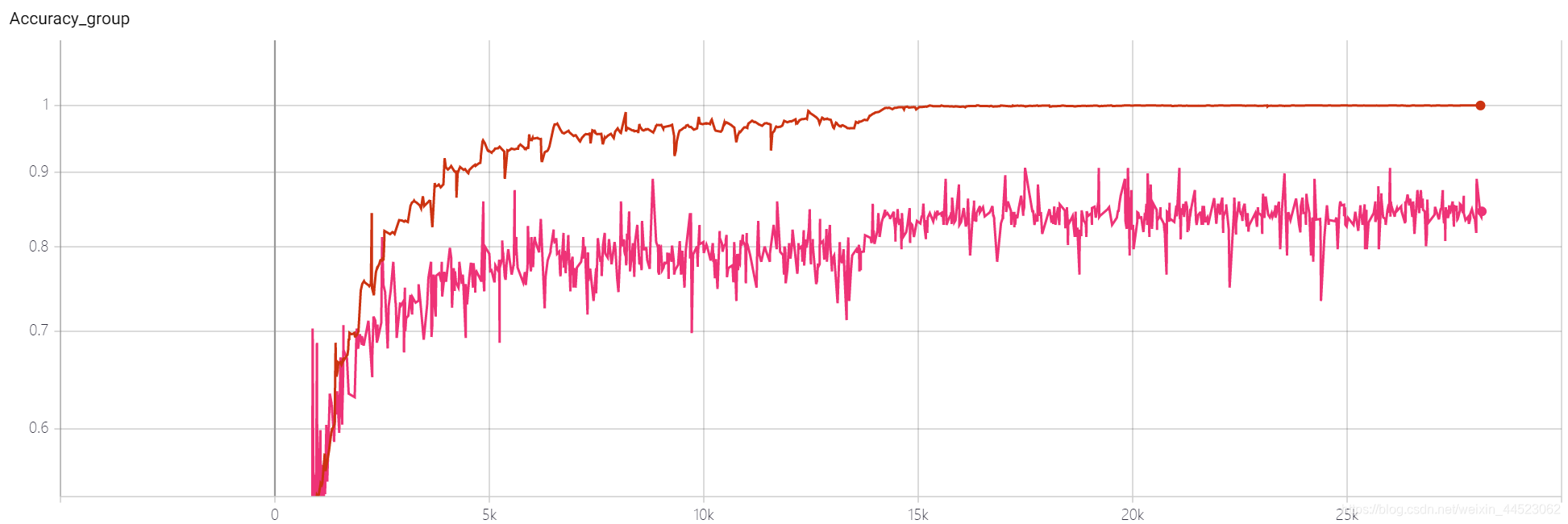
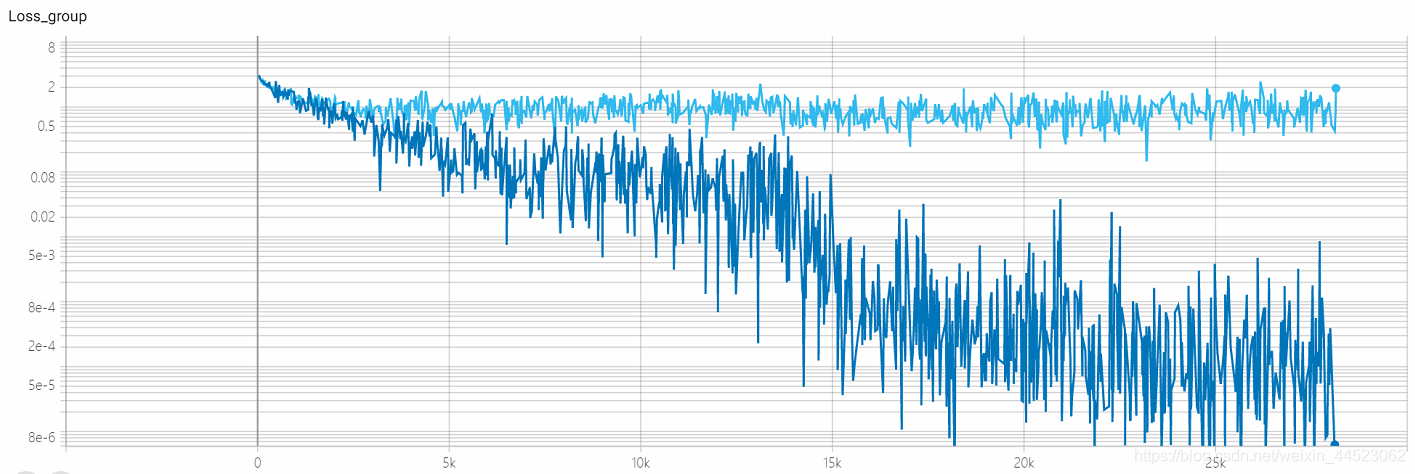
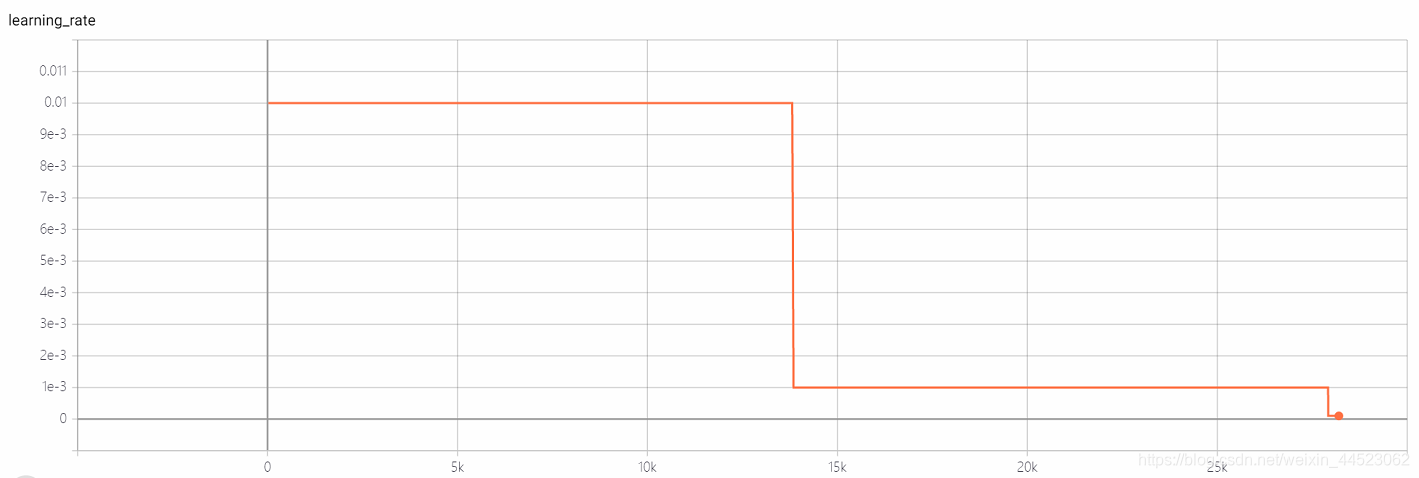
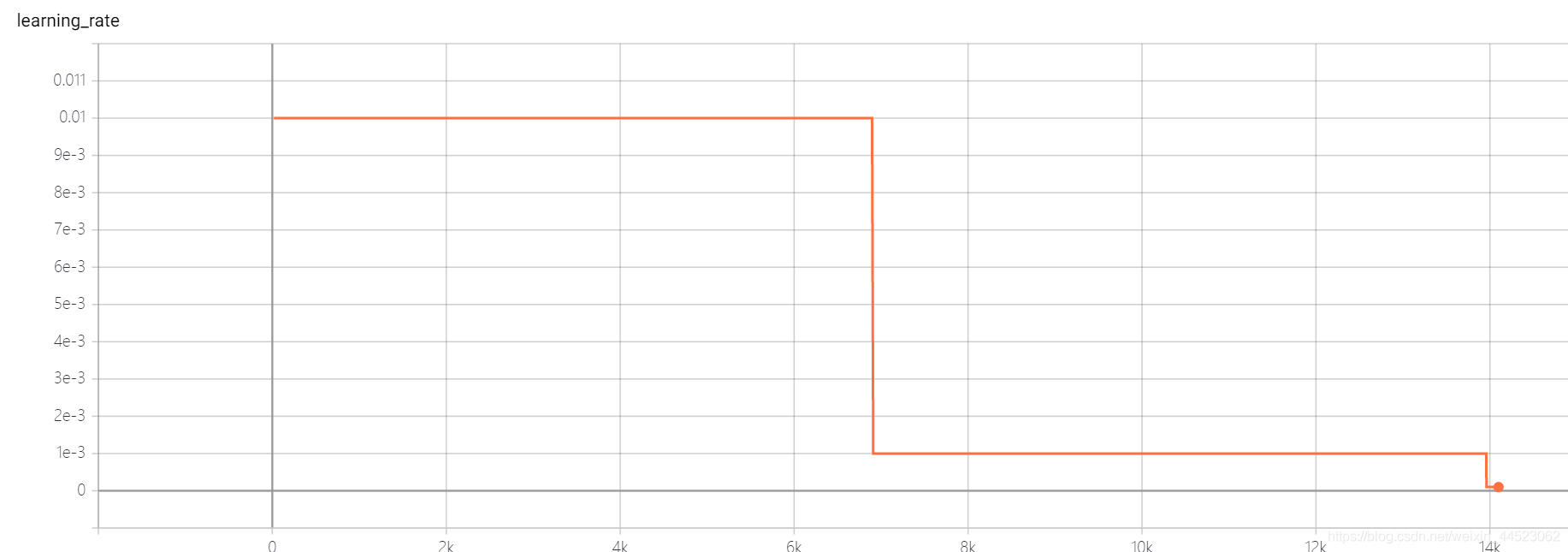
curva acc es la siguiente: básicamente se ajusta después de mirar la imagen después de 15k iteraciones (es decir, época = 15000 * 32/9000 = 53 rondas). Lo interesante es que corresponde al aprendizaje La tasa disminuyó de 0.01 a 0.001
Pregunta: ¿Por qué acc84% de val no sube?
