LSTM---La red neuronal recurrente de memoria a largo plazo a corto plazo es una red neuronal muy utilizada. Su característica es que la red introduce el concepto de memoria a largo plazo y memoria a corto plazo, por lo que es adecuada para algunas regresiones y clasificaciones con contexto, como la predicción de la temperatura o la comprensión semántica. Desde la perspectiva del uso de pytorch para construir un modelo, el modelo tendrá algunas diferencias en comparación con el modelo general, especialmente en la configuración de parámetros. Este artículo trata de explicar algo de mi comprensión de una manera relativamente popular.
Este artículo se refiere principalmente a: comprensión integral de la red LSTM y de entrada, salida, tamaño oculto y otros parámetros
LSTM y red neuronal recurrente general
Como se muestra en la siguiente figura, h[t] se entiende como el estado pasado al tiempo t, que es a corto plazo y cambia rápidamente.c[t] es exclusivo de LSTM y se entiende como memoria a largo plazo. Por el contrario, la red general es pasar este estado al siguiente estado, es decir, de h[t-1] a h[t] --- transferencia de memoria a corto plazo, y LSTM excepto h[t-1] Allí también es una transferencia de c[t] a h[t] que cambia relativamente lentamente, y este nodo se usa principalmente para almacenar información, por lo que la red general solo puede ver la información de los pocos puntos de cierre anteriores en el punto actual . puede ver la memoria de un largo período de tiempo anterior, que es la comprensión del contexto.
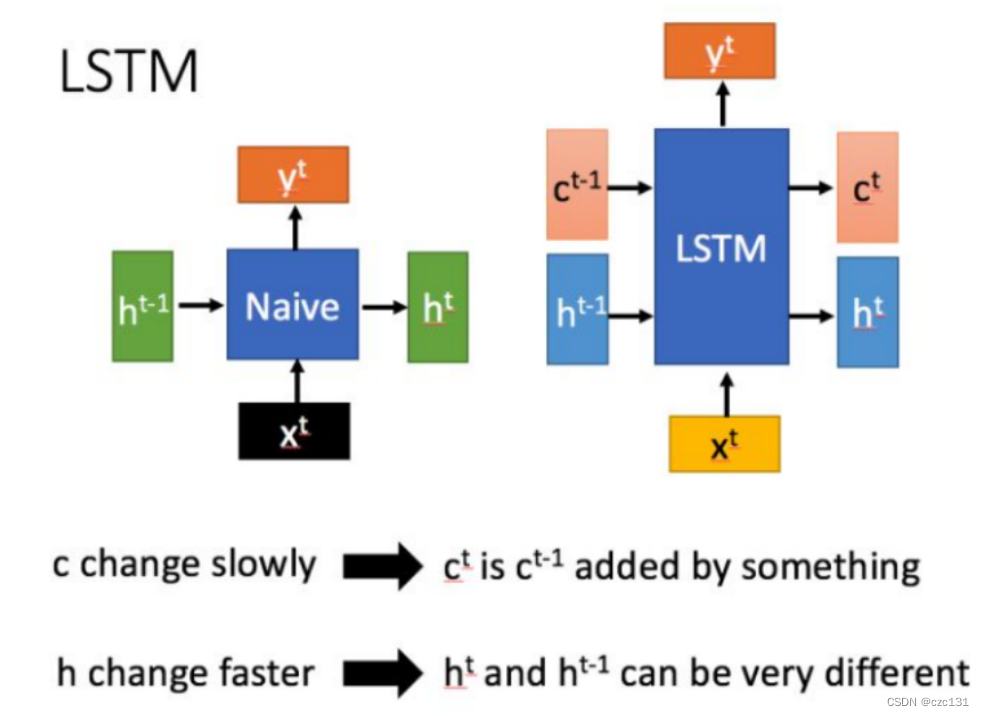
Cómo implementar la entrega
Luego, cómo realizar la memoria a corto y largo plazo, LSTM introduce el concepto de puerta, la entrada de red general x, después de algunos cambios, el resultado de salida finaliza, pero LSTM necesita realizar varios procesamientos en x.
Como se muestra en la figura a continuación, hay dos líneas horizontales que recorren la serie de tiempo. La superior es la memoria a largo plazo c, y la inferior es la memoria a corto plazo h, que representa el valor del estado de control de la puerta, ![]() que es una razón, se requiere olvidar, y σ representa la función de activación sigmoidea, después de esto, se puede obtener un número ∈ [0,1], que es la razón de olvido. La entrada x entra y se mezcla primero con la memoria a corto plazo del momento anterior , y luego pasa por tres operaciones de activación. Primero mire el primero en la parte superior izquierda, la memoria a largo plazo c ha pasado, por lo que se olvida la parte de la memoria a largo plazo; luego mire el del medio, muestra la parte que se va a olvidar en el memoria a corto plazo, y luego suba y sume con la memoria a largo plazo para formar una nueva memoria a largo plazo Memoria de tiempo; la última es la esquina inferior derecha, esta es la memoria actual a largo plazo y la memoria a corto plazo para operación de activación tanh, para que podamos obtener la nueva memoria a corto plazo actual, y luego la memoria a largo plazo y la memoria a corto plazo continúan afectando a la siguiente, formando una red recurrente.
