table of Contents
Data Mining Getting Started tutorial series (four five) of Apriori algorithm
Apriori (a priori) algorithm association rules one of the classic study of algorithms used to find out the data centralized data collection occurs frequently. If you have read the previous blog, it is not thought of this with Data Mining Getting Started tutorial series (a) affinity analysis of this blog is very similar? Yes, indeed very similar, but in this blog, we will be more in-depth analysis of how to find reliable and effective affinity. In the next blog and Apriori algorithm used to analyze the affinity of the movie. This is to introduce Apriori algorithm processes.
Frequent criteria (item set) data
This in Data Mining Getting Started tutorial series (a) affinity analysis of this blog have mentioned, but here re detailed talk about.
Ru determine whether the data is a frequently? According to our ideas, the more data must be centralized in the number of occurrences of data, representing the more frequent occurrence of data.
It is noted that: the data here may be a data or may be a plurality of data (itemsets).
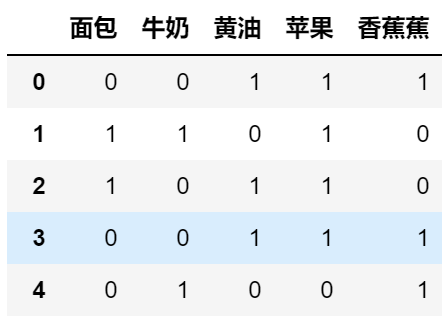
The picture shows this with the following example, this chart each column represents whether the goods are purchased (1 for the purchase, 0 for no), each row represents a single transaction record:
The evaluation criteria used by the support , confidence , and lift three:
Support (support):
Support is the number of data in the data set appears (also may be the number proportion of the total data set), or the probability of occurrence of the data set:
The following formula to be described proportion:
\ [\ & If the begin {} is a Split data X, it is a support: \\ & support (X) = P (X) = \ frac {num (X) } {num (ALL)} \\ & If the data is a set of data items (X, Y), the support is: \\ & support (X, Y ) = P (X, Y) = \ frac {num ( XY)} {num (ALL) } \\ & If the data is a set of data items (X, Y, Z), the support is: \\ & support (X, Y , Z) = P (X, Y, Z) = \ frac {num ( XYZ)} {num (ALL)} \\ & (X, Y, Z represents the number of X, Y, Z simultaneous occurrence) \ end {split} \]
in the above transactions for example:
Let's seek (butter, apple) of support:
(Butter, apple) in the first 0,2,3pass appeared, a total of five data, \ (Support (butter, apple) = \ frac {3} { 5} = 0.6 \)
In general, it does not necessarily support high data frequently, but the data certainly support the frequent high
Confidence (confidence):
Confidence represents the fulfillment of the rules of accuracy, that is, the probability of a data appear, the other data appears, that is, the conditional probability. (Purchase for example, is already purchased under the Y, X probability of purchase) is the following formula:
\ [\} & provided the begin {Split analysis data X, Y, X of the confidence Y is: \\ & confidence (X \ Leftarrow Y) = P (X | Y) = \ frac {P (XY)} {P (Y)} \\ & provided analysis data X, Y, Z, Y and Z is X confidence level: \\ & confidence (X \ Leftarrow
YZ) = P (X | YZ) = \ frac {P (XYZ)} {P (YZ)} \\ \ end {split} \] or in (butter Apple) as an example, the calculation of the confidence apple butter: \ (confidence (butter \ Leftarrow apple) = \ {FRAC. 3} = {0.75}. 4 \) .