El conjunto de entrenamiento funciona bien y la diferencia del conjunto de prueba
es demasiado adecuada , lo que indica que las características aprendidas aún no están lo suficientemente generalizadas. ¿Qué capa de características de aprendizaje no es lo suficientemente buena?
Solución de sobreajuste
1. Motivo:- La razón del sobreajuste es que la magnitud del conjunto de entrenamiento no coincide con la complejidad del modelo,
- La magnitud del conjunto de entrenamiento es menor que la complejidad del modelo;
- La distribución de características del conjunto de entrenamiento y el conjunto de prueba es inconsistente;
- Los datos de ruido en la muestra ...
2. Solución
(estructura de modelo más simple, aumento de datos, regularización, abandono, detención temprana, conjunto, limpieza de datos)
-
2. Alexnet 2080 train_batchsize = 64, val_batchsize = 64, lr = 0.01 GHIM-me 14k itera
2080 train_batchsize = 64, la iteración de 4.5k se ajusta básicamente (4500 * 64/9000 = 32 rondas), y tanto train como val son mejores. Y el ajuste es bueno
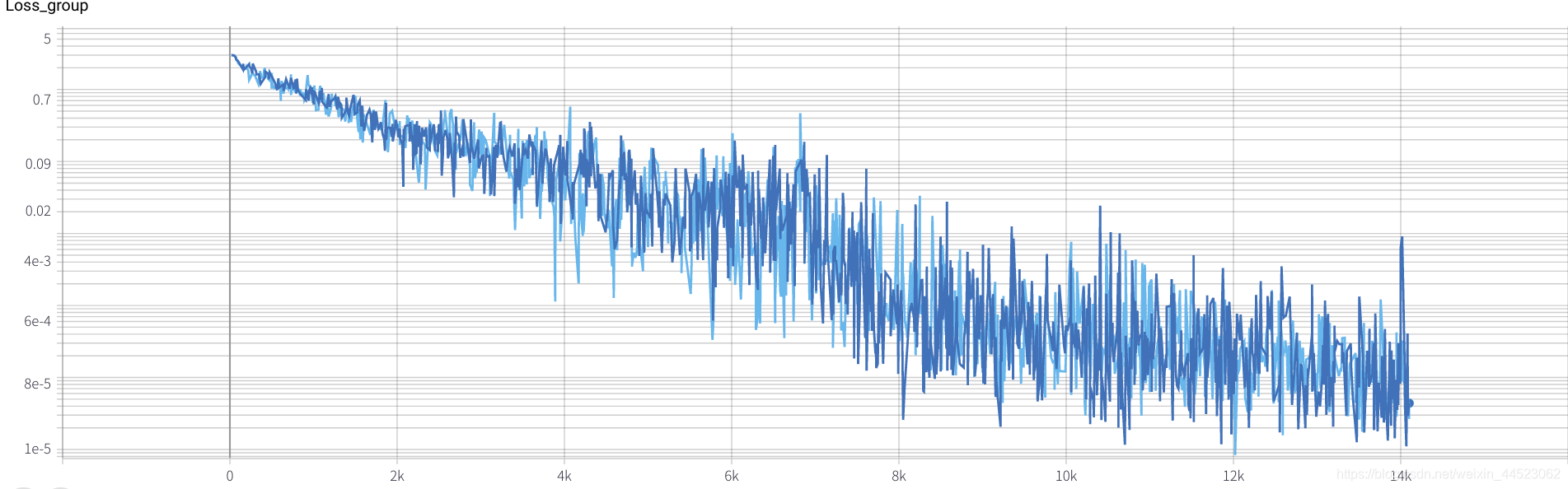
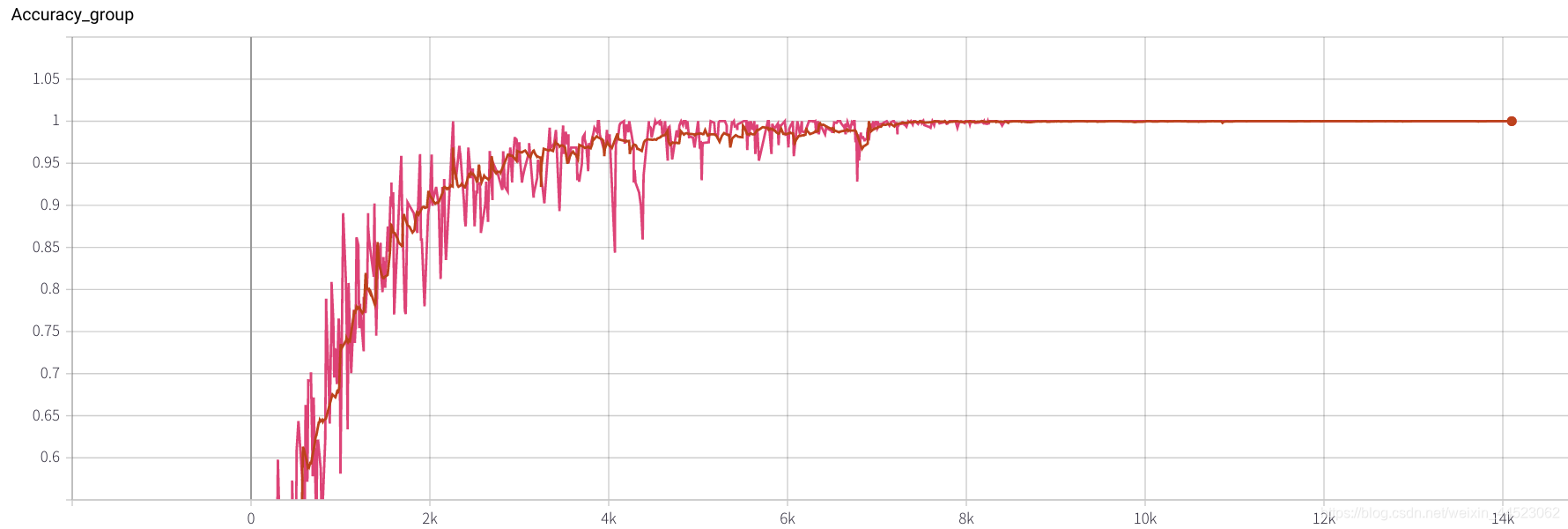
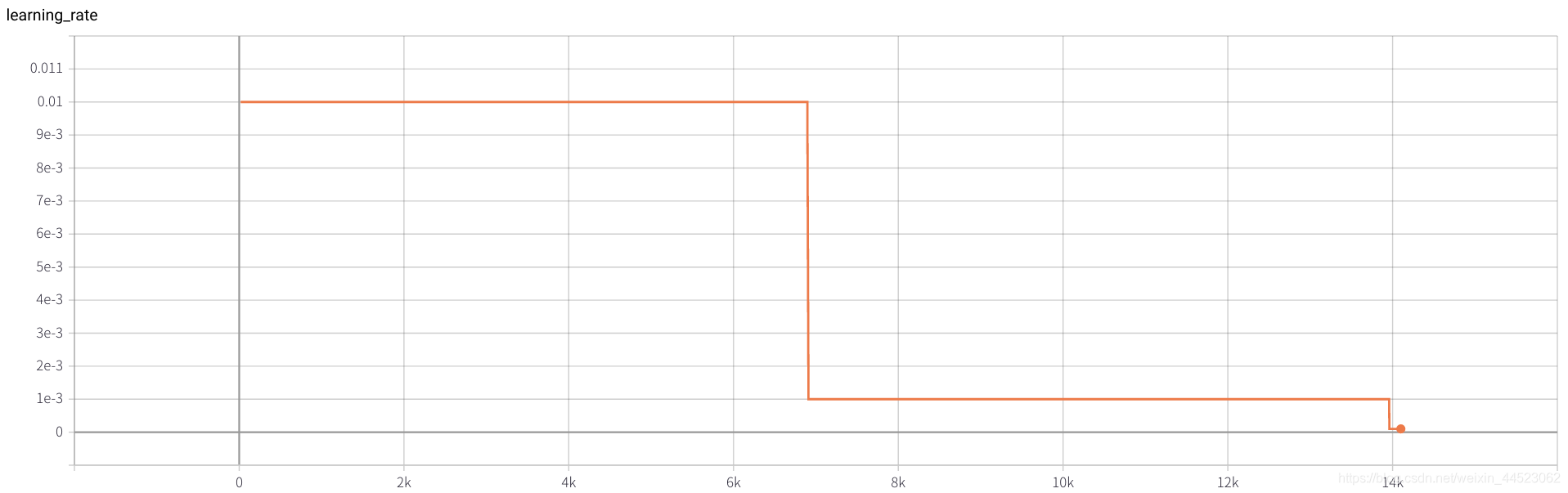
3. Alexnet 2080s train_batchsize = 64, val_batchsize = 64, lr = 0.02 GHIM-yousan
2080, no hay convergencia o sobreajuste? ? ?
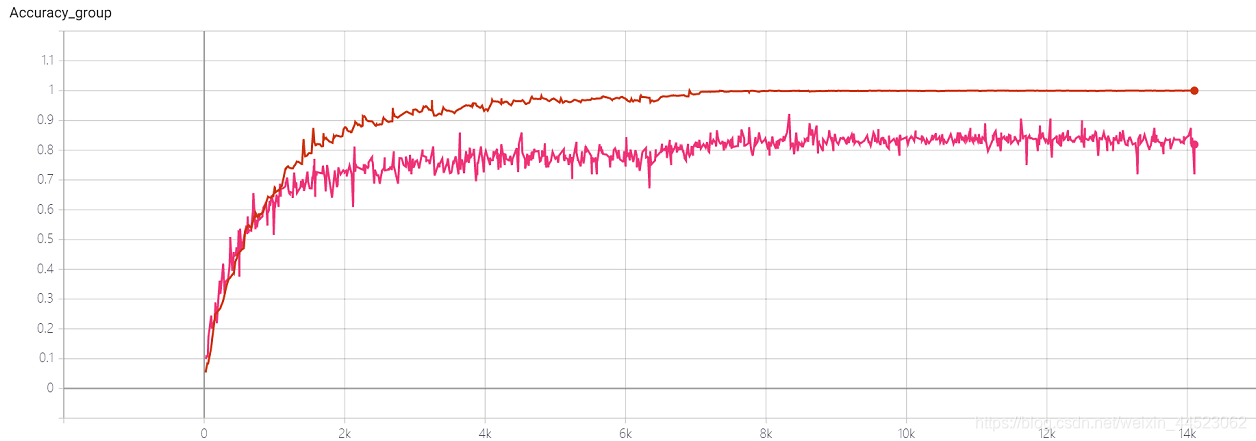
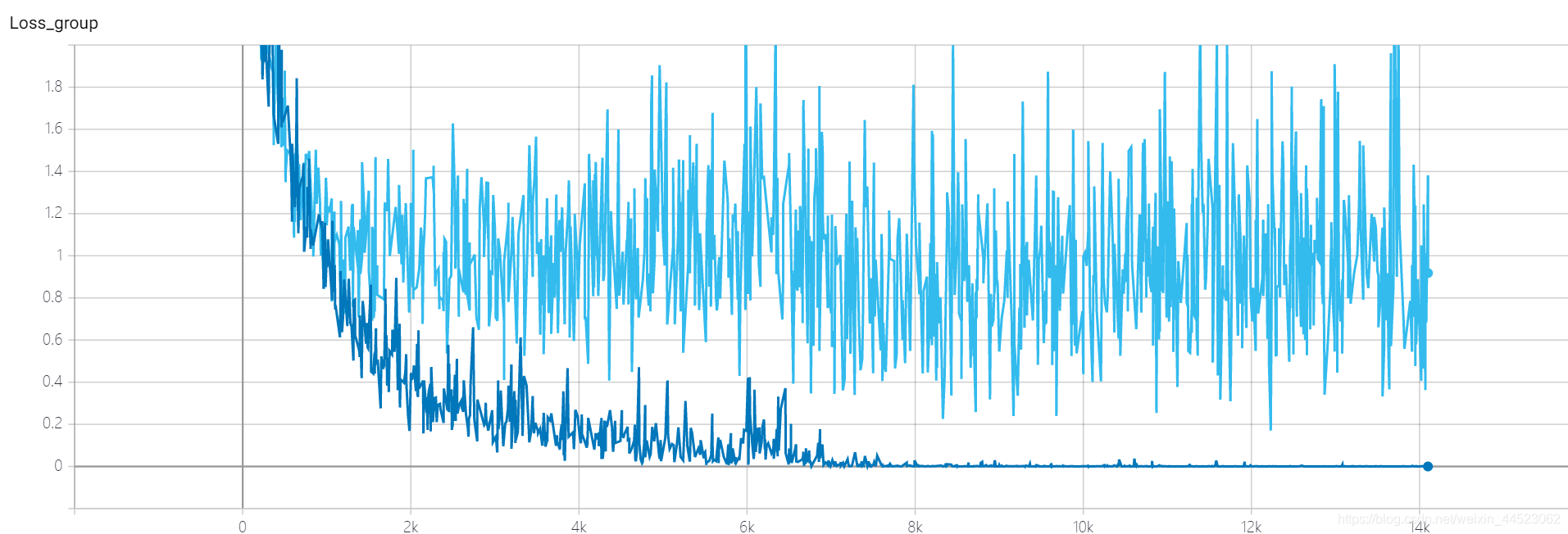
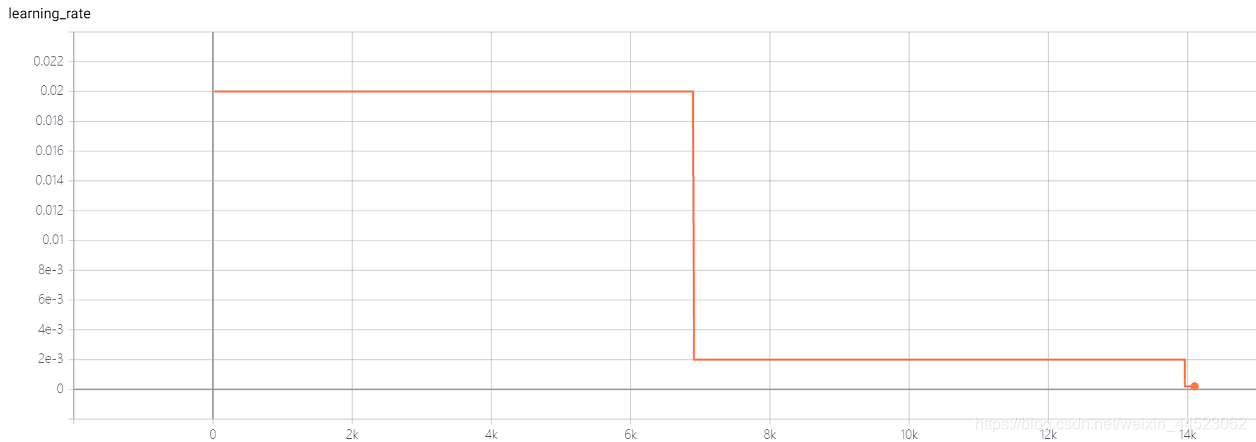
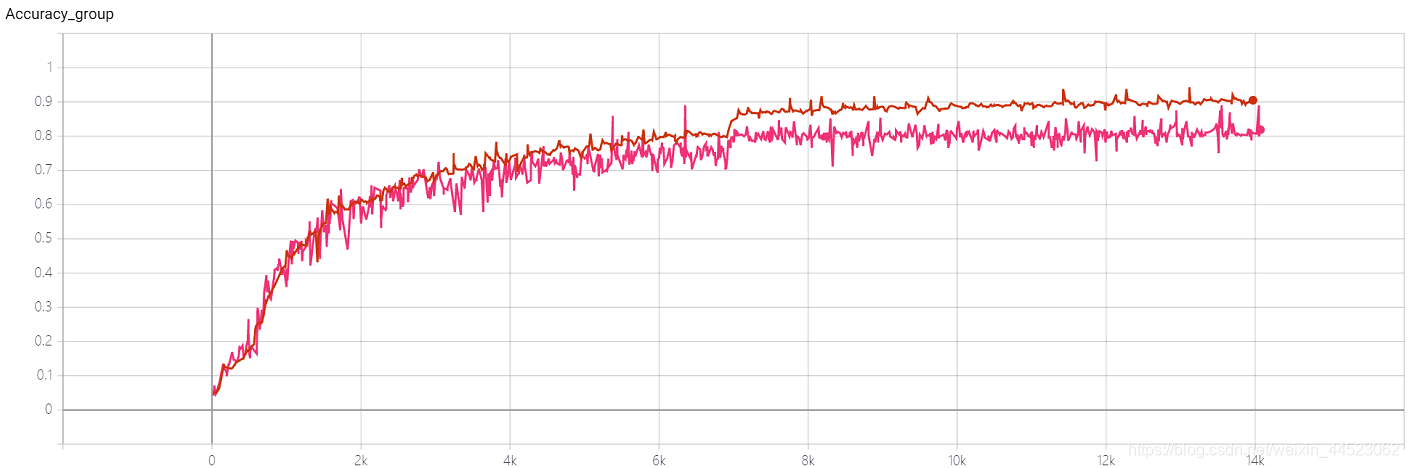
