Federados de aprendizaje conferencia sobre los dos días antes de escuchar CCF YOCSEF a cabo, sintiéndose muy productiva, abrir un registro de post-it.
En general, las cosas no muy maduro como una nueva área alrededor Federados de aprendizaje que hacer es todavía muy abajo al sistema / red / seguridad, en la que AI / RL HCI incluso puede ser algo fuera.
Part1, borde federal retos y perspectivas de aprendizaje basados en computación
Este es un proyecto de cooperación maestro PolyU Guo Song y Ali. estudio Federal es equivalente al original en la nube para hacer ml distribuidos movidos al dispositivo de borde. Con las fuerzas de recuento dispositivo de borde mejoradas, Guo general es muy optimista acerca de este campo.

Guo se describen algunas de las siguientes cuestiones hacer:
1. heterogénea
Lectura de Google hacia el diseño sistema federado de aprendizaje a los estudiantes de papel ensayo saben FL es una necesidad de sincronizar múltiples nodos (el modelo de polimerización) proceso, pero la cooperación entre múltiples nodos es bastante difícil. En los dos puntos siguientes:
- isómero de comunicación: el ancho de banda limitado de los diferentes nodos, y los isómeros (2G / 4G / 5G / WiFi / ...).
- Heterogéneos calculado: diversas fuerzas diferentes nodos de operador.
Debido a que existe una heterogeneidad éstos, habrá el nodo más lento a todo el entrenamiento más largo y reducir la eficiencia de la situación general (sólo podemos esperar a que se complete la sincronización). Una solución es hacer que la idea de la informática y las comunicaciones de sincronización de solapamiento (es decir, mientras la computación y las comunicaciones). No se ajusta dinámicamente de acuerdo con el tamaño del lote y de la red de potencia condiciones calculados.
Vale la pena mencionar que la superposición de las ideas en SOSP19 PipeDream también tiene aplicaciones.
2. Estadísticas heterogéneos
Los datos sobre los diferentes nodos se distribuirá de forma desigual en una función diferente (Non-IID), la cantidad de datos de los diferentes usuarios / calidad de los datos es también muy inconsistente, lo que resulta en más horas de la formación, sino también a reducir la precisión. Pero el análisis no se refiere a este tema tiene una teoría.
En donde los datos se refleja en la calidad de la definición: y la distribución general es consistente / etiqueta sobre la precisión de la materia. Una medida simple de esta parte es ver la cantidad de pérdida de datos puede hacer caer.
Algunas soluciones incluyen: en general y para la gran brecha entre nodos, reduciendo su contribución global (también controlar el tamaño de lote ...). Un trabajo se ajusta dinámicamente para cada tamaño de lote de usuario método de aprendizaje de refuerzo.
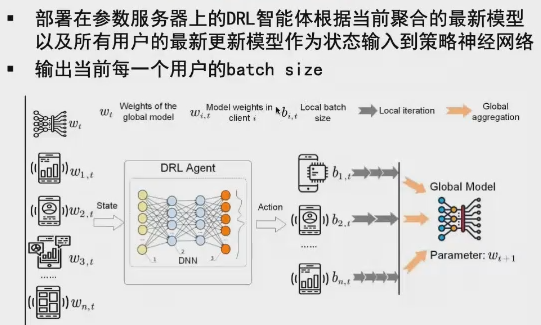
3. seguro y fiable
- ataques nodo malicioso: por ejemplo, una configuración de datos nodo malicioso (por ejemplo, contra la muestra), lo que resulta en el modelo no es fiable.
- problemas de privacidad: proceso de formación y nodos de servidor necesitan gradiente de cambio, pero este proceso es probable que los datos originales se puede agrietar.
Para el primer problema, en los ml distribuidos convencionales, el gradiente se puede encontrar desde el servidor al malicioso, entonces lanzar el nodo directamente. Sin embargo, hay otro problema en el entorno de dispositivo de borde: Para reducir la comunicación modelo de sobrecarga, a veces cuantizado con ideas similares, transmitiendo solamente los parámetros más importantes (dimensión reducida). En este entorno, entonces queremos asegurar un poco más difícil. Una solución es el gradiente diferencial de adelgazamiento.

Por último, Guo Mirando hacia el futuro para hacer un poco de tema:
1. compresión de modelo y de la colocación: qué tan grande modelo en recursos limitados para dispositivo de borde.