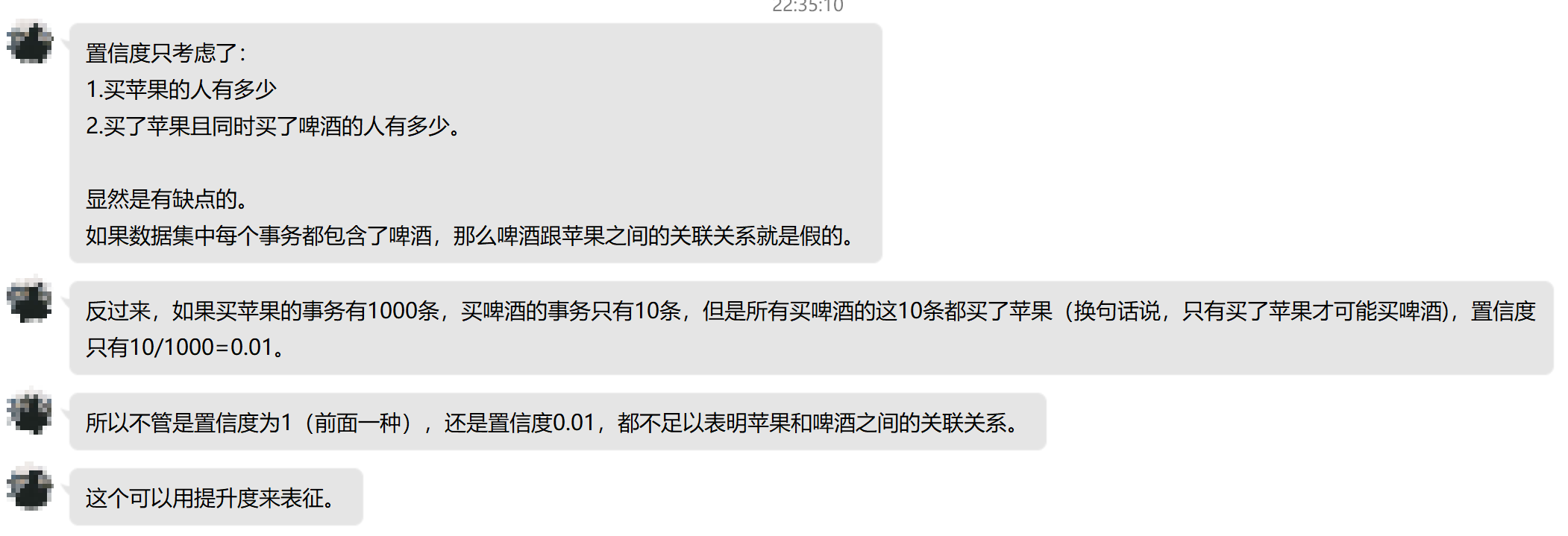
But confidence has a drawback that it may distort the importance associated. Because it reflects the degree Y popular. If the popularity of X is also high, then the confidence will be great. Here is some data mining Jiang Shaohua teacher's why we need to use 提升度the words:
Lift (Lift):
Lift expressed under conditions including Y, and containing both the probability of X, and taking into account the probability of X, the following formula:
\ [\ the begin {Equation} \ the begin {the aligned} Lift (X \ Leftarrow Y) & = \ FRAC { support (X, Y)} { support (X) \ times support (Y)} \ \ & = \ frac {P (X, Y)} {P (X) \ times P (Y)} \\ & = \ frac {P (X | Y)
} {P (X)} \\ & = \ frac {confidenc (X \ Leftarrow Y)} {P (X)} \ end {aligned} \ end {equation} \] lifting degree, if \ (Lift (X \ Leftarrow Y ) = 1 \) are independent of each other represent X, Y, not associated (as \ (P (X-| the Y) = P (X-) \) ), if the \ (Lift (X \ Leftarrow Y) > 1 \) indicates \ (X \ Leftarrow Y \) indicates \ (X \ Leftarrow Y \) is effective in strongly correlated (probably later X in the case of purchase of Y); If \ (Lift (X \ Leftarrow Y ) <1 \) indicates \ (X \ Leftarrow Y \) indicates \ (X \ Leftarrow Y \) is invalid strong association.
In general, how do we judge the use of the lift when the frequency of a data set of data.