4 Squeezenet 2080s train_bs = 64 val-bs = 64 lr 0.01 GHIMyousan

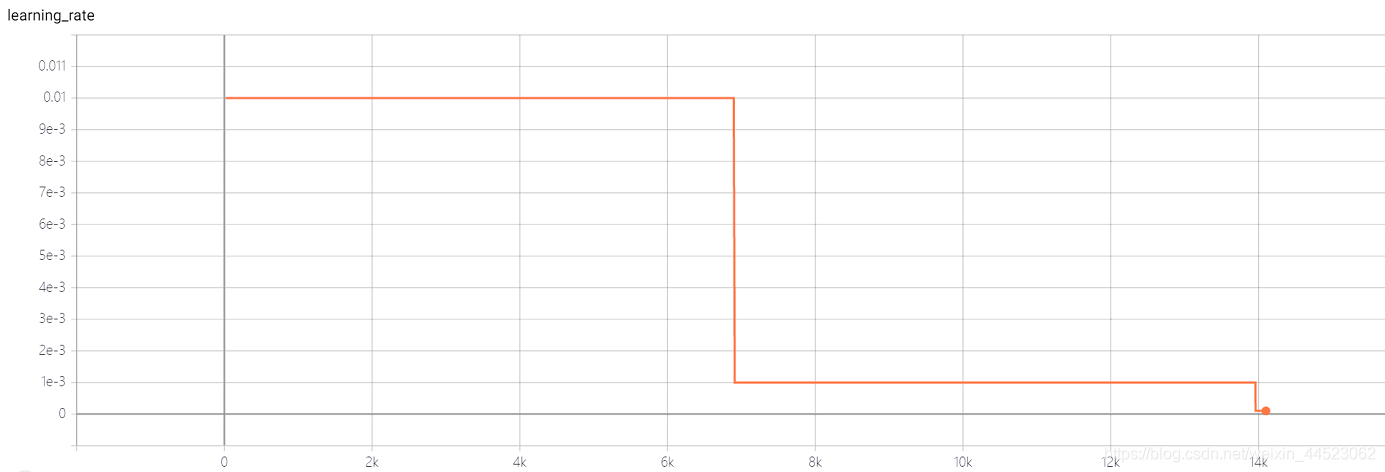
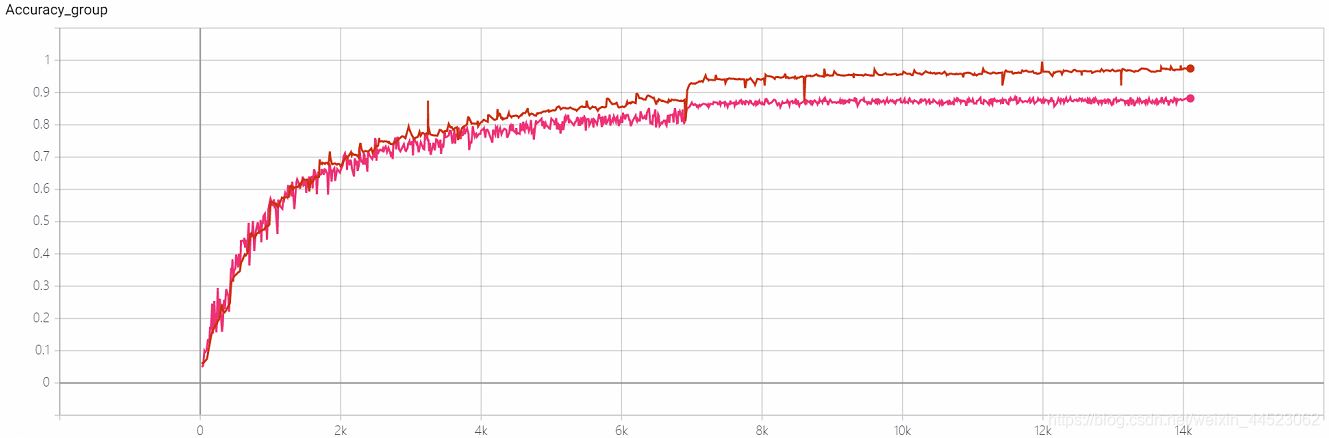
4- Experimento de repetibilidad Squeezenet 2080s train_bs = 64 val-bs = 64 lr 0.01 GHIM-me, el resultado sigue siendo demasiado ajustado 87% acc
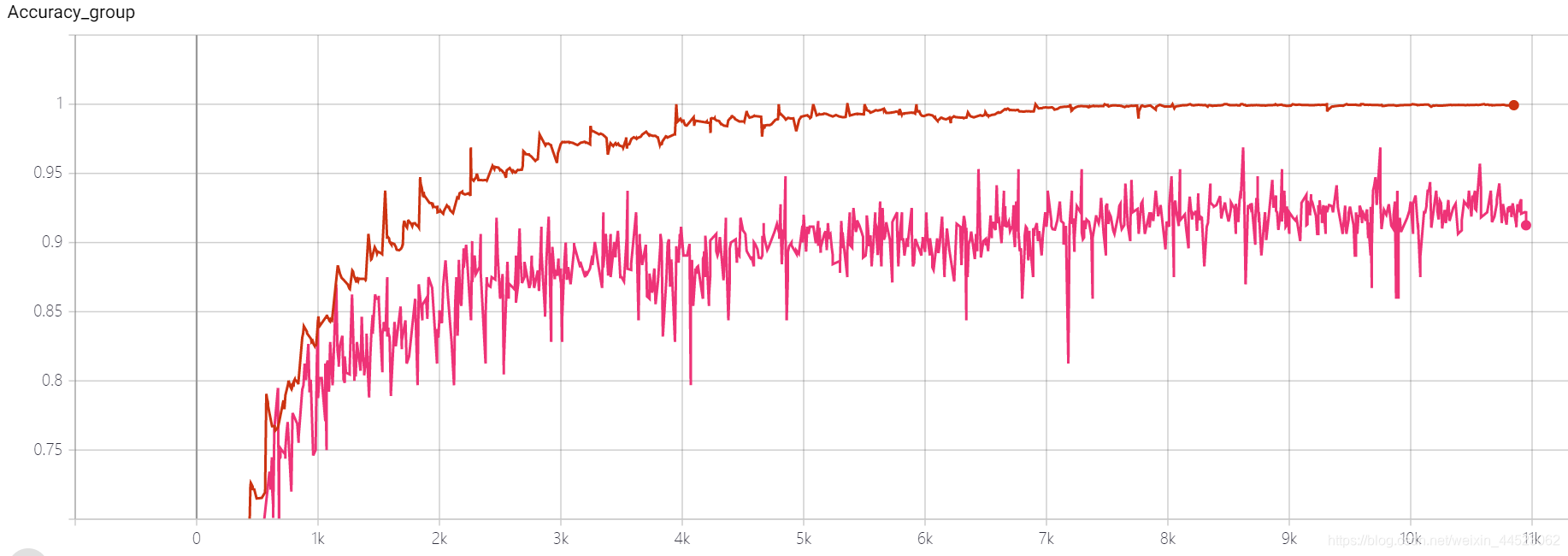
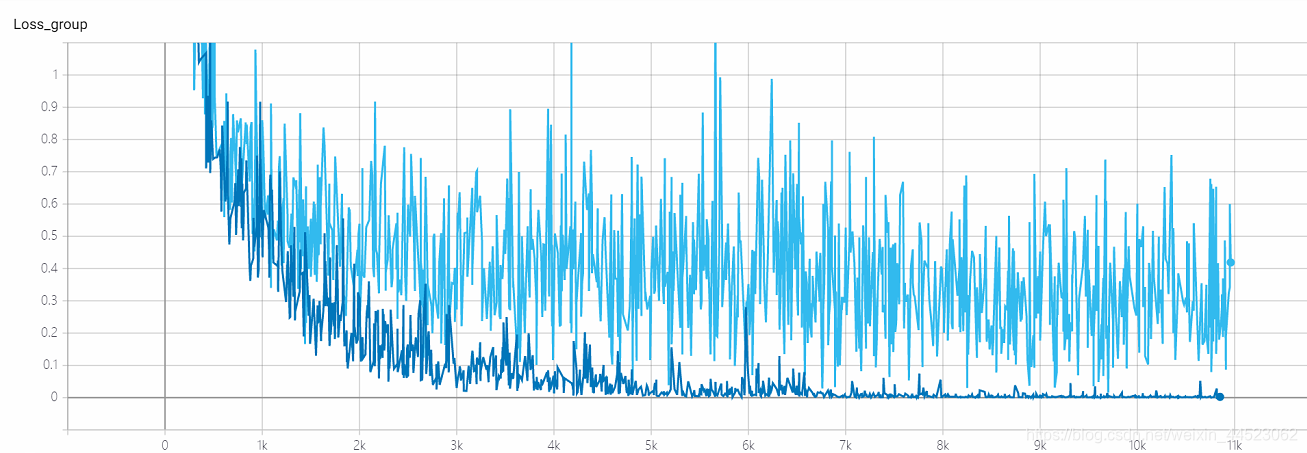
5 5 mobilenetv1 2080s t-bs: 64, v-bs: 64 lr: 0.01, GHIM-meSobreajuste
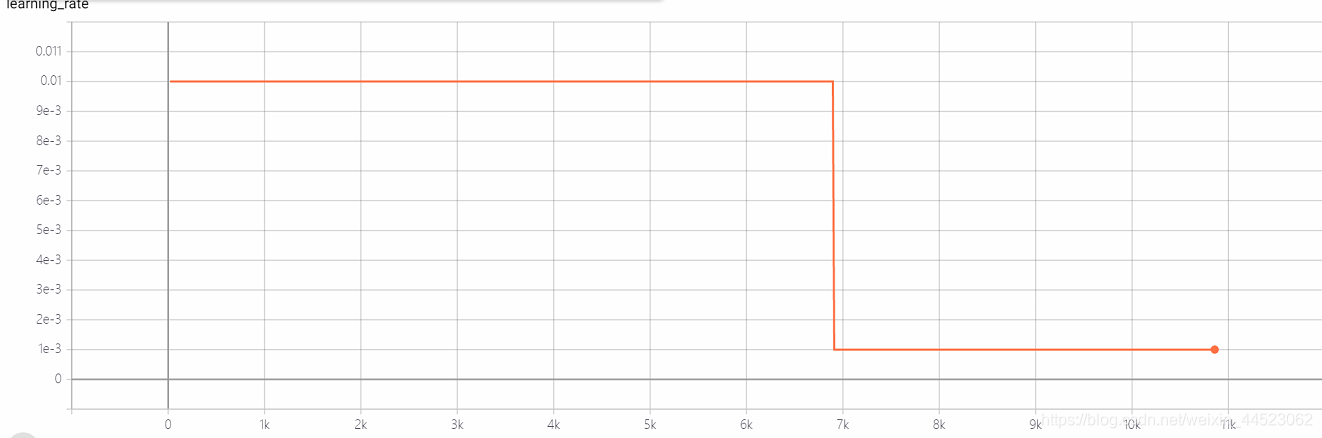
