Reproducido: base cero Datawhale entrada de la función de minería de datos funciona -Task3
Proyecto de Código Abierto Dirección: https://github.com/datawhalechina/team-learning/tree/master/ minería de datos prácticos (auto usado pronóstico de precio)
gracias Datawhale!
En tercer lugar, las características del objetivo del proyecto
Consejo: Esta sección es cero Fundamentos de la minería de datos característica Task3 obras de la parte con usted para entender las diversas características de la ingeniería y métodos de análisis, damos la bienvenida a más intercambios siguen.
cero de entrada basada en los datos de la minería - Pronóstico del precio de la transacción de automóviles usados: título del juego
3.1 Características objetivo del proyecto
-
Para más funciones de análisis, y el procesamiento de datos
-
análisis completo de las características del proyecto, y algunos gráficos o texto y datos de resumen para ponche.
3.2 Introducción
Las características comunes del proyecto incluyen:
- Manejo de excepciones:
- valores atípicos Análisis de eliminar mediante diagrama de caja (o 3-Sigma);
- conversión de Box-Cox (procesamiento de distribución sesgada);
- corte de la cola larga apagado;
- Caracterizado normalizado / estandarizada:
- Estandarizada (convertido a la distribución normal estándar);
- Normalización (cambio a la comprensión [0,1]);
- Para una distribución de ley de potencia, puede ser fórmula empleado: \ (.. Log (\ + X FRAC 1 {{}} 1 + mediana) \)
- Los puntos de datos barril:
- por división de frecuencia como la bañera;
- puntos equidistantes barril;
- Best-KS kit de partes (similar al uso del binario índice de Gini);
- barril Chi-cuadrado;
- los valores que faltan:
- No existe ningún tratamiento (modelo de árbol de otra XGBoost similar);
- Eliminar (demasiada falta de datos);
- finalización de interpolación, incluyendo la mediana promedio / a congruentes matriz de modo / / predictivo modelado / imputación / comprimido de detección para complemento / suplemento múltiple;
- Bin, un cuadro de valores que faltan;
- Cuenta con la construcción:
- En donde las estadísticas de configuración, notificación de tasa de recuento suma, desviación estándar;
- Características de tiempo, incluyendo el tiempo relativo y tiempo absoluto, días de fiesta, fines de semana y similares;
- La información geográfica, incluyendo bin, distribuidos método de codificación;
- transformación no lineal, incluyendo log / metros cuadrados / raíz y similares;
- Las combinaciones de características, en el que la cruz;
- Ojos del espectador, el sabio ve sabiduría.
- La selección de características
- Filtración (filtro): dato para selección primero, y luego la formación y el aprendizaje, un método común tiene Alivio / varianza de selección de envío / coeficiente de correlación / método de prueba de chi-cuadrado / información mutua;
- Envolvente (envoltorio): directamente en el tiempo se utilizará el rendimiento del estudiante como un subconjunto característica criterio de evaluación, el LVM métodos comunes (Las Vegas Envoltura);
- Embedded (incrustación): combinación de filtrado y envolvente, de manera automática el aprendizaje es el proceso de selección de características de formación, una regresión lazo común;
- reducción de dimensionalidad
- PCA / LDA / ICA;
- La selección de características es también una reducción de la dimensión.