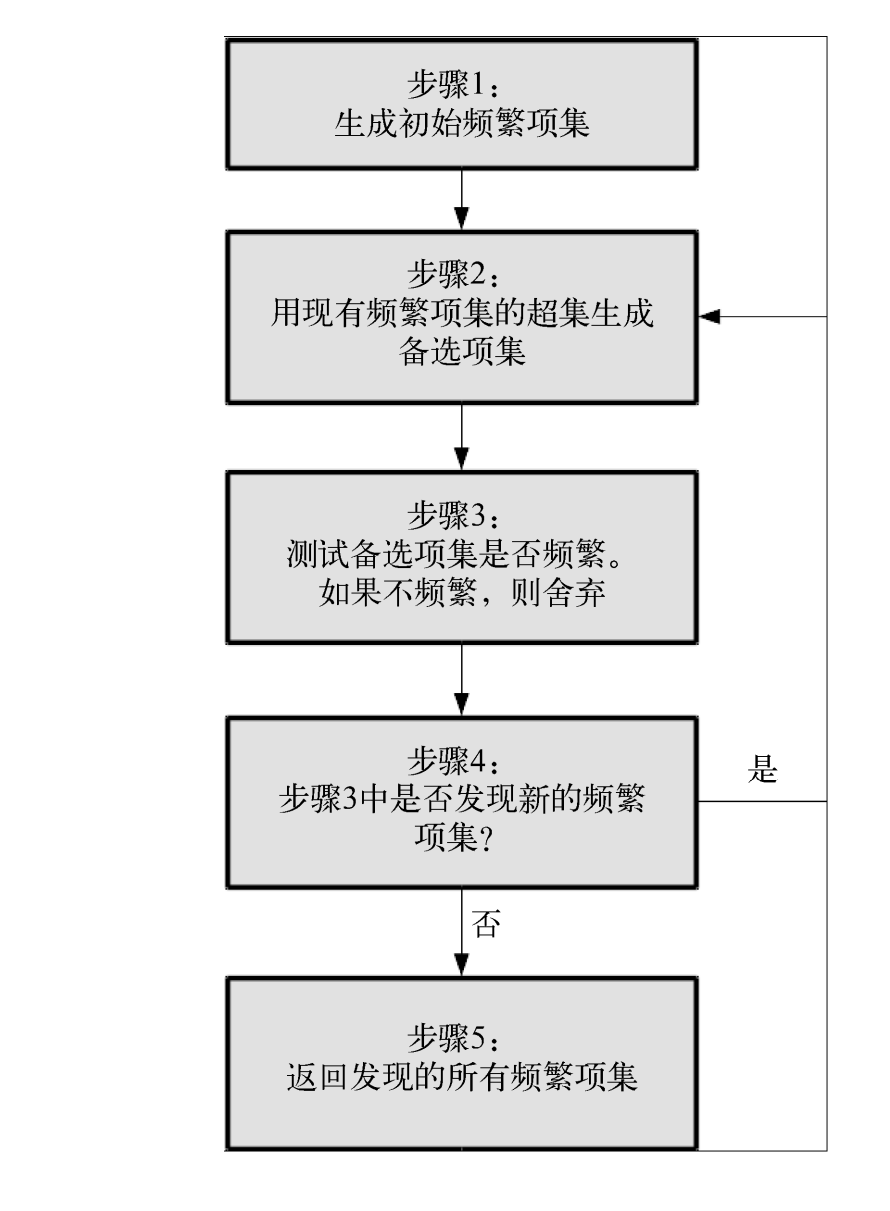
Apriori algorithm flow
Having criteria, then we talk about the process algorithm (from Ref. 1).
Apriori algorithm goal is to find the largest collection of K frequent items. There are two meanings, first of all, we need to find support in line with the frequent set standard (confidence or lift) is. But such frequent sets there may be many. The second meaning is what we want to find the largest number of frequent set. For example, we found frequent sets AB and ABE consistent with support, then we will abandon AB, retaining only ABE, two frequent because AB is set, and three ABE is frequently set.
The flowchart of the algorithm is as follows (FIG from "Data mining the Python entry and Practice"):
Here is a specific example to introduce (Figure source does not know where they come from, many blog are using), this example is the support as a criterion in the figure \ (C_n \) on behalf of the alternatives set , on behalf of L is a set of options after being cut off, \ (Min \ support = 50 \% \) represents the minimum standard of support (greater than it said frequently).