5 5 mobilenetv2 2080s t-bs: 64, v-bs: 64 lr: 0.01, GHIM-meSobreajuste
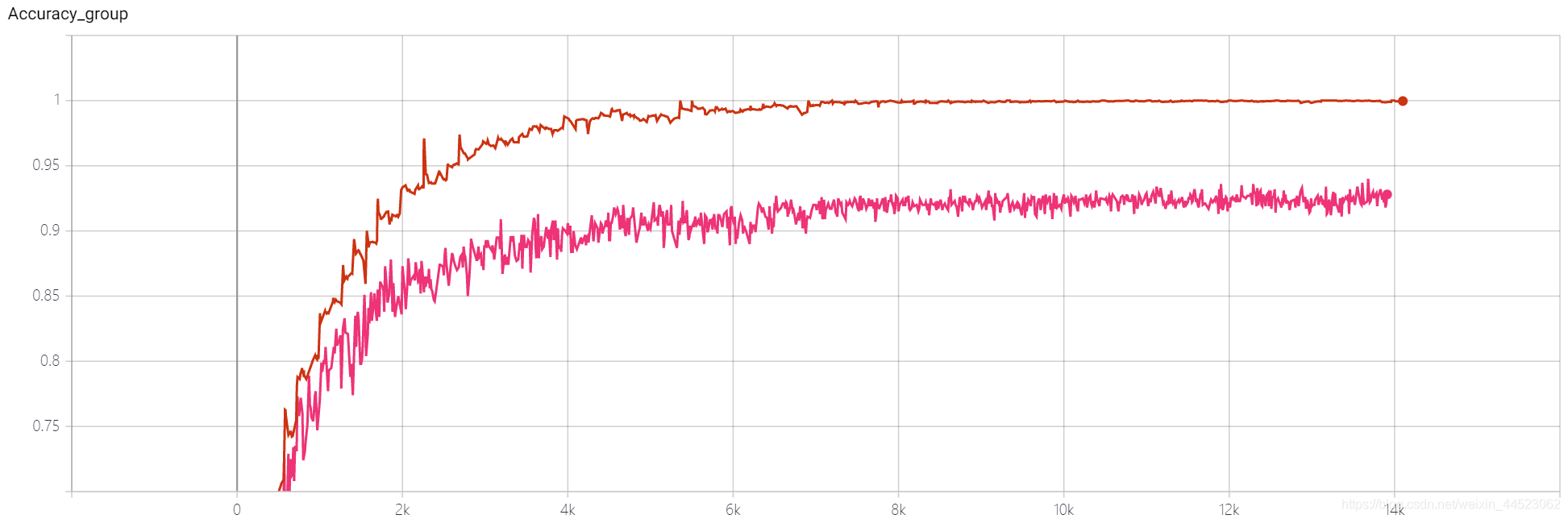
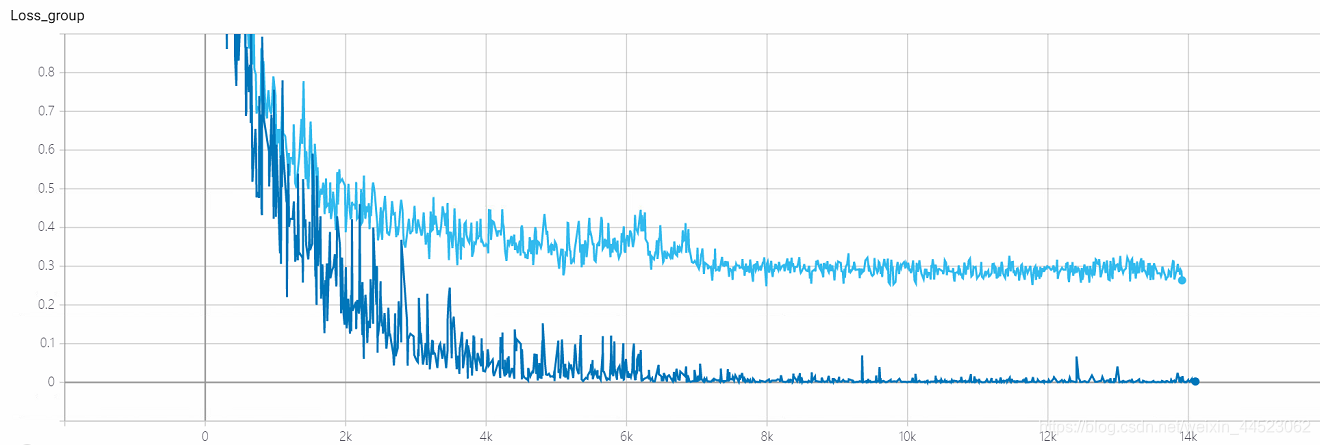
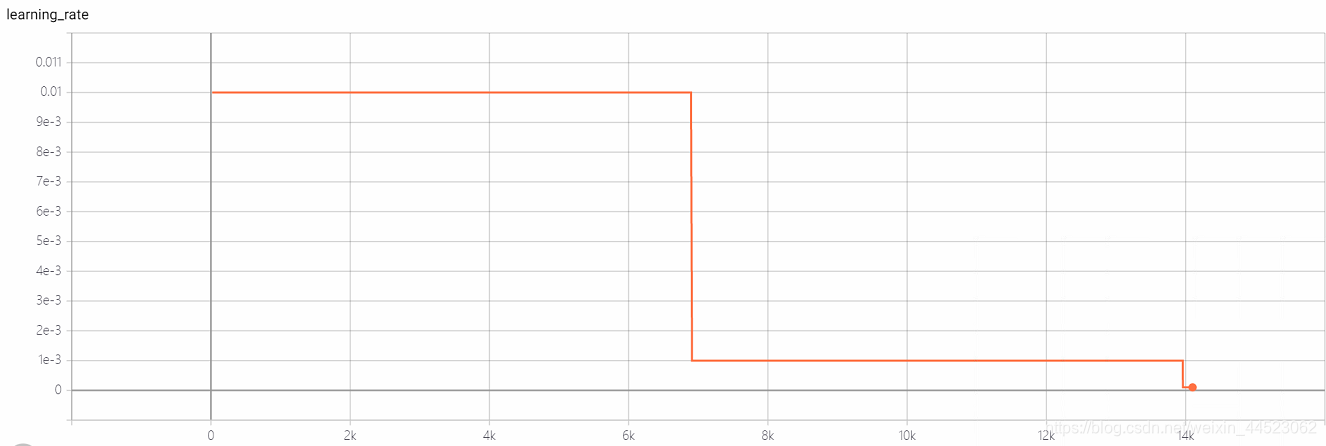
6 mobilenetv1 2080 t-bs: 64 v-bs: 64 lr: 0.01 GHIM-me equipado
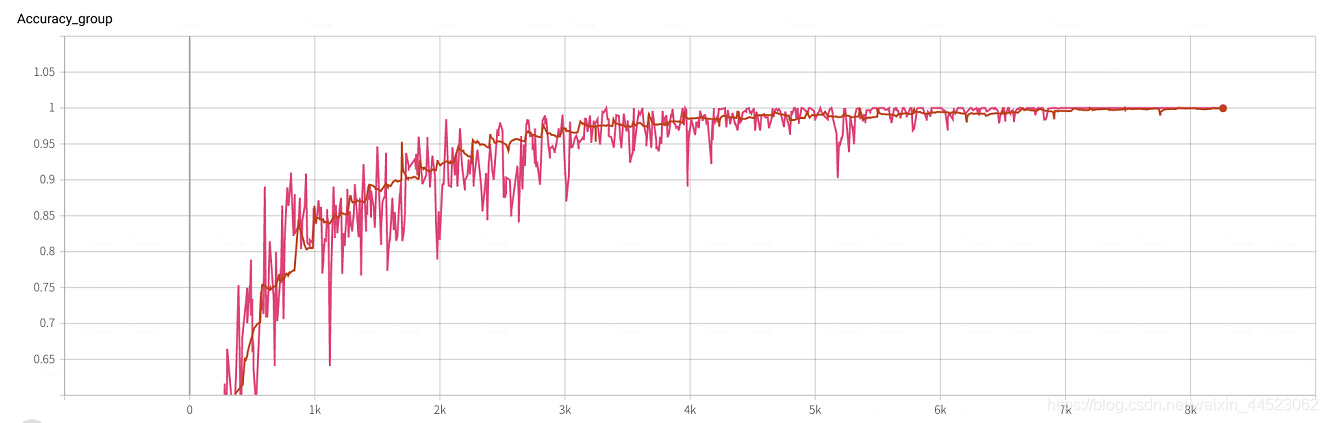

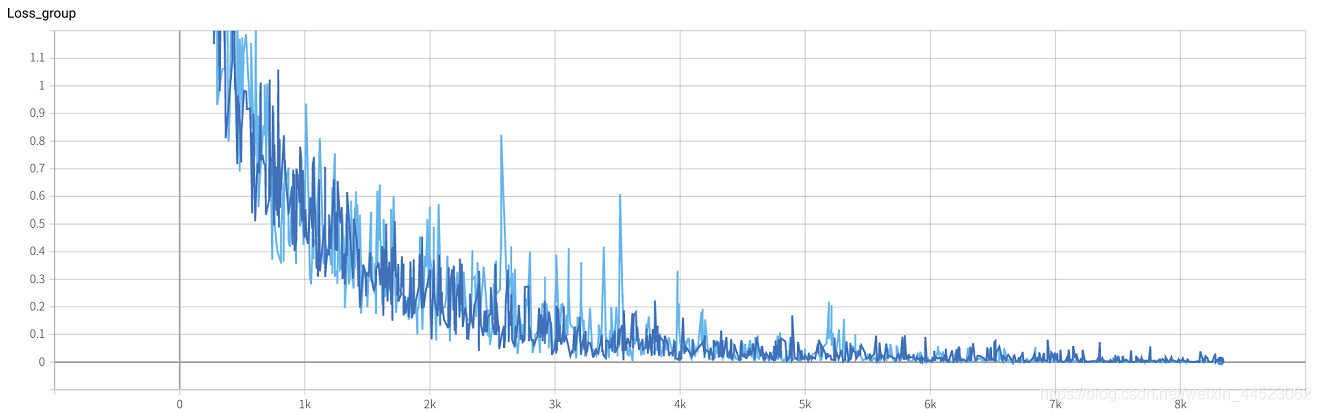
6 mobilenetv2 2080 t-bs: 64 v-bs: 64 lr: 0.01 GHIM-me equipado
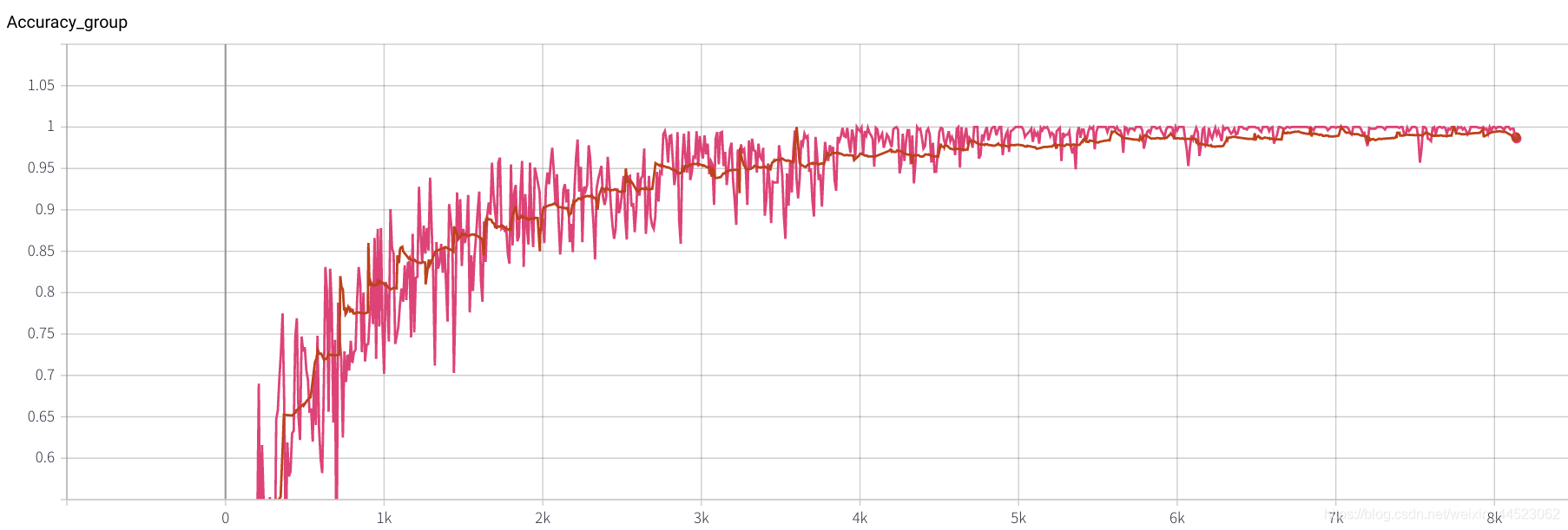
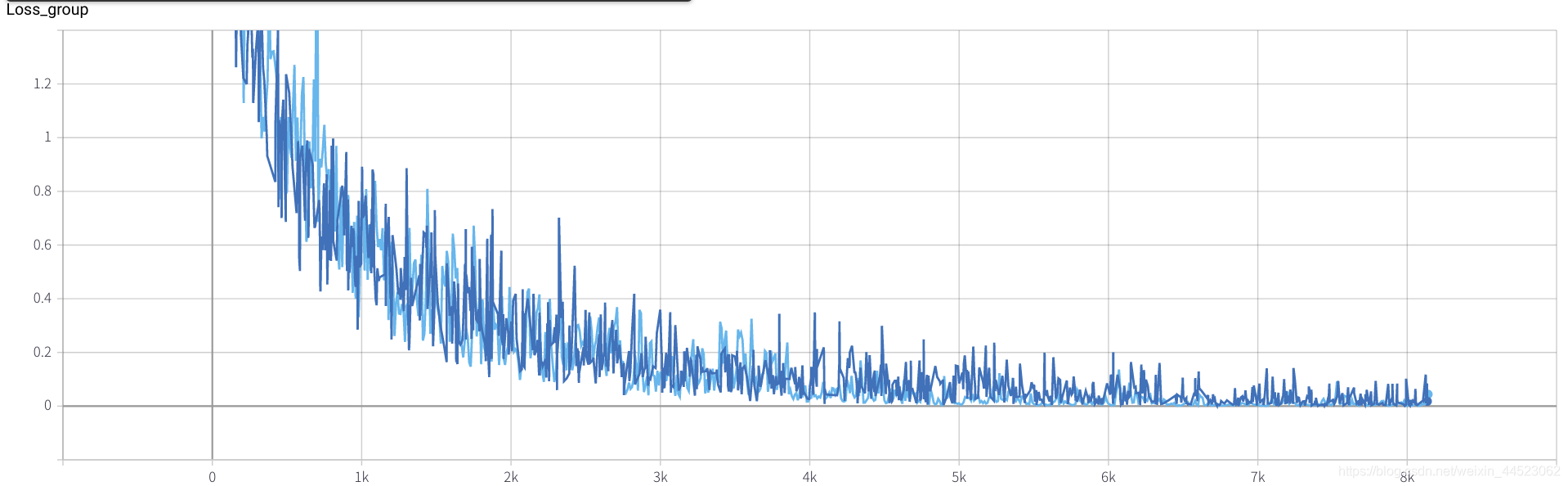
