Tomado de: gráficos detallados de árboles Huffman JAVA
El concepto :
Dado n pesos como los n nodos de hoja , una configuración de árbol binario, si la longitud de camino ponderado del árbol alcanza un mínimo, tal árbol binario se llama óptima árbol binario, también conocido como Huffman árbol (Huffman Tree). árbol de Huffman es la más corta del árbol ponderada longitud del camino, cuanto mayor sea el peso desde el nodo raíz más cerca.
Su construcción es simple, seleccionar secuencialmente el peso más pequeño en la parte inferior en el nodo del árbol, el nuevo nodo constituirá un mínimo de dos conexiones, debe observarse que los pesos que constituyen el nodo nuevo debe ser igual a dos valores de nodo correctos y entonces poner en el nuevo nodo que necesitamos para constituir un nodo del árbol sigue para ordenar árbol de Huffman construida tales nodos que toda la información se almacena son nodos hoja sucesivamente.
Ejemplos:
Hay una serie de caracteres: aaaaaaaaaabbbbbaaaaaccccccccddddddfff
El primer paso, vamos a contar el número de veces que aparece cada personaje, llamado el peso del personaje. a: 15, b: 5, c: 8, d: 6, f: 3.
El segundo paso, para encontrar allí un peso mínimo de dos caracteres, B5 y F3, la construcción de nodo.
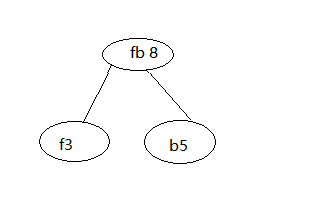
F3 luego se retira y b5, ahora a15, c8, d6, FB8.
Un tercer paso, el segundo paso se repite hasta que sólo un nodo construido.
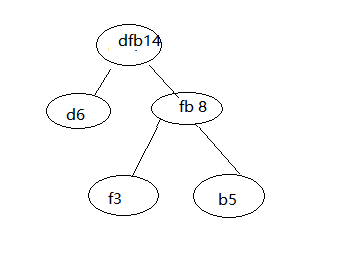
Es dfb14, A15, c8.
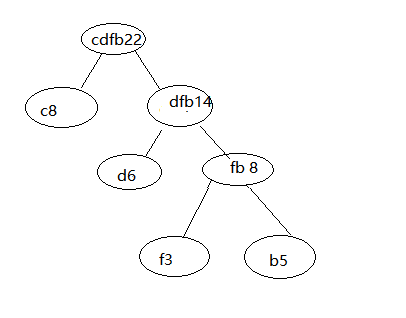
Por último,
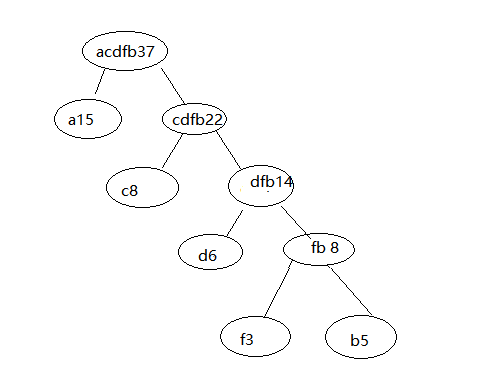
ok, por lo que el árbol de Huffman se construye completa.
( Nota: el árbol original se genera aquí para empezar a construir desde la derecha, como se muestra en la dieta normal, pero debe empezar a construir desde la izquierda y desde la parte inferior, el código Java se da a continuación, los resultados de la salida final es seguir el principio. de recorrido)
package com.gxu.dawnlab_algorithm7;
import java.util.ArrayList;
import com.gxu.dawnlab_algorithm3.PrintBinaryTree.Node;
/**
* 哈夫曼数的实现
* @author junbin
*
* 2019年7月11日
*/
public class Huffman {
public static class Node{
public String data;// 节点的数据
public int count;// 节点的权值
public Node lChild;
public Node rChild;
public Node() {
}
public Node(String data, int count) {
this.data = data;
this.count = count;
}
public Node(int count, Node lChild, Node rChild) {
this.count = count;
this.lChild = lChild;
this.rChild = rChild;
}
public Node(String data, int count, Node lChild, Node rChild) {
this.data = data;
this.count = count;
this.lChild = lChild;
this.rChild = rChild;
}
}
private String str;// 最初用于压缩的字符串
private String newStr = "";// 哈夫曼编码连接成的字符串
private Node root;// 哈夫曼二叉树的根节点
private boolean flag;// 最新的字符是否已经存在的标签
private ArrayList<String> charList;// 存储不同字符的队列:相同字符存在同一位置
private ArrayList<Node> NodeList;// 存储节点的队列
/**
* 构建哈夫曼树
*
* @param str
*/
public void creatHfmTree(String str) {
this.str = str;
charList = new ArrayList<String>();
NodeList = new ArrayList<Node>();
// 1.统计字符串中字符以及字符的出现次数
// 基本思想是将一段无序的字符串如ababccdebed放到charList里,分别为aa,bbb,cc,dd,ee
// 并且列表中字符串的长度就是对应的权值
for (int i = 0; i < str.length(); i++) {
char ch = str.charAt(i); // 从给定的字符串中取出字符
flag = true;
for (int j = 0; j < charList.size(); j++) {
if (charList.get(j).charAt(0) == ch) {// 如果找到了同一字符
String s = charList.get(j) + ch;
charList.set(j, s);
flag = false;
break;
}
}
if (flag) {
charList.add(charList.size(), ch + "");
}
}
// 2.根据第一步的结构,创建节点
for (int i = 0; i < charList.size(); i++) {
String data = charList.get(i).charAt(0) + ""; // 获取charList中每段字符串的首个字符
int count = charList.get(i).length(); // 列表中字符串的长度就是对应的权值
Node node = new Node(data, count); // 创建节点对象
NodeList.add(i, node); // 加入到节点队列
}
// 3.对节点权值升序排序
Sort(NodeList);
while (NodeList.size() > 1) {// 当节点数目大于一时
// 4.取出权值最小的两个节点,生成一个新的父节点
// 5.删除权值最小的两个节点,将父节点存放到列表中
Node left = NodeList.remove(0);
Node right = NodeList.remove(0);
int parentWeight = left.count + right.count;// 父节点权值等于子节点权值之和
Node parent = new Node(parentWeight, left, right);
NodeList.add(0, parent); // 将父节点置于首位
}
// 6.重复第四五步,就是那个while循环
// 7.将最后的一个节点赋给根节点
root = NodeList.get(0);
output(root);
}
/**
* 升序排序
*
* @param nodelist
*/
public void Sort(ArrayList<Node> nodelist) {
for (int i = 0; i < nodelist.size() - 1; i++) {
for (int j = i + 1; j < nodelist.size(); j++) {
Node temp;
if (nodelist.get(i).count > nodelist.get(j).count) {
temp = nodelist.get(i);
nodelist.set(i, nodelist.get(j));
nodelist.set(j, temp);
}
}
}
}
/**
* 先序遍历
*
* @param node
* 节点
*/
public void output(Node head) {
if(head == null){
return;
}
System.out.print(head.count + " ");
output(head.lChild);
output(head.rChild);
}
public void output() {
output(root);
}
public static void main(String[] args) {
Huffman huff = new Huffman();//创建哈弗曼对象
huff.creatHfmTree("aaaaaaaaaabbbbbaaaaaccccccccddddddfff");//构造树
}
}
Preorden de salida del resultado de recorrido es: 3722148356815.