Ejemplo de código 3.3
3.3.0 Importación de datos
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from operator import itemgetter
%matplotlib inline
train = pd.read_csv('train.csv', sep=' ')
test = pd.read_csv('testA.csv', sep=' ')
print(train.shape)
print(test.shape)
(150000, 30)
(50000, 30)
train.head()
| nombre | RegDate | modelo | marca | tipo de cuerpo | tipo de combustible | caja de cambios | poder | kilómetro | notRepairedDamage | ... | v_5 | v_6 | v_7 | v_8 | v_9 | v_10 | v_11 | v_12 | v_13 | v_14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 736 | 20040402 | 30.0 | 6 | 1.0 | 0.0 | 0.0 | 60 | 12.5 | 0.0 | ... | 0.235676 | 0.101988 | 0.129549 | 0.022816 | 0.097462 | -2.881803 | 2.804097 | -2.420821 | 0.795292 | 0.914762 |
| 1 | 2262 | 20030301 | 40.0 | 1 | 2.0 | 0.0 | 0.0 | 0 | 15.0 | - | ... | 0.264777 | 0.121004 | 0.135731 | 0.026597 | 0.020582 | -4.900482 | 2.096338 | -1.030483 | -1.722674 | 0.245522 |
| 2 | 14874 | 20040403 | 115,0 | 15 | 1.0 | 0.0 | 0.0 | 163 | 12.5 | 0.0 | ... | 0.251410 | 0.114912 | 0.165147 | 0.062173 | 0.027075 | -4.846749 | 1.803559 | 1.565330 | -0.832687 | -0.229963 |
| 3 | 71865 | 19960908 | 109,0 | 10 | 0.0 | 0.0 | 1.0 | 193 | 15.0 | 0.0 | ... | 0.274293 | 0.110300 | 0.121964 | 0.033395 | 0.000000 | -4.509599 | 1.285940 | -0.501868 | -2.438353 | -0.478699 |
| 4 | 111080 | 20120103 | 110,0 | 5 | 1.0 | 0.0 | 0.0 | 68 | 5.0 | 0.0 | ... | 0.228036 | 0.073205 | 0.091880 | 0.078819 | 0.121534 | -1.896240 | 0.910783 | 0.931110 | 2.834518 | 1.923482 |
5 filas x 30 columnas
train.columns
Index(['name', 'regDate', 'model', 'brand', 'bodyType', 'fuelType', 'gearbox',
'power', 'kilometer', 'notRepairedDamage', 'regionCode', 'seller',
'offerType', 'creatDate', 'price', 'v_0', 'v_1', 'v_2', 'v_3', 'v_4',
'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13',
'v_14'],
dtype='object')
test.columns
Index(['name', 'regDate', 'model', 'brand', 'bodyType', 'fuelType', 'gearbox',
'power', 'kilometer', 'notRepairedDamage', 'regionCode', 'seller',
'offerType', 'creatDate', 'price', 'v_0', 'v_1', 'v_2', 'v_3', 'v_4',
'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13',
'v_14'],
dtype='object')
3.3.1 Retire los valores atípicos
# 这里我包装了一个异常值处理的代码,可以随便调用。
def outliers_proc(data, col_name, scale=3):
"""
用于清洗异常值,默认用 box_plot(scale=3)进行清洗
:param data: 接收 pandas 数据格式
:param col_name: pandas 列名
:param scale: 尺度
:return:
"""
def box_plot_outliers(data_ser, box_scale):
"""
利用箱线图去除异常值
:param data_ser: 接收 pandas.Series 数据格式
:param box_scale: 箱线图尺度,
:return:
"""
iqr = box_scale * (data_ser.quantile(0.75) - data_ser.quantile(0.25))
val_low = data_ser.quantile(0.25) - iqr
val_up = data_ser.quantile(0.75) + iqr
rule_low = (data_ser < val_low)
rule_up = (data_ser > val_up)
return (rule_low, rule_up), (val_low, val_up)
data_n = data.copy()
data_series = data_n[col_name]
rule, value = box_plot_outliers(data_series, box_scale=scale)
index = np.arange(data_series.shape[0])[rule[0] | rule[1]]
print("Delete number is: {}".format(len(index)))
data_n = data_n.drop(index)
data_n.reset_index(drop=True, inplace=True)
print("Now column number is: {}".format(data_n.shape[0]))
index_low = np.arange(data_series.shape[0])[rule[0]]
outliers = data_series.iloc[index_low]
print("Description of data less than the lower bound is:")