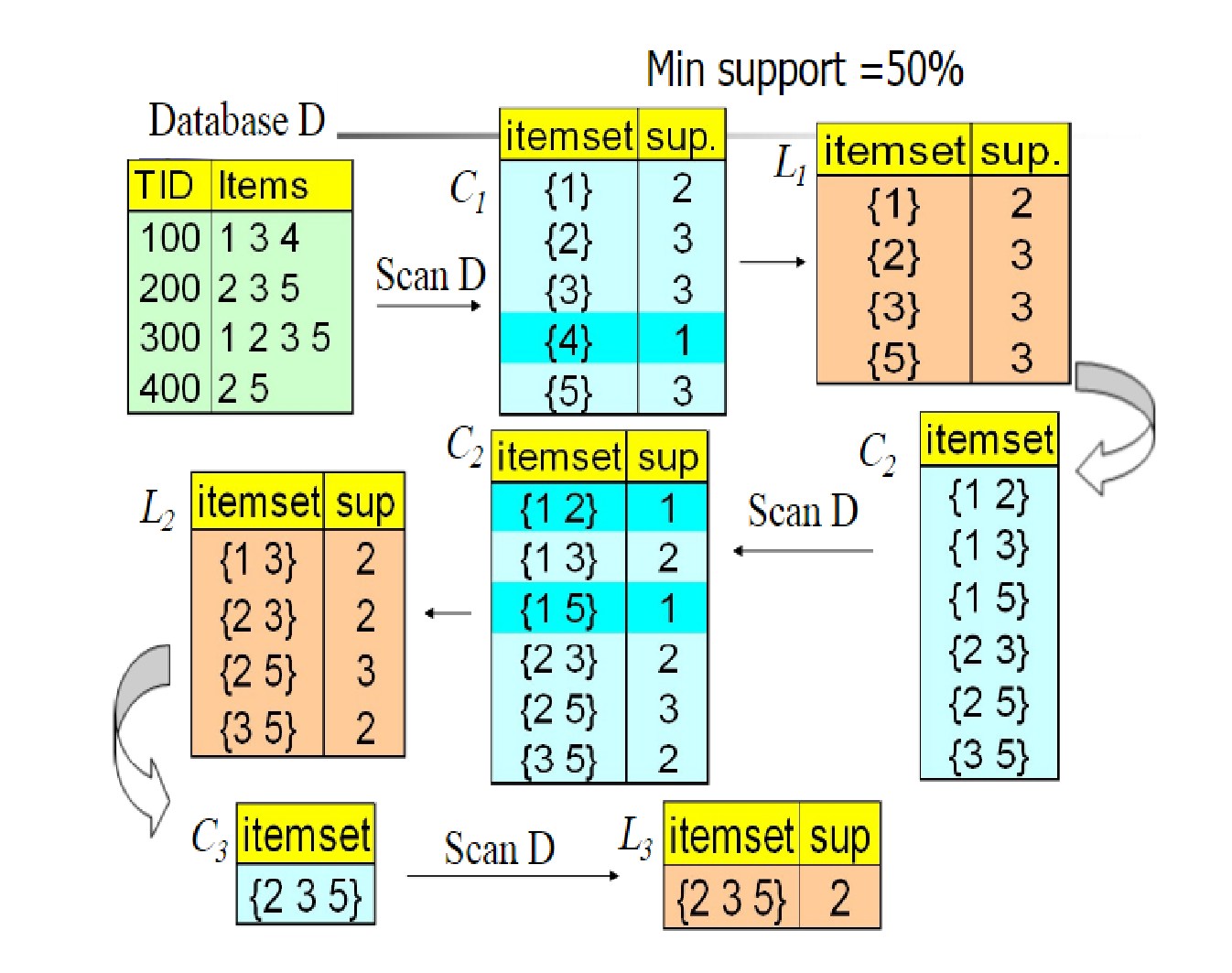
This example is still full of vivid images, it is easy to understand look. Here's a simple explanation:
First we have a set of data D, then generates a data item \ (K = 1 \) of the alternatives set \ (C_l \) , then removed \ (support_n <Min \ support \ ) data items to obtain \ (L_1 \) , then generates a data item \ (K = 2 \) a set of alternatives \ (C_2 \) , then removed \ (support_n <Min \ support \ ) data items. Recursively until no new frequent item found.
end
Overall, Apriori algorithm is not difficult, the process is also very simple algorithm, and its core is how to build an effective evaluation criteria, support? confidence? Lift? or others? But it also has some drawbacks: each recursive need to generate a lot of alternatives set, if the data set is large, then how to do? Duplicate scan data set ......
In the next blog post, I will describe how to use the Apriori algorithm movie data sets for analysis, and then find out the correlation between.
reference
- Apriori algorithm theory summary
- Association Rules and the Apriori Algorithm: A Tutorial
- "Python data mining entry and practice"
- Data mining Jiang Shaohua teacher