Please indicate the source when reprinting. The content citation and thanks will be given at the end of the article!
1. A brief introduction to association rules
Association rules reflect the interdependence and correlation between a thing and other things. If there is a certain association between two or more things, then one thing can be predicted by other things. . Association rules are an important technique in data mining, which are used to mine the correlation between valuable data items from a large amount of data.
Association rules were first proposed by Agrawal, lmielinski and Swami at the SIGMOD conference in 1993.
The most classic example of association rule mining is the story of Wal-Mart's beer and diapers. By analyzing the supermarket shopping basket data, that is, the relationship between different items in the shopping basket, the customer's shopping habits are analyzed. I often tell my husband to buy diapers for the children after get off work. 30%-40% of my husbands also buy their favorite beer. The supermarket sells diapers and beer together to increase sales. With this discovery, the supermarket adjusted its shelf setup to sell diapers and beer next to each other, which greatly increased sales.
2. Common cases
The example of association rule mining for supermarket shopping baskets is described earlier. Using Apriori to mine data for frequent itemsets and generate association rules is a very useful technology. Our well-known examples are:
(1) Wal-Mart Supermarket Diapers and beer
in the supermarket (2) Milk and bread in the supermarket
(3) Baidu Wenku recommends related documents
(4) Taobao recommends related books
(5) Medical recommends possible treatment combinations
(6) Banks recommend related businesses
These are business intelligence and Application of Association Rules in Real Life
3. 3 Metrics of Association Rules
Support: indicates the statistical significance of the rule

Confidence: Describes the strength of the rule (minimum and maximum confidence levels are set by the company)

There are other metrics such as lift/interest, but the two presented above are more commonly used!
4. Introduction to Apriori Algorithm
Our goal is to find all the rules with high enough support and confidence, and since sales databases are typically very large, we want to find them in just a few database scans. So here an efficient algorithm, called the Apriori algorithm (Agrawal et al. 1996), is proposed to do the job. Apriori algorithm is an influential algorithm for mining frequent itemsets of Boolean association rules. Frequent itemsets can be mined through the connection and pruning of the algorithm.
The algorithm is divided into two steps:
(1) Find frequent itemsets, that is, find itemsets with sufficient support;
Here is the concept of frequent itemsets:
Frequent itemsets: If the occurrence frequency of the itemsets is greater than or equal to the minimum support count threshold, it is called frequent itemsets, and the set of frequent K-itemsets is usually denoted as Lk
The following figure details the process of finding frequent itemsets:
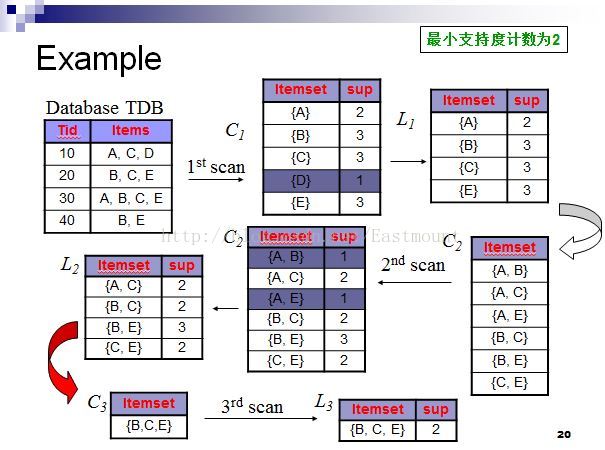
Specific analysis results:
the first scan: C1 is counted for each candidate product. Since the candidate {D} support count is 1<the minimum support count 2, the frequent 1-item set L1 of {D} is deleted;
the second Secondary scan: Generate candidate C2 from L1 and count the candidates to get C2, compare the candidate support count with the minimum support count 2 to get the frequent 2-item set L2;
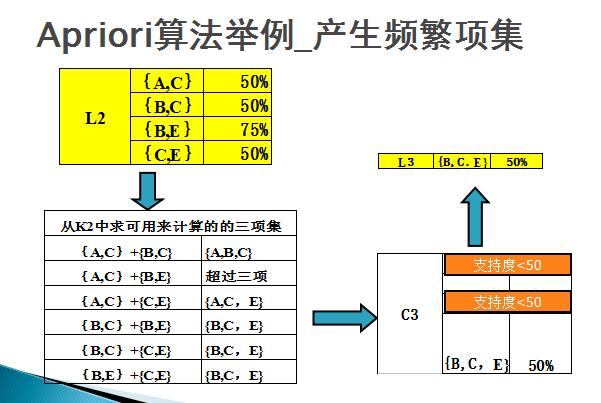
the third scan: Use the Apriori algorithm to connect and prune L2 to generate The process of candidate 3-item set C3 is as follows:
1. Connection:
C3=L2 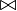 (connection) L2={{A,C},{B,C},{B,E},{C,E}} {{A, C},{B,C},{B,E},{C,E}}={{A,B,C},{A,C,E},{B,C,E}}
(connection) L2={{A,C},{B,C},{B,E},{C,E}} {{A, C},{B,C},{B,E},{C,E}}={{A,B,C},{A,C,E},{B,C,E}}
2. Cut Branch:
2-item subsets {A,B},{A,C} and {B,C} of {A,B,C}, where {A,B} is not a 2-item subset L2 and therefore not frequent, Removed from C3;
2-item subsets {A,C},{A,E} and {C,E} of {A,C,E}, where {A,E} is not a 2-item subset L2 and therefore not Frequent, removed from C3;
2-item subsets {B,C},{B,E} and {C,E} of {B,C,E}, all of which 2-item subsets are elements of L2 , reserved in C3.
