Welcome to the Tungsten Fabric user case series found that the more TF scenarios together. "Secret LOL" series hero is Tungsten Fabric users Riot Games gaming company, as LOL "League," the developer and operator, Riot Games challenges worldwide complex deployments, let us Secret LOL behind the "heroes" look how they are running the online service it.
Author: Doug Lardo and David Press (Source: Riot Games) Translator: TF Chinese community

In the last article , we discussed some of the content Riot for global application deployment solutions rCluster involved in the network. Specifically, we discussed the concept of overlay network, OpenContrail ( : Editor's note has been renamed Tungsten Fabric, at OpenContrail it appear below, are Tungsten Fabric in place to achieve), and Tungsten Fabric solutions how to work with Docker use.
This article will explore in depth on the basis of other topics: Infrastructure as Code, load balancing and failover testing. If you establish how and why these tools, infrastructure and processes are curious, then this article is for you.
Infrastructure as Code
Provides an API for configuring a network through Tungsten Fabric, we now have the opportunity to network demand automation applications. In Riot, we will continue to deliver best practices as published applications. This means that every submission to the master code is potentially releasable.
To achieve this status, the application must undergo a rigorous test automation, and has a fully automated build and deployment process. If there are problems, these should also be deployed repeatable and reversible. One of the complexity of this approach, applications are functional not only in the code thereon, in that environment, including network functions it depends.
In order to build and deploy repeatable, deal with each part of the application and its environment, version control and audit, in order to know who changed the content. This means not only to have each version of the application code in the source code management, and also describes its environment and versioning.
To enable this workflow, we built a system, a simple JSON data model (we call network blueprint) describe network functionality of the application. Then, we create a cyclical work, these blueprints to extract files from source control, and then convert it to the Tungsten Fabric API calls to implement appropriate strategies. Using this data model, application developers can define requirements, such as the ability to talk to one application with other applications. Developers do not have to worry about any details of the IP address or network engineer can usually only truly understand.
Application developers have their own network blueprint. Now, they just change their blueprint document issued to a pull request, and the other will be merged into the same easy to master. By enabling such self-service workflow, our network change is no longer limited to a small number of professional network engineers. Now, the only bottleneck is the engineer to edit JSON file and click "Submit" speed.
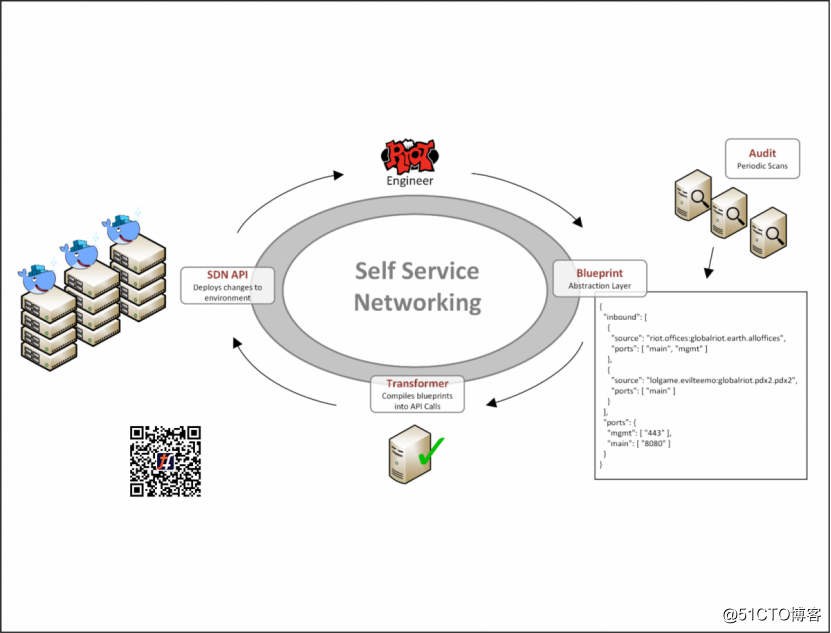
This system enables us to quickly and easily open the necessary network access rights, which is a key element of the local security policy. In Riot, safety-critical players, so we will be integrated into the security infrastructure of them. The two main pillars of our security policy is the least privileged and defense in depth.
Minimum privilege, any participant on the mean Riot network access only to complete a minimum set of resources needed for their work. Participants may be people, it may be back-end service. By doing this principle, we greatly limits the scope of potential ***.
Defense in depth means that we enforce security policies in multiple locations infrastructure. If *** were destroyed or bypass one of our point of execution, they will always encounter something more can compete. For example, a public Web server is prohibited from accessing the network payment system, and the system also maintains its own set of defensive measures, such as Layer 7 firewall and *** detection system.