lr = 0.01
10 predecesores hablan de lotes
1 Dentro de un cierto rango, en general, cuanto más grande es el Batch_Size, más precisa es la dirección hacia abajo que determina, lo que resulta en menos choque de entrenamiento.
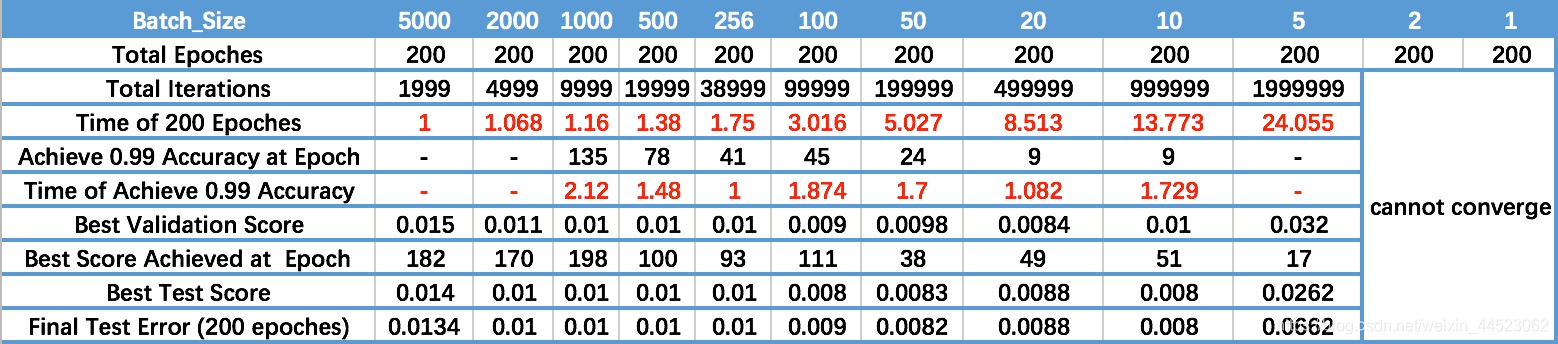
- A medida que aumenta Batch_Size, aumenta el número de épocas necesarias para lograr la misma precisión. Penúltima fila
- A medida que aumenta Batch_Size, más rápido es el procesamiento de la misma cantidad de datos.