Este método que se puede usar incluyen: 1) los ml límite común + arco. Modelos de cuantificación y la poda . 2) La división modelo adaptativo y hardware (arquitectura de hardware, el grado de paralelismo, el consumo de energía, el cálculo de diferencia de velocidad). 3) estudiar la migración y el modelo de reutilización. Métricas para centrarse en incluyen precisión, velocidad y consumo de energía.
2. Optimización de la comunicación. Vale la pena mencionar que la estructura jerárquica se puede dividir en una pluralidad de capas, cada capa por separado de sincronización. Este sistema de almacenamiento de idea y que a menudo mencionar un poco como de nivel múltiple.
3. Secure Computing. No sé que esto no tome la ...
4. incentivos. Para asegurar que los diferentes usuarios de los beneficios de contribución / calidad de los datos y de usuario están justo, un poco el significado de descarga BT (aportación del usuario calculado). Hay mencionado anteriormente no IID.
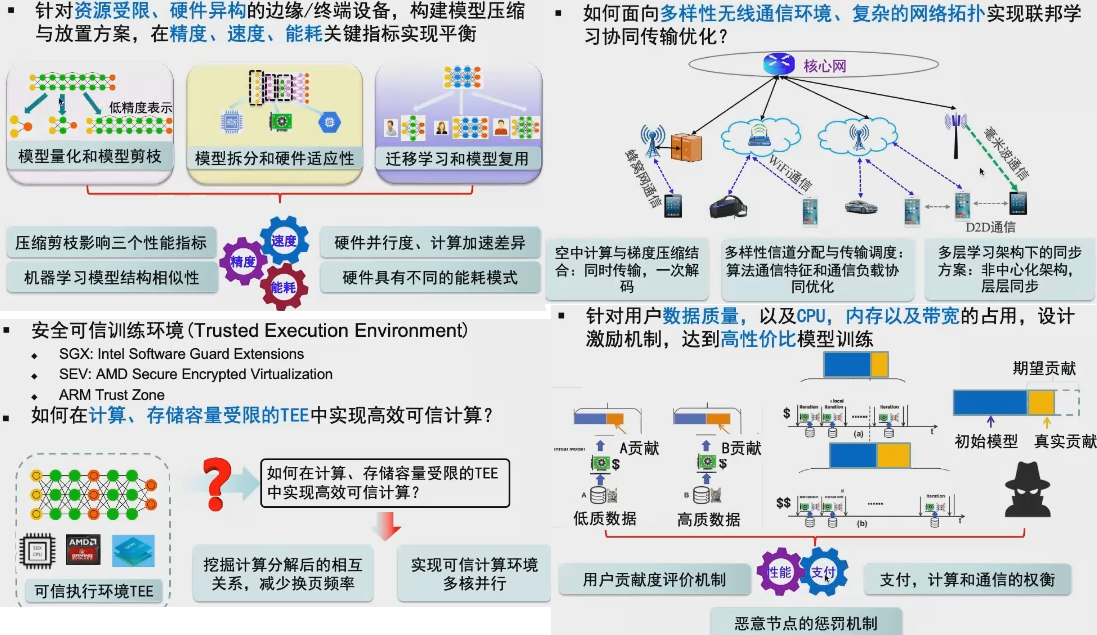
Parte 2, escenario de aterrizaje de aprendizaje federal en el sector industrial [0:53:00]
Éstos son los tres de presentación de la industria.
FL sistema de una necesidad de centrarse en dos temas de tipo industrial: 1) Distribuido ML .. Este entendimiento ha sido relativamente más. 2) Seguridad de intercambio de parámetros. El intercambio de los parámetros del modelo a modo de necesidades informáticas seguras para asegurar que no hay fugas de información de parámetros (industria en general usar un puerto específico de cifrado homomorphic / VPN además se consigue dos). Por otra parte, hay que asegurarse de que los resultados no pueden ser anti-lanzado los datos originales. Generalmente necesita involucrar a la siguiente:
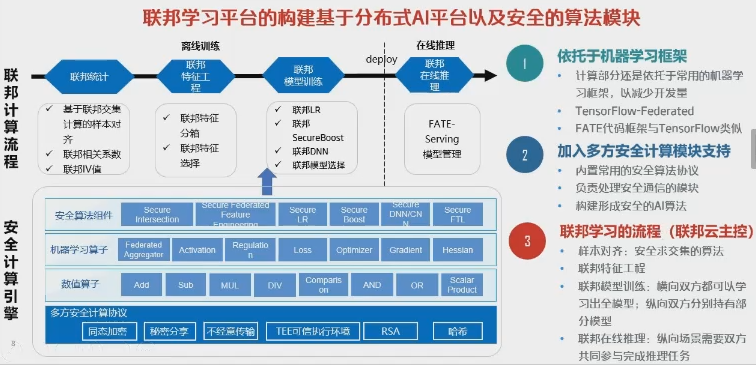
Parte 3, la preservación de privacidad-aprendizaje automático federados [02:09:00]
Aquí se va a implicar algún criptografía, la privacidad diferencial del contenido.