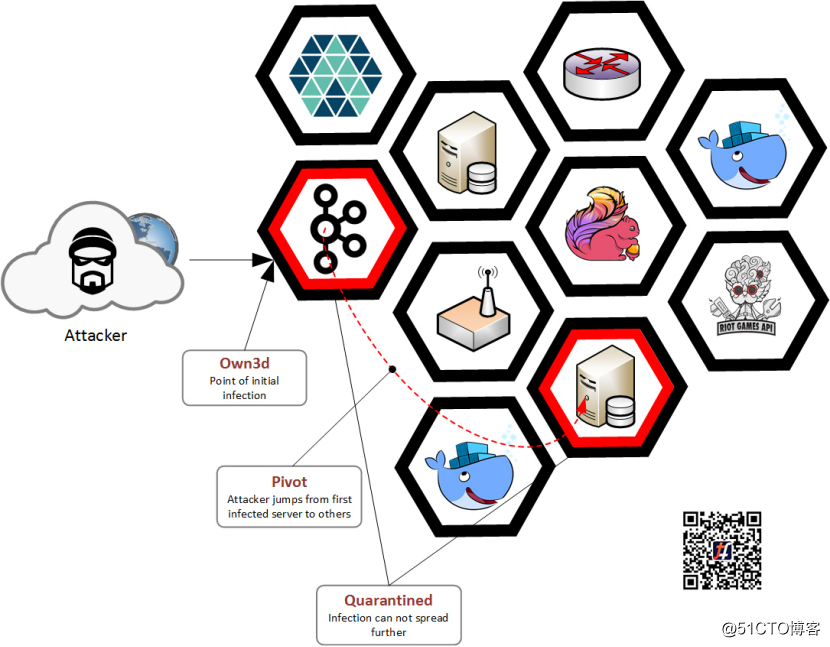
Tungsten Fabric executed by its vRouter add a point on each host to help us. To use its API via JSON Infrastructure as Code description file, we can always offer the latest, versioning, and audit network policy easy for communication between applications. We created a tool scans network rules to discover policy violations and access to too large. Speed, security best practices, as well as a combined audit capability constitutes a powerful security system, which does not prevent developers, on the contrary, it enables developers to quickly and easily do the right thing.
Load Balancing
In order to meet the growing needs of the application, we will DNS, the equivalent multi-path (ECMP) and conventional TCP load balancer (eg HAProxy or NGINX) combine to provide a feature-rich and highly available load balancing solution .
On the Internet, we use DNS to spread the load across multiple global IP addresses. Players can find "riotplzmoarkatskins.riotgames.com" such a record (not real, but perhaps it should be true), and we can use multiple IP addresses server replies, these IP addresses will respond to DNS queries. Half of the players may receive a list with the location server A is at the top, while the other half of the players will see the location server B at the top. If one server is down, the client will automatically attempt another server, so no one will see a break in service.
In the internal network, we have many servers are configured to answer A server's IP address. Ability to respond through this address, each server issued a circular to the network, while the network each server as a possible destination. Upon receipt of the new players to connect to, we will perform a hash calculation in the switch, which server to deterministically calculate the received traffic. Hash the IP address based on a combination of the packet header and the TCP port values.
If one of the servers "vacation", and we will try to use a technique called "consistent hashing" reduce the impact to the greatest extent, to ensure that only players using the failed server are affected. In most cases, customers will automatically restart through a new seamless connection to deal with this problem, the affected players will not even notice. After receiving a new connection, we have already detected and removed the server fails, so do not waste time trying to send traffic.
For most of our systems, we will automatically start a new instance, as soon as it is ready to receive traffic, the system will add it back into the circulation. We think it's very "beautiful." Last layer load balancing, by conventional TCP or HTTP load balancer (e.g. HAproxy or NGINX) performed.
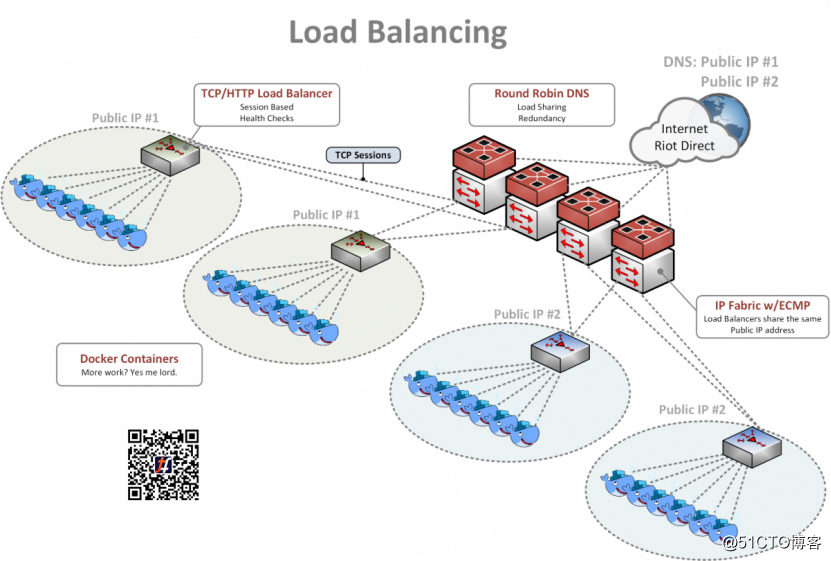
When a request from the ECMP layer, they may encounter a lot of load balancing instance. These load balancing instance monitor each real Web server, and make sure that the server is running in good condition, to respond within a reasonable time, ready to receive new connections. If all these conditions are met, the server receives the request, and the answer will always return to the player.