print(pd.Series(outliers).describe())
index_up = np.arange(data_series.shape[0])[rule[1]]
outliers = data_series.iloc[index_up]
print("Description of data larger than the upper bound is:")
print(pd.Series(outliers).describe())
fig, ax = plt.subplots(1, 2, figsize=(10, 7))
sns.boxplot(y=data[col_name], data=data, palette="Set1", ax=ax[0])
sns.boxplot(y=data_n[col_name], data=data_n, palette="Set1", ax=ax[1])
return data_n
# 我们可以删掉一些异常数据,以 power 为例。
# 这里删不删同学可以自行判断
# 但是要注意 test 的数据不能删 = = 不能掩耳盗铃是不是
train = outliers_proc(train, 'power', scale=3)
Delete number is: 963
Now column number is: 149037
Description of data less than the lower bound is:
count 0.0
mean NaN
std NaN
min NaN
25% NaN
50% NaN
75% NaN
max NaN
Name: power, dtype: float64
Description of data larger than the upper bound is:
count 963.000000
mean 846.836968
std 1929.418081
min 376.000000
25% 400.000000
50% 436.000000
75% 514.000000
max 19312.000000
Name: power, dtype: float64

3.3.2 construcción característica
# 训练集和测试集放在一起,方便构造特征
train['train']=1
test['train']=0
data = pd.concat([train, test], ignore_index=True, sort=False)
# 使用时间:data['creatDate'] - data['regDate'],反应汽车使用时间,一般来说价格与使用时间成反比
# 不过要注意,数据里有时间出错的格式,所以我们需要 errors='coerce'
data['used_time'] = (pd.to_datetime(data['creatDate'], format='%Y%m%d', errors='coerce') -
pd.to_datetime(data['regDate'], format='%Y%m%d', errors='coerce')).dt.days
# 看一下空数据,有 15k 个样本的时间是有问题的,我们可以选择删除,也可以选择放着。
# 但是这里不建议删除,因为删除缺失数据占总样本量过大,7.5%
# 我们可以先放着,因为如果我们 XGBoost 之类的决策树,其本身就能处理缺失值,所以可以不用管;
data['used_time'].isnull().sum()
15072
# 从邮编中提取城市信息,因为是德国的数据,所以参考德国的邮编,相当于加入了先验知识
data['city'] = data['regionCode'].apply(lambda x : str(x)[:-3])
# 计算某品牌的销售统计量,同学们还可以计算其他特征的统计量
# 这里要以 train 的数据计算统计量
train_gb = train.groupby("brand")
all_info = {}
for kind, kind_data in train_gb:
info = {}
kind_data = kind_data[kind_data['price'] > 0]
info['brand_amount'] = len(kind_data)
info['brand_price_max'] = kind_data.price.max()
info['brand_price_median'] = kind_data.price.median()
info['brand_price_min'] = kind_data.price.min()
info['brand_price_sum'] = kind_data.price.sum()
info['brand_price_std'] = kind_data.price.std()
info['brand_price_average'] = round(kind_data.price.sum() / (len(kind_data) + 1), 2)
all_info[kind] = info
brand_fe = pd.DataFrame(all_info).T.reset_index().rename(columns={"index": "brand"})
data = data.merge(brand_fe, how='left', on='brand')
# 数据分桶 以 power 为例
# 这时候我们的缺失值也进桶了,
# 为什么要做数据分桶呢,原因有很多,= =
# 1. 离散后稀疏向量内积乘法运算速度更快,计算结果也方便存储,容易扩展;
# 2. 离散后的特征对异常值更具鲁棒性,如 age>30 为 1 否则为 0,对于年龄为 200 的也不会对模型造成很大的干扰;
# 3. LR 属于广义线性模型,表达能力有限,经过离散化后,每个变量有单独的权重,这相当于引入了非线性,能够提升模型的表达能力,加大拟合;
# 4. 离散后特征可以进行特征交叉,提升表达能力,由 M+N 个变量编程 M*N 个变量,进一步引入非线形,提升了表达能力;
# 5. 特征离散后模型更稳定,如用户年龄区间,不会因为用户年龄长了一岁就变化
# 当然还有很多原因,LightGBM 在改进 XGBoost 时就增加了数据分桶,增强了模型的泛化性
bin = [i*10 for i in range(31)]
data['power_bin'] = pd.cut(data['power'], bin, labels=False)
data[['power_bin', 'power']].head()
| power_bin | poder | |
|---|---|---|
| 0 | 5.0 | 60 |
| 1 | NaN | 0 |
| 2 | 16.0 | 163 |
| 3 | 19.0 | 193 |
| 4 | 6.0 | 68 |
# 利用好了,就可以删掉原始数据了
data = data.drop(['creatDate', 'regDate', 'regionCode'], axis=1)
print(data.shape)
data.columns
(199037, 38)
Index(['name', 'model', 'brand', 'bodyType', 'fuelType', 'gearbox', 'power',