After the Apriori algorithm connects and prunes L2, the set of candidate 3-item sets is C3={B,C,E}. When counting the candidate products, since it is equal to the minimum support count of 2, the frequent 3-item set is obtained. L3, and because there is only one 4-item set, C4 is an empty set, and the algorithm terminates.
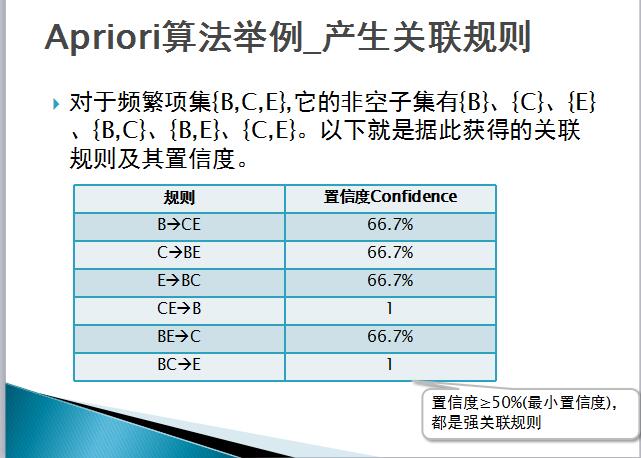
(2) Convert frequent itemsets into rules with sufficient confidence by dividing frequent itemsets into two subsets as antecedents and consequences respectively;
Strong association rule: if rule R: X=>Y satisfies support(X=>Y)>=supmin (minimum support, which is used to measure the minimum importance that the rule needs to satisfy) and confidence(X=>Y)>= confmin (minimum confidence, which indicates the minimum reliability that an association rule needs to satisfy) is called an association rule X=>Y as a strong association rule, otherwise, an association rule X=>Y is called a weak association rule.
Example: Existing transaction records of five commodities A, B, C, D, and E, find all frequent itemsets, assuming that the minimum support degree is >=50%, and the minimum confidence degree is >=50%.
For the association rule R: A=>B, then:
support (suppport): is the ratio of the number of transactions containing both A and B to the number of all transactions in the transaction set.
Support(A=>B)=P(A∪B)=count(A∪B)/|D|
confidence: It is the ratio of the number of transactions containing A and B to the number of transactions containing A.
Confidence(A=>B)=P(B|A)=support(A∪B)/support(A)
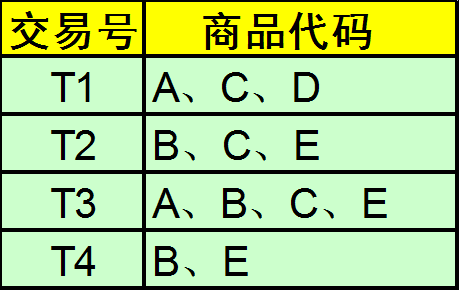
The calculation process is as follows. When K=1, the itemset {A} appears twice in T1 and T3, and there are 4 transactions in total, so the support is 2/4=50%, which is calculated sequentially. The itemset {D} appears in T1, and its support is 1/4=25%, which is less than the minimum support of 50%, so it is removed and L1 is obtained.