This layer is where we usually blue-green and deploy intelligent health checks, such as "response code of 200 /index.html loaded it?"
( Editor's note: Bule-green deploy a load balancing method of deployment health check, see link: https://blog.christianposta.com/deploy/blue-green-deployments-ab-testing-and-canary-releases / )
In addition, we can perform, such as "canary deployment", every 10 servers in a Web page to get the latest version, while the other nine servers still use the old version. We will closely monitor the new version to ensure without any problems, If everything goes smoothly, we will be two 10 servers to a new version, and so on. If the situation is poor, then fall back to the last known stable version, and find solutions to problems. We then add these tests to detect problems earlier, so as not to make the same mistake twice. This allows us to continue to improve services while minimizing the risk of production.
By working together all layers (DNS, ECMP and traditional TCP or Layer 7 load balancing), we offer a feature-rich, stable, and scalable solutions for developers and players, as much as possible so that we can fast server installed in the rack.
Failover testing
One of the most important parts of a highly available system is that when a fault occurs, the system can fail over. When we first started building a data center by allowing engineers to pull out some of the cable, and here and there some servers restart, to simulate these issues. However, once the data center is up and provide services for the players, this process will become very difficult, inconsistent, and simply can not accept. This has encouraged us to build something and then never again to touch it. We definitely found the key issues, and avoid the interruption of this process, but needs serious improvement.
First, we build a scaled-down version of the data center in the transitional environment. It is complete enough to be accurate. For example, in the transitional environment, we have two racks, each rack has five servers. The production systems are much larger in two dimensions, but our problems can be smaller, cheaper set to resolve.
In this transitional environment, we will test all the changes, and then its release to manufacturing. Our automated deployment will change here, for every change, we will execute them quickly basic tests to prevent us from doing stupid things entirely. This eliminates the need for automation systems we become conscious, conducted thousands of runaway change and eventually melted the entire planet a concern ( Editor's note: This sentence is particularly original theatrical --This removes the fear of our automated systems becoming sentient, making a thousand runaway changes, and eventually melting the whole planet, in fact, want to express that we do not over-rely on automated systems, for fear automated system will amplify subtle errors and destroyed the business ). With respect to the production environment, we prefer to capture these types of errors in the transitional environment.
In addition to the basic checks, we also conducted a more complex and destructive tests that destroyed the important components of the system and forced to run in a degraded state. Although only three of four subsystems subsystem can run, but we know that can endure such a loss, and we have time to repair the system without affecting the case of the player.
A full set of tests is more time consuming, more destructive (we prefer to interrupt the system and immediately start learning, rather than learning in production), and more complex than the basic test, so we run a full failover testing frequency is not high.
We let each link fail, restart the kernel, restart the TOR switch, disable SDN controllers, and any other way we can think of. Then, we measured the time failover system needed, and make sure everything is still running smoothly.
If things change, we can see the changes since the last run code to code done, and changes in production prior to delivery, to figure out what we could have changed. If we encounter unforeseen problems in production, and failover testing did not find the problem, we will quickly added to the test suite to ensure that a similar situation does not recur. Our goal is always to find the problem as soon as possible, the sooner the problems are found, the sooner we can fix it. When we work this way, not only can fast forward, and more confident.
in conclusion
In the previous article , we introduce the core concepts of data center and network implementation, this time we introduce how to implement infrastructure as code, and security policy, load balancing and failover testing. "Change is the only constant thing," probably the best theme these issues together. Infrastructure is alive, breathing, and in the evolving "animal." We need to provide resources when it grows, it needs to react when ill, need to complete all the work on a global scale as soon as possible. Embrace this reality means making sure our tools, processes and examples can respond to dynamic environment. All of this makes us believe that now is the perfect time to development and production infrastructure.
As usual, very welcome to get in touch with us, tell your questions and comments.
More "Secret LOL" series
Secret Shu LOL IT infrastructure behind the deployment of diversity set foot on the journey
Secret behind LOL IT infrastructure Shu key role of "scheduling"
Secret behind LOL IT infrastructure Shu SDN unlock new infrastructure

Focus on micro letter: TF Chinese community