que es una razón, se requiere olvidar, y σ representa la función de activación sigmoidea, después de esto, se puede obtener un número ∈ [0,1], que es la razón de olvido. La entrada x entra y se mezcla primero con la memoria a corto plazo del momento anterior , y luego pasa por tres operaciones de activación. Primero mire el primero en la parte superior izquierda, la memoria a largo plazo c ha pasado, por lo que se olvida la parte de la memoria a largo plazo; luego mire el del medio, muestra la parte que se va a olvidar en el memoria a corto plazo, y luego suba y sume con la memoria a largo plazo para formar una nueva memoria a largo plazo Memoria de tiempo; la última es la esquina inferior derecha, esta es la memoria actual a largo plazo y la memoria a corto plazo para operación de activación tanh, para que podamos obtener la nueva memoria a corto plazo actual, y luego la memoria a largo plazo y la memoria a corto plazo continúan afectando a la siguiente, formando una red recurrente.
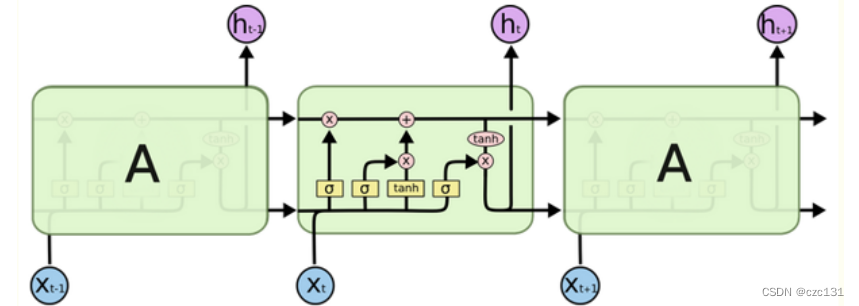
Este proceso es realmente muy vívido. Desde la perspectiva de leer un libro, un fragmento de texto que vemos es en realidad una entrada x en el momento actual. La memoria a largo plazo incluye el contenido leído anteriormente, mientras que la memoria a corto plazo es el contenido recién leído. . Cuando leemos un fragmento de contenido, primero combinaremos el contenido que acabamos de leer, que es la mezcla de x y la memoria a corto plazo del momento anterior . La puerta en la parte superior izquierda indica el olvido de la memoria a largo plazo , que es el olvido de nuestra memoria; la operación tanh en el medio es la corriente Por supuesto, es imposible recordarlos todos, así que entro en la memoria a largo plazo a través de la parte de olvido cerrada en el medio ; luego necesito combinar los la memoria a largo plazo y el contexto del contenido actual para comprender el contenido de lectura actual y generar una nueva comprensión, luego es tanh activación ; la última parte olvidada se convierte en "recién leído" en el momento siguiente. Desde un punto de vista macro, cuanto más lees el contenido, más lo olvidas, lo que también está en línea con el hecho de que cuanto más lejos está la memoria, menos afectada se ve durante el proceso de transferencia.
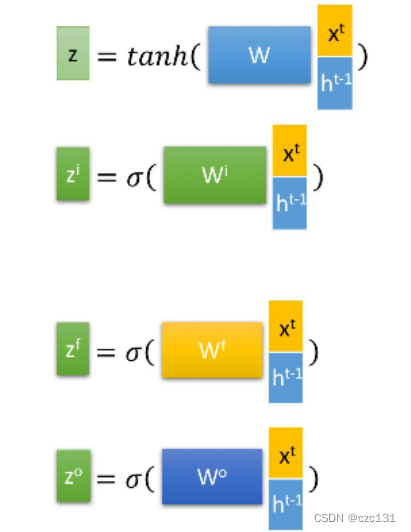
En lo que respecta a la implementación, son las siguientes operaciones, las que no se ampliarán.
La siguiente figura muestra la estructura de una red LSTM general, es decir, los cambios experimentados por una secuencia de entrada y salida, lo cual es muy útil para comprender los parámetros subyacentes. La entrada general es una de las series temporales de todos los datos, una secuencia contiene varias unidades y la distribución horizontal es similar a una oración seleccionada de un artículo, que contiene varias palabras; la distribución vertical es la profundización continua de la capa de red, es decir, la Arquitectura Neural Multicapa general de Redes. Cada caja azul es una neurona, observe que una de las neuronas recibe la influencia de corto y largo plazo de la misma capa de la secuencia anterior, y al mismo tiempo recibe la influencia de corto plazo de la capa anterior de esta secuencia , y continúa influyendo en la siguiente capa. Una capa y la secuencia de abajo (afecta directamente a la siguiente, afecta indirectamente todo lo que sigue a la siguiente). El resultado final contiene las características de salida de cada secuencia, que esencialmente registra la memoria a corto plazo de cada secuencia y finalmente las une. Y hn y cn registran la memoria a corto plazo y la memoria a largo plazo de la n-ésima secuencia.