Then, the itemsets in L1 are combined in pairs, and their support degrees are calculated separately. The itemset {A, B} appears once in T3, and its support degree = 1/4 = 25%, which is less than the minimum support degree of 50%. Therefore, if it is removed, L2 itemsets are obtained in the same way.
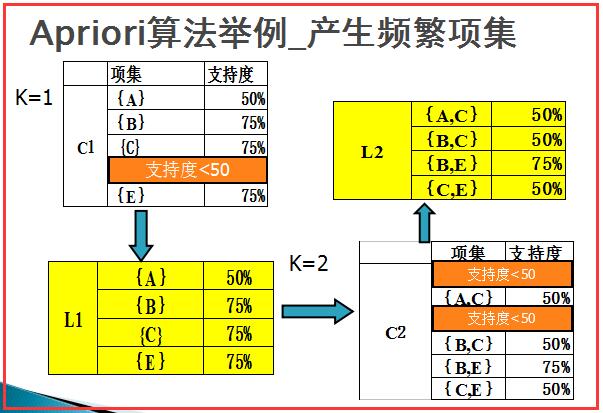
Then, as shown in the figure below, the itemsets in L2 are combined, and those with more than three items are filtered, and finally the L3 itemsets {B, C, E} are calculated.
Finally, the confidence level is calculated, as shown in the following figure.
Disadvantages of Apriori algorithm: need to scan the data table multiple times. If the frequent set contains at most 10 items, then the transaction data table needs to be scanned 10 times, which requires a large I/O load. At the same time, a large number of frequent sets are generated. If there are 100 items, the number of candidate items may be generated.
Therefore: Jiawei Han et al. proposed an association rule mining algorithm FP_growth based on FP-tree in 2000. It adopts the strategy of "divide and conquer" and compresses the database that provides frequent itemsets into a frequent pattern tree (FP-tree). .
A diagram is recommended to analyze the process of association rules in detail:
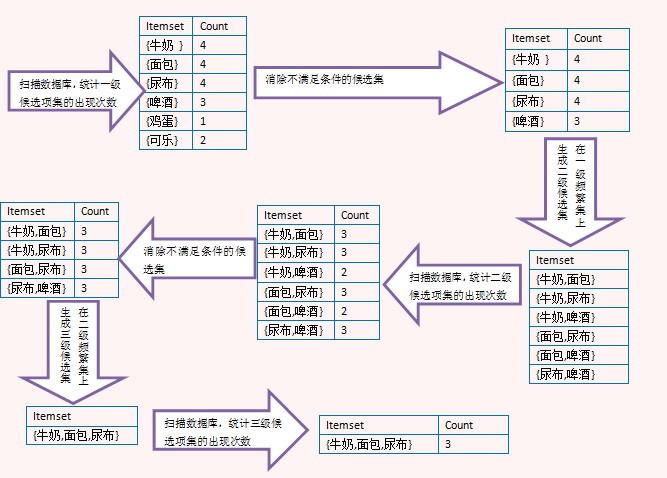
References of the original author:
[1] Gao Ming. Research and application of association rule mining algorithm [D]. Shandong Normal University. 2006
[2] Li Yanwei. Research on data mining method based on association rules [D]. Jiangnan University. 2011
[ 3] Xiao Jincheng, Lin Ziyu, Mao Chao. Application of Association Rules in Retail Business [J]. Computer Engineering. 2004, 30(3): 189-190.
[4] Qin Liangxi, Shi Zhongzhi. Review of Association Rules Research [J] ]. Journal of Guangxi University. 2005,30(4):310-317.
[5]Chen Zhibo, Han Hui, Wang Jianxin, Sun Qiao, Nie Gengqing. Data Warehouse and Data Mining [M]. Beijing: Tsinghua University Press. 2009.
[6] Shen Liangzhong. Research on C# Implementation of Apriori Algorithm in Association Rules [J]. Computer Knowledge and Technology. 2009,5(13):3501 -3504.
[7] Zhao Weidong. Business Intelligence (Second Edition) [M]. Beijing: Tsinghua University Press. 2011.