A pesar de que el intercambio de datos FL no va a salir, pero hay un cierto riesgo en la seguridad:
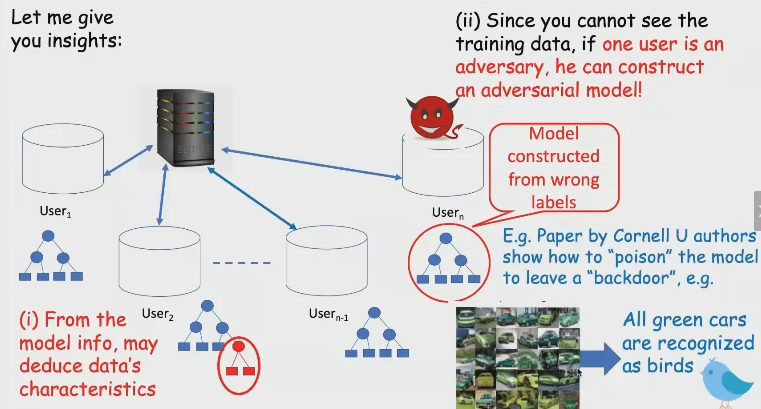
- usuario1 y usuario2 el modelo local, hay algunas diferencias, se pueden deducir algunas características tanto de los datos originales
- muestra la confrontación
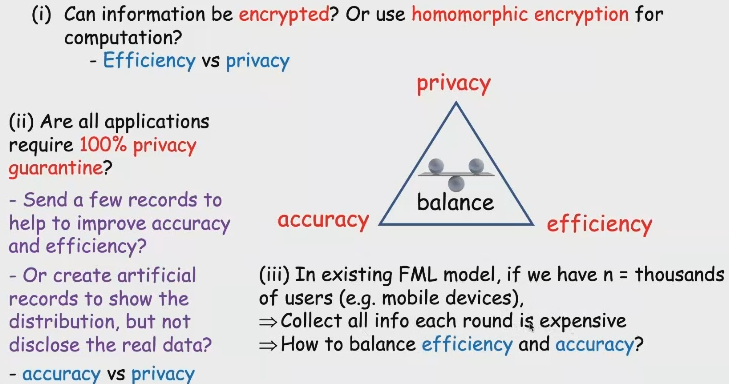
las necesidades del comercio-off de seguridad FL por hacer en las siguientes tres áreas: privacidad / precisión / eficiencia. De acuerdo con este escenario es para establecer la industria, mientras
Parte 4, incentivos federales aprendizaje [02:34:00]
Como se ha mencionado anteriormente en este tema, NTU en el maestro Han hecho este punto un estudio más en profundidad.