'kilometer', 'notRepairedDamage', 'seller', 'offerType', 'price', 'v_0',
'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10',
'v_11', 'v_12', 'v_13', 'v_14', 'train', 'used_time', 'city',
'brand_amount', 'brand_price_average', 'brand_price_max',
'brand_price_median', 'brand_price_min', 'brand_price_std',
'brand_price_sum', 'power_bin'],
dtype='object')
# 目前的数据其实已经可以给树模型使用了,所以我们导出一下
data.to_csv('data_for_tree.csv', index=0)
# 我们可以再构造一份特征给 LR NN 之类的模型用
# 之所以分开构造是因为,不同模型对数据集的要求不同
# 我们看下数据分布:
data['power'].plot.hist()
<matplotlib.axes._subplots.AxesSubplot at 0x12904e5c0>
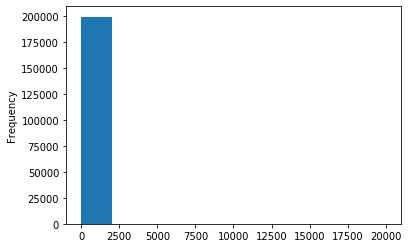
# 我们刚刚已经对 train 进行异常值处理了,但是现在还有这么奇怪的分布是因为 test 中的 power 异常值,
# 所以我们其实刚刚 train 中的 power 异常值不删为好,可以用长尾分布截断来代替
train['power'].plot.hist()
<matplotlib.axes._subplots.AxesSubplot at 0x12de6bba8>

# 我们对其取 log,在做归一化
from sklearn import preprocessing
min_max_scaler = preprocessing.MinMaxScaler()
data['power'] = np.log(data['power'] + 1)
data['power'] = ((data['power'] - np.min(data['power'])) / (np.max(data['power']) - np.min(data['power'])))
data['power'].plot.hist()
<matplotlib.axes._subplots.AxesSubplot at 0x129ad5dd8>
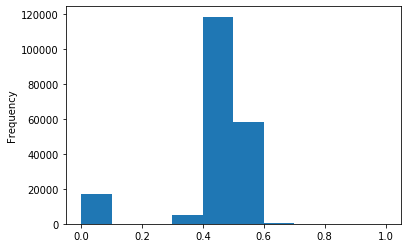
# km 的比较正常,应该是已经做过分桶了
data['kilometer'].plot.hist()
<matplotlib.axes._subplots.AxesSubplot at 0x12de58cf8>
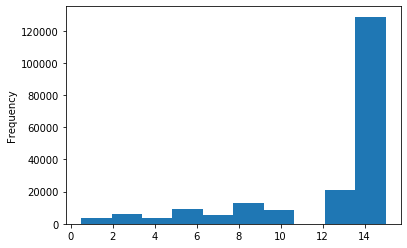
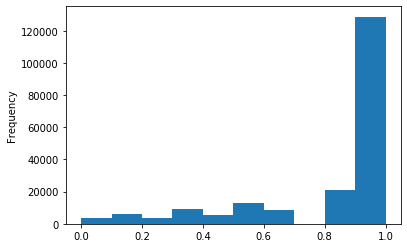
# 所以我们可以直接做归一化
data['kilometer'] = ((data['kilometer'] - np.min(data['kilometer'])) /
(np.max(data['kilometer']) - np.min(data['kilometer'])))
data['kilometer'].plot.hist()
<matplotlib.axes._subplots.AxesSubplot at 0x128b4fd30>
# 除此之外 还有我们刚刚构造的统计量特征:
# 'brand_amount', 'brand_price_average', 'brand_price_max',
# 'brand_price_median', 'brand_price_min', 'brand_price_std',
# 'brand_price_sum'
# 这里不再一一举例分析了,直接做变换,
def max_min(x):
return (x - np.min(x)) / (np.max(x) - np.min(x))
data['brand_amount'] = ((data['brand_amount'] - np.min(data['brand_amount'])) /
(np.max(data['brand_amount']) - np.min(data['brand_amount'])))
data['brand_price_average'] = ((data['brand_price_average'] - np.min(data['brand_price_average'])) /
(np.max(data['brand_price_average']) - np.min(data['brand_price_average'])))
data['brand_price_max'] = ((data['brand_price_max'] - np.min(data['brand_price_max'])) /
(np.max(data['brand_price_max']) - np.min(data['brand_price_max'])))
data['brand_price_median'] = ((data['brand_price_median'] - np.min(data['brand_price_median'])) /
(np.max(data['brand_price_median']) - np.min(data['brand_price_median'])))
data['brand_price_min'] = ((data['brand_price_min'] - np.min(data['brand_price_min'])) /
(np.max(data['brand_price_min']) - np.min(data['brand_price_min'])))
data['brand_price_std'] = ((data['brand_price_std'] - np.min(data['brand_price_std'])) /
(np.max(data['brand_price_std']) - np.min(data['brand_price_std'])))
data['brand_price_sum'] = ((data['brand_price_sum'] - np.min(data['brand_price_sum'])) /
(np.max(data['brand_price_sum']) - np.min(data['brand_price_sum'])))
# 对类别特征进行 OneEncoder
data = pd.get_dummies(data, columns=['model', 'brand', 'bodyType', 'fuelType',
'gearbox', 'notRepairedDamage', 'power_bin'])
print(data.shape)
data.columns
(199037, 369)
Index(['name', 'power', 'kilometer', 'seller', 'offerType', 'price', 'v_0',
'v_1', 'v_2', 'v_3',
...