5. Apriori algorithm code implementation (temporarily use the code at the reference address, and the personal writing code will be updated later)
# -*- coding: utf-8 -*-
"""
Created on Mon Nov 28 03:29:51 2016
地址:http://blog.csdn.net/u010454729/article/details/49078505
@author: 参考CSDN u010454729
"""
# coding=utf-8
def loadDataSet():
return [[1,3,4],[2,3,5],[1,2,3,5],[2,5]]
def createC1(dataSet): #构建所有候选项集的集合
C1 = []
for transaction in dataSet:
for item in transaction:
if not [item] in C1:
C1.append([item]) #C1添加的是列表,对于每一项进行添加,{1},{3},{4},{2},{5}
C1.sort()
return map(frozenset, C1) #使用frozenset,被“冰冻”的集合,为后续建立字典key-value使用。
def scanD(D,Ck,minSupport): #由候选项集生成符合最小支持度的项集L。参数分别为数据集、候选项集列表,最小支持度
ssCnt = {}
for tid in D: #对于数据集里的每一条记录
for can in Ck: #每个候选项集can
if can.issubset(tid): #若是候选集can是作为记录的子集,那么其值+1,对其计数
if not ssCnt.has_key(can):#ssCnt[can] = ssCnt.get(can,0)+1一句可破,没有的时候为0,加上1,有的时候用get取出,加1
ssCnt[can] = 1
else:
ssCnt[can] +=1
numItems = float(len(D))
retList = []
supportData = {}
for key in ssCnt:
support = ssCnt[key]/numItems #除以总的记录条数,即为其支持度
if support >= minSupport:
retList.insert(0,key) #超过最小支持度的项集,将其记录下来。
supportData[key] = support
return retList, supportData
def aprioriGen(Lk, k): #创建符合置信度的项集Ck,
retList = []
lenLk = len(Lk)
for i in range(lenLk):
for j in range(i+1, lenLk): #k=3时,[:k-2]即取[0],对{0,1},{0,2},{1,2}这三个项集来说,L1=0,L2=0,将其合并得{0,1,2},当L1=0,L2=1不添加,
L1 = list(Lk[i])[:k-2]
L2 = list(Lk[j])[:k-2]
L1.sort()
L2.sort()
if L1==L2:
retList.append(Lk[i]|Lk[j])
return retList
def apriori(dataSet, minSupport = 0.5):
C1 = createC1(dataSet)
D = map(set,dataSet)
L1, supportData = scanD(D,C1,minSupport)
L = [L1] #L将包含满足最小支持度,即经过筛选的所有频繁n项集,这里添加频繁1项集
k = 2
while (len(L[k-2])>0): #k=2开始,由频繁1项集生成频繁2项集,直到下一个打的项集为空
Ck = aprioriGen(L[k-2], k)
Lk, supK = scanD(D, Ck, minSupport)
supportData.update(supK) #supportData为字典,存放每个项集的支持度,并以更新的方式加入新的supK
L.append(Lk)
k +=1
return L,supportData
dataSet = loadDataSet()
C1 = createC1(dataSet)
print "所有候选1项集C1:\n",C1
D = map(set, dataSet)
print "数据集D:\n",D
L1, supportData0 = scanD(D,C1, 0.5)
print "符合最小支持度的频繁1项集L1:\n",L1
L, suppData = apriori(dataSet)
print "所有符合最小支持度的项集L:\n",L
print "频繁2项集:\n",aprioriGen(L[0],2)
L, suppData = apriori(dataSet, minSupport=0.7)
print "所有符合最小支持度为0.7的项集L:\n",L
operation result:
所有候选1项集C1:
[frozenset([1]), frozenset([2]), frozenset([3]), frozenset([4]), frozenset([5])]
数据集D:
[set([1, 3, 4]), set([2, 3, 5]), set([1, 2, 3, 5]), set([2, 5])]
符合最小支持度的频繁1项集L1:
[frozenset([1]), frozenset([3]), frozenset([2]), frozenset([5])]
所有符合最小支持度的项集L:
[[frozenset([1]), frozenset([3]), frozenset([2]), frozenset([5])], [frozenset([1, 3]), frozenset([2, 5]),
frozenset([2, 3]), frozenset([3, 5])], [frozenset([2, 3, 5])], []]
频繁2项集:
[frozenset([1, 3]), frozenset([1, 2]), frozenset([1, 5]), frozenset([2, 3]), frozenset([3, 5]), frozenset([2, 5])]
所有符合最小支持度为0.7的项集L:
[[frozenset([3]), frozenset([2]), frozenset([5])], [frozenset([2, 5])], []]
Citations and References:
1. The main reference address of this article: https://blog.csdn.net/Eastmount/article/details/53368440
2. This article refers to the book "Introduction to Machine Learning"
The code will be supplemented and improved in time. If you need to reprint, please respect the author's hard work and indicate the source of the article!
Record life, share technology!