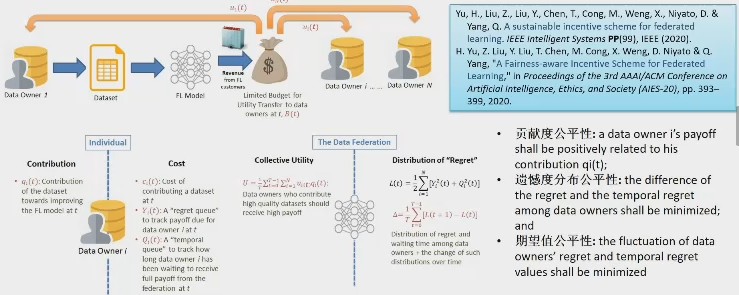
1. Evaluación de la contribución de cada nodo - evaluación de impacto
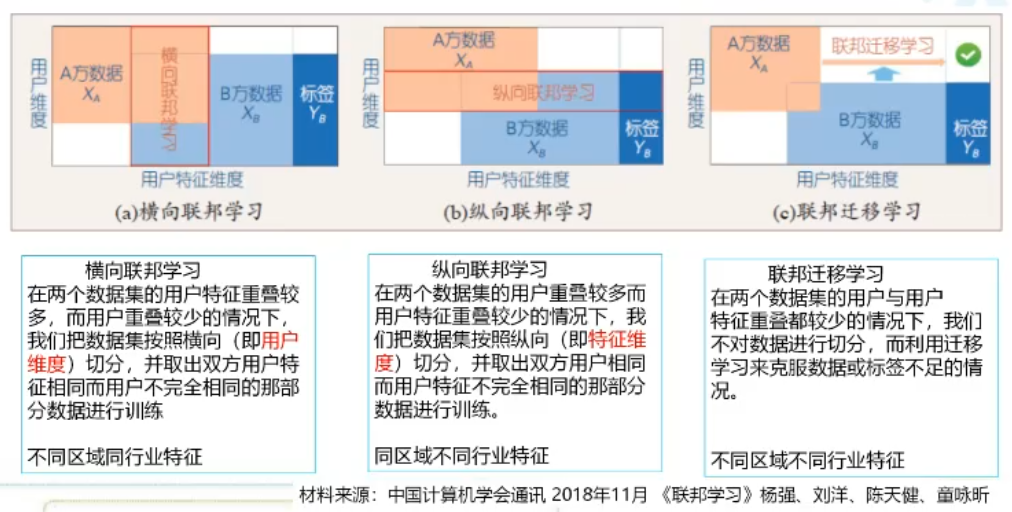
La primera escena es un estudio transversal en el federal, lo que significa que cada uno de los nodos participantes fondo / función son los mismos (por ejemplo, todos los hospitales), necesidad de centrarse en las diferencias de calidad de datos en distintos nodos. Un método es : el servidor puede ser presentada en un conjunto de datos relativamente de alta calidad como punto de referencia, cuando todos los nodos cliente envían su modelo local para sincronización de tiempo, se están ejecutando en el primer punto de referencia local para cada modelo, para obtener B [i ]. Después de la polimerización modelo Global después de nuevo modelo para el cliente, cada cliente y a continuación, ejecutar de nuevo con el nuevo modelo de datos locales, para obtener L [i]. B [i] y L [i] de cada entropía cruzada puede ser usado para evaluar cómo la calidad de los datos del UE.
El segundo escenario es un estudio longitudinal federal, a continuación, cada nodo será la diferencia relativamente grande (función no es lo mismo, e incluso algunos simplemente sin etiqueta), pero todavía quieren un modelo de tren junto con todos juntos. Por ejemplo, utilizar los datos de un usuario diferente para aprender la historia de crédito del usuario. El trabajo es una evaluación conjunta de la importancia de las características de cada participante y la importancia (que cuentan con más útil) con escasa Grupo Lasso.
Otro problema es contener nodos maliciosos a través de incentivos, puede hacer referencia a esta revisión .
Otro problema es eliminar la influencia de diferente secuencia implicada en el cálculo de la contribución. Un dispositivo como calidad de los datos no es muy buena, pero para participar en la época anterior, para mejorar el modelo global de la más obvia (como el 40% -> 80%); entonces B también está implicado en el equipo, una mejor calidad de los datos, aunque B, pero margen de mejora no tiene un modelo global (por ejemplo 80% -> 85%), que podría tener una contribución a una falsa y B en este caso. Solución es utilizar un Shapley de datos para alterar el orden de adición de los diferentes nodos de un método, una onda se calcula en cada orden diferente, pero esta complejidad es demasiado alto. Un refinamiento es ayudar a una blockchain cálculo.
2. ¿Cómo diseñar una distribución justa de los programas de beneficios interpretables
Tema1: tecnologías de mejorar la privacidad (cifrado homomorphic, computación segura multipartidista, la diferencia de privacidad) existente puede dirigirse directamente a las necesidades del nuevo estudio federal de privacidad de los datos de usuario? [03:00:00]
Tema2: indicadores existentes (precisión, potencia de cálculo, almacenamiento, transporte) y los nuevos requisitos de privacidad se pueden equilibrar de manera efectiva el estudio federal? [03:32:00]