'power_bin_20.0', 'power_bin_21.0', 'power_bin_22.0', 'power_bin_23.0',
'power_bin_24.0', 'power_bin_25.0', 'power_bin_26.0', 'power_bin_27.0',
'power_bin_28.0', 'power_bin_29.0'],
dtype='object', length=369)
# 这份数据可以给 LR 用
data.to_csv('data_for_lr.csv', index=0)
3.3.3 selección de características
1) filtrar
# 相关性分析
print(data['power'].corr(data['price'], method='spearman'))
print(data['kilometer'].corr(data['price'], method='spearman'))
print(data['brand_amount'].corr(data['price'], method='spearman'))
print(data['brand_price_average'].corr(data['price'], method='spearman'))
print(data['brand_price_max'].corr(data['price'], method='spearman'))
print(data['brand_price_median'].corr(data['price'], method='spearman'))
0.5737373458520139
-0.4093147076627742
0.0579639618400197
0.38587089498185884
0.26142364388130207
0.3891431767902722
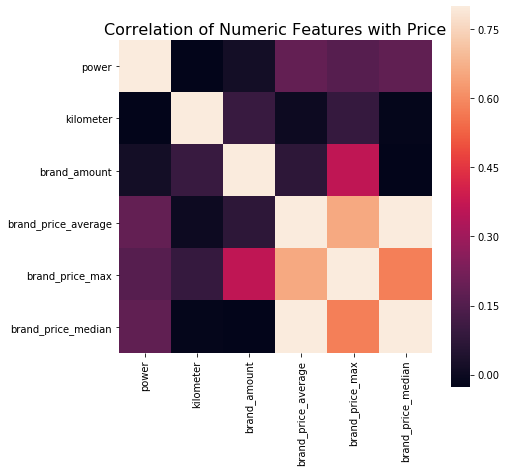
# 当然也可以直接看图
data_numeric = data[['power', 'kilometer', 'brand_amount', 'brand_price_average',
'brand_price_max', 'brand_price_median']]
correlation = data_numeric.corr()
f , ax = plt.subplots(figsize = (7, 7))
plt.title('Correlation of Numeric Features with Price',y=1,size=16)
sns.heatmap(correlation,square = True, vmax=0.8)
<matplotlib.axes._subplots.AxesSubplot at 0x129059470>
2) envolvente
!pip install mlxtend
# k_feature 太大会很难跑,没服务器,所以提前 interrupt 了
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
from sklearn.linear_model import LinearRegression
sfs = SFS(LinearRegression(),
k_features=10,
forward=True,
floating=False,
scoring = 'r2',
cv = 0)
x = data.drop(['price'], axis=1)
x = x.fillna(0)
y = data['price']
sfs.fit(x, y)
sfs.k_feature_names_
STOPPING EARLY DUE TO KEYBOARD INTERRUPT...