- Debido a la contradicción entre los dos factores anteriores, Batch_Size aumenta hasta cierto punto, alcanzando el tiempo óptimo.
- Dado que la precisión de convergencia final caerá en diferentes extremos locales, Batch_Size aumenta algunas veces para alcanzar la precisión de convergencia final óptima.
2 La disminución en el rendimiento del lote grande se debe a que el tiempo de entrenamiento no es lo suficientemente largo, lo cual no es esencialmente un problema con el tamaño del lote.
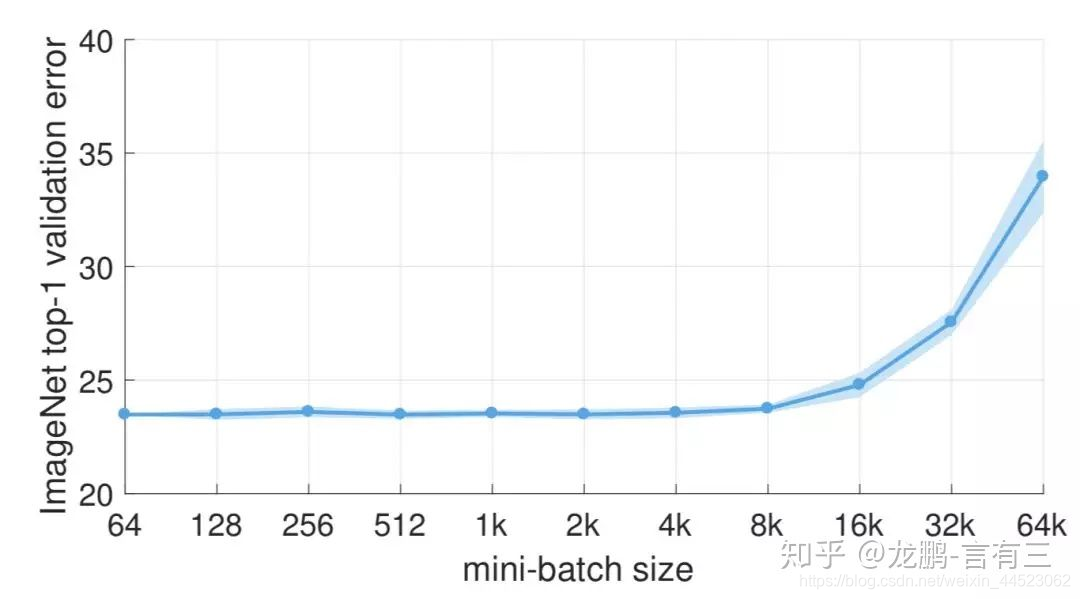
La tasa de error aumenta después de batchsize = 8k
3 El tamaño de lote grande converge al mínimo agudo, mientras que el tamaño de lote pequeño converge al mínimo plano, que tiene una mejor capacidad de generalización.
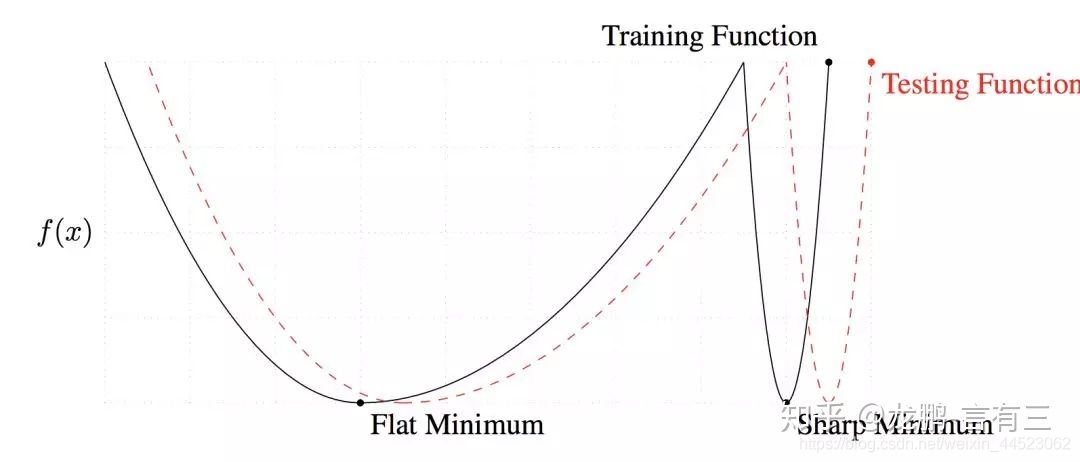
La diferencia entre los dos radica en la tendencia cambiante, una rápida y otra lenta, como se muestra arriba, la razón principal de este fenómeno es que el ruido causado por el pequeño tamaño del lote ayuda a escapar del mínimo agudo.
4 El tamaño del lote aumenta, la tasa de aprendizaje debería aumentar con los demás
Por lo general, cuando aumentamos el tamaño del lote a N veces el original, para asegurarnos de que los pesos actualizados después de la misma muestra sean iguales, de acuerdo con la regla de escala lineal, la tasa de aprendizaje debe aumentarse al N original [5]. Sin embargo, si se quiere mantener la varianza de los pesos, la tasa de aprendizaje debe aumentarse al sqrt original (N) veces [7]. En la actualidad, ambas estrategias se han estudiado y la primera se utiliza principalmente.
5 Aumentar el tamaño de Batchsize es equivalente a agregar atenuación de la tasa de aprendizaje
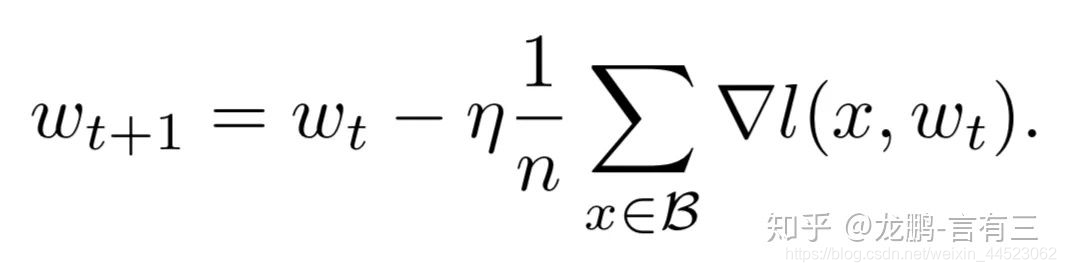
De hecho, se puede ver en la fórmula de actualización de peso de SGD que los dos son de hecho equivalentes, y esto se verifica mediante suficientes experimentos en el artículo
Conclusión
1 Si se aumenta la tasa de aprendizaje, el tamaño del lote también debería aumentar, de modo que la convergencia sea más estable.
2 Intente utilizar una tasa de aprendizaje grande, porque muchos estudios han demostrado que una tasa de aprendizaje mayor es propicia para mejorar la capacidad de generalización. Si realmente desea decaer, puede probar otros métodos, como aumentar el tamaño del lote, la tasa de aprendizaje tiene un gran impacto en la convergencia del modelo y ajustarlo cuidadosamente.
3 La desventaja de usar bn es que no puede usar un tamaño de lote demasiado pequeño, de lo contrario, la media y la varianza estarán sesgadas. Así que ahora es generalmente tanto como la memoria de video puede poner. Además, cuando el modelo se usa realmente, es realmente más importante distribuir y preprocesar los datos. Si los datos no son buenos, es inútil jugar más trucos.
Lectura de referencia
https://zhuanlan.zhihu.com/p/29247151
https://zhuanlan.zhihu.com/p/64864995