Comprensión de parámetros de red LSTM
Ahora llega el momento de usar pytorch para construir la red LSTM. El código no es difícil de encontrar, pero a menudo es difícil entender el significado de los parámetros internos. Yo mismo no he encontrado un análisis muy satisfactorio. Permítanme analizar algunos incomprensibles en detalle desde mi perspectiva parámetros.
def __init__(self, input_size, hidden_size, num_layers, output_size, batch_size, seq_length) -> None:
super(Net, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.output_size = output_size
self.batch_size = batch_size
self.seq_length = seq_length
self.num_directions = 1 # 单向LSTM
self.lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers,
batch_first=True) # LSTM层Asumiendo que arriba se construye un modelo LSTM simple, la explicación de todos los parámetros se da a continuación.
seq_length = 3 # Paso de tiempo, puede establecerlo usted mismo
input_size = 3 # Tamaño de dimensión de entrada
num_layers = 6 # Número de capa de red
hidden_size = 12 # Tamaño de capa oculta
batch_size = 64 # Número de lote
output_size = 1 # Dimensión de salidanum_directions=1 # significa LSTM unidireccional, igual a 2 es LSTM bidireccional
input_size y output_size se entienden bien, es decir, el número de dimensiones de x e y, no necesito explicar mucho, num_directions significa el número de direcciones de LSTM, no he estudiado esto, tal vez ambas direcciones son positivas y ¿negativo?
seq_length es cuántas unidades contiene cada serie de tiempo, o cuántos datos contiene. Si es 3, entonces empaquete los datos de 3 momentos en una sola pieza cada vez, y coloque una etiqueta y correspondiente como un dato, eso es, una secuencia seq.
num_layers es el número de capas de la red, y la profundidad de la estructura general de arriba es el número de capas aquí.
El tamaño del lote indica cuántos lotes de datos se envían a la vez para el entrenamiento. Personalmente, me gusta entenderlo como el número de capas superpuestas . En redes generales, como el reconocimiento de imágenes, es para entrenar varias imágenes a la vez. , que es equivalente al tamaño de lote. Las imágenes se superponen y luego se optimizan los parámetros, lo cual es similar en LSTM, que consiste en enviar múltiples lotes de series temporales a la vez para entrenamiento .
Por último, hidden-size , hidden-size me empieza a molestar, este es el tamaño de la capa oculta hn, que es el tamaño de la memoria a corto plazo (número de columnas). Aquí hay que entenderlo en combinación con la figura anterior, cada vez que entra x dato, no entra directamente a la red, sino que se mezcla con la capa oculta, es decir, x[n] y h[n] se superponen , y la columna Los números se suman y luego se envían al entrenamiento del modelo, por lo que el número de columnas de los parámetros de peso del modelo de red real debe ser hidden_size+input_size, después de pasar por la red y formar un nuevo a corto plazo. memoria h[n+1], el número de columnas en este momento es It is hidden_size, y finalmente se mezcla con x[n+1] para formar una nueva memoria a corto plazo y propagarse hacia abajo .
Los siguientes dos tamaños de matriz de parámetros se combinan con el diagrama general para su comprensión:
(h[n], c[n])
h[n] shape:(num_layers * num_directions, batch_size, hidden_size)
c[n] shape:(num_layers * num_directions, batch_size, hidden_size)Como se indicó anteriormente, este es el tamaño específico de todo el estado de la capa oculta, que son la memoria a largo plazo y la memoria a corto plazo, que son aproximadamente iguales. Tome h[n], que es la memoria a corto plazo general de la capa n, como ejemplo. La memoria general es en realidad la colección de memoria a corto plazo en cada capa en todos los momentos de esta serie de tiempo . Combinado con el gráfico , una columna tiene num_layers capas, y cada capa tiene una salida con un tamaño de hidden_size, luego la superposición se convierte en num_layers hidden_size lengths, y cada hidden_size tiene una superposición de una capa de tamaño de lote, y el LSTM bidireccional debe ser *2.
output
output.shape: (seq_length, batch_size, hidden_size * num_directions) Mirando la salida nuevamente, combinada con el diagrama, podemos ver que la salida es el conjunto de salida de la memoria a corto plazo de cada nodo en la última capa de una serie de tiempo, que puede entenderse como el conjunto de memoria a corto plazo de cada nodo, y la longitud es el tiempo en la secuencia El número seq_length, cada momento es la superposición de las capas hidden_size, batch_size. Preste atención a la distinción, esta es solo la salida de una de las secuencias durante el proceso de entrenamiento, que es equivalente a la salida x en un conjunto de relaciones xy, no la salida final, y la salida final debe tener un mapa de características .
En general, la salida es la colección final de memoria a corto plazo en cada momento, lo que refleja las características generales de este período de secuencia de tiempo, y las capas ocultas h[n] y c[n] son las memorias de tiempo largo y corto, que reflejan las características de este momento, se utilizan a menudo como predicciones o clasificaciones.