('powerPS_ten',
'city',
'brand_price_std',
'vehicleType_andere',
'model_145',
'model_601',
'fuelType_andere',
'notRepairedDamage_ja')
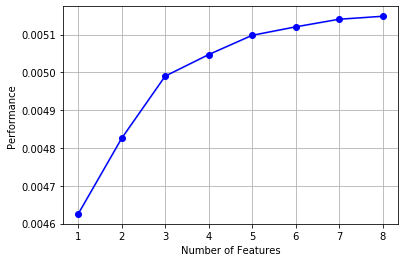
# 画出来,可以看到边际效益
from mlxtend.plotting import plot_sequential_feature_selection as plot_sfs
import matplotlib.pyplot as plt
fig1 = plot_sfs(sfs.get_metric_dict(), kind='std_dev')
plt.grid()
plt.show()
/Users/chenze/anaconda3/lib/python3.7/site-packages/numpy/core/_methods.py:140: RuntimeWarning: Degrees of freedom <= 0 for slice
keepdims=keepdims)
/Users/chenze/anaconda3/lib/python3.7/site-packages/numpy/core/_methods.py:132: RuntimeWarning: invalid value encountered in double_scalars
ret = ret.dtype.type(ret / rcount)
3) Embedded
# 下一章介绍,Lasso 回归和决策树可以完成嵌入式特征选择
# 大部分情况下都是用嵌入式做特征筛选
3.4 Experiencia
proyecto característica es más pieza crucial del juego, sobre todo del juego tradicional, nuestro modelo puede ser similar, el efecto de ajuste de parámetros provocado un aumento es muy limitado, pero las características de calidad del proyecto a menudo determina la final clasificaciones y logros.
El propósito principal del proyecto o característica que convierte los datos para caracterizar mejor los problemas potenciales, mejorando así el rendimiento de la máquina de aprendizaje. Por ejemplo, el procesamiento de valor anormal para eliminar el ruido, para imputar los valores que faltan pueden añadirse conocimiento previo.
En el que las características de configuración son también parte del proyecto, su propósito es mejorar los datos de expresión.
Algunos rasgos característicos del juego es anónima, no sabemos que se traducen en correlación directa con cada uno de otras características, entonces el procesamiento solamente basado puramente en función, por lo que algunas operaciones tales como embalaje, GroupBy, agg algunas características tales como las estadísticas, además de se puede caracterizarse además en el registro, exp, etc. transformación, o en el que una pluralidad de cuatro operaciones (como se describe anteriormente, se calcula utilizando nuestra larga), y la combinación polinomio cribado. Debido al anonimato de las propiedades realidad limitar un montón de características para el procesamiento, por supuesto, a veces con NN para extraer algunas características logrará buenos resultados inesperados.
Conocer la naturaleza del significado de obras de características (no anónimas), especialmente en el juego de tipo industrial, vamos a construir un procesamiento más significativo basado en características de la señal, la extracción de dominio de la frecuencia, la abundancia, la asimetría, etc., que se caracteriza por una combinación del fondo la construcción, de la misma manera un sistema de recomendación, diversos tipos de estadísticas CTR, cada estadísticas de tiempo, además de estadísticas y así sucesivamente atributos de usuario, una característica tan a menudo tiene que construir un análisis en profundidad de la lógica de negocio detrás o principios físicos, que pueden ser más buen hallazgo mágico.
Por supuesto, de hecho, se caracteriza por la ingeniería y el modelo en conjunto, que es la razón para la LR NN hecho en parte porque barriles y características de la normalización, y para el efecto del tratamiento y la importancia de características y otras características a menudo tienen que ser verificada por el modelo.
En general, el proyecto se caracteriza por una entrada simple, pero muy bueno en una cosa muy difícil.
En donde Engineering Task 3- FIN.
--- Por: azerí
PS:复旦大学计算机研究生
知乎:阿泽 https://www.zhihu.com/people/is-aze(主要面向初学者的知识整理)
Sobre Datawhale:
Datawhale es un enfoque en la ciencia de datos de código abierto y el campo de la IA, reúne a muchas áreas de las empresas e instituciones de buenos aprendices, un grupo de la polimerización del espíritu de código abierto y el espíritu de los miembros del equipo de exploración conocidos. Datawhale a "para el aprendiz, aprendiz y crecer juntos" para la visión, animar a mostrarse verdaderamente, la apertura y la tolerancia, la confianza mutua, el valor y el coraje de juego de prueba y error. Mientras tanto Datawhale con la filosofía de código abierto para explorar CMS de código abierto, de código abierto y el programa de aprendizaje de código abierto, lo que permite la formación del personal, ayudar a la gente a crecer, a las personas a construir, las personas con el conocimiento, las personas con negocios y personas vinculadas con el futuro.
El plan de formación de minería de datos, el tema va a compartir conocimientos en Tianchi, los datos pueden estar preocupados por Datawhale:
