Welcome to the Tungsten Fabric user case series found that the more TF scenarios together. "Secret LOL" series hero is Tungsten Fabric users Riot Games gaming company, as LOL "League," the developer and operator, Riot Games challenges worldwide complex deployments, let us Secret LOL behind the "heroes" look how they are running the online service it.
Author: Nicolas Tittley and Ala Shiban (Source: Riot Games) Translator: TF compilation group
This long series of articles, and discuss how to record Riot Games develop, deploy and operate the course of back-end infrastructure. We are a team of development experience Riot Nicolas Tittley software architect and product manager and Ala Shiban. Wherever we Riot team responsible for helping developers in which players build, deploy and operate the game, but without a sense of focus on cloud (cloud-agnostic) platforms, these platforms and the issuance of operating the game easier.
In the past two years ago in an article, Maxfield Stewart introduced the related development ecosystem, as well as many of the tools used at that time. Here we will update some of the latest content, including the new challenges faced, how to solve the problem, and what we've learned.
Quick Review
We strongly recommend that you go back and read the previous article, but if you want to directly read this article, there is a super-streamlined version to help you catch up.
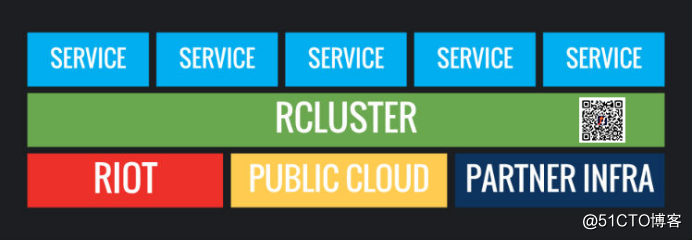
Riot back-end systems to run on a global scale using a combination of bare metal and cloud infrastructure. These back-end systems are dispersed to different geographical locations, based on entirely different deployment, allows the player running with LOL "Heroes Union" package of services interaction. Like most games of the same back-end system, as a whole, by a special operations team to be responsible for back-end operations when LOL start. Over time, Riot gradually embrace DevOps practices and service-based micro-architecture. The first article in this series introduced in detail, in order to help our developers to service the players faster, Riot rely heavily on this Docker containers packaged services, and they began to run in a cluster scheduler. Until a recent article , we discussed a number of tools for this purpose and use.
How do I run effect?
Very cattle, but, pain and happiness.
When the last article was published (Editor's note: Post time for the December 2017), we operates more than 5,000 production vessel. This figure does not stop growing, and today, only in the region (Riot-operated regions) Riot independent operation, we run more than 14,500 containers. Riot developers like to create new things for the players, the more easily when they write, deployment and operation of services, the more they can create exciting new experiences.
DevOps team to develop a real way, and be responsible for their own services. They created a workflow to deploy, monitor and operate those services, when what they need can not be found, simply re-invented. For developers, this is a very free time, they rarely encounter the problem can not be resolved.
But, we began to notice some worrying trends slowly. Monthly QA and load testing environment becomes more and more unstable. We have to spend more time to look for errors or outdated configuration dependencies. These isolated incidents are not critical, but in general, they spent a lot of time and energy to the team - we are more willing to spend on players in creating value.
Worse, in the fragmentation region (non-Riot shards) Riot non-independent operation, not only began to appear similar difficulties, but also broke a series of other problems. Partners must be more and more developers and docking, and the use of more and more micro-services, each service has a different way of micro, not the same with each other. Now, operations staff must work harder than ever to create an effective and stable slice area. In these fragments Riot independent regional non-operational, the problem incidence is much higher, in real-time version of the direct reason is not compatible micro services, or other similar cross-border issues.
Status of DevOps Riot
Before discussing how to solve the packaging, deployment and operation, let's take a moment to explore Riot operating environment. Riot these are not unique, but overlapping all these details, were indicative of how we are organized to provide value to all players.
Developer mode
Riot engineers like to build their own stuff! To help them do this, we use a powerful DevOps way of thinking. Team building and has its own back-end services to ensure their support, and split when the service performance as expected. Overall, Riot engineers are pleased to be able to achieve rapid iteration, and very happy to be responsible for their own real-time services. This is a very standard set of DevOps, Riot did not buck the trend in any way.
Split Mode stateful
Due to historical reasons, the scale of the problem, as well as the legal aspects of your factors, Riot product back-end systems are organized in a manner slice. Wherein the production of fragments typically geographically close to the target audience. This has many benefits, including improved latency issues, a better match, limited fault domain, and a clear off-peak time window (which can perform maintenance operations). Of course, we also run many internal and external development and QA fragments, such as "Heroes Union" open test server (PBE).
https://technology.riotgames.com/sites/default/files/engineeringesports_4.gif
{kind=link}
Business model
This is where things get more complicated. Although Riot is a developer, but for reasons of compliance and know-how, we collaborate with a number of local operators to provide some service fragment. In practice, this means that the developer Riot each component must be packaged slice, it will be delivered to the operating personnel, and guidance on how they deploy, configure and operate all the fragments. Riot developers themselves will not operate, even access to view the fragments. (Editor's note: the text of the fragment will be appreciated that the logical component block defined subregion)
Iterative solution
1- try new alliance deployment tools
Our first attempt to improve the situation, to take a new approach, try to use open source components and minimal customization Riot, Riot to advance the deployment and operations. Although this work successfully deployed a complete "Heroes Union" fragmentation, but the design is not the way to achieve the desired tool developers and operations staff. Team expressed dissatisfaction with the tool - a tool proved too difficult for the operator uses, the developer is too constrained.
Therefore, after the first fragment of deployment, we have made the painful decision - to make these tools retire. It looks like a very radical, but because of all the team still has its own maintenance and deployment of the system is not yet fully transition, so we can quickly eliminate new tools.
Try to process more 2-
Since the first attempt is not successful as expected, we turn to tradition, by adding a process to meet the requirements. Extensive communication, a clear release date, documented processes, change management meetings and ceremonies, as well as the ever-present spreadsheet, to some extent, has made a little progress, but always feel bad. Teams prefer their freedom DevOps, a huge amount of change and the speed of change, all make their work more arduous. Although the situation has improved partners, but we have yet to achieve the desired operating level.
Try 3- Metadata
We decided to try another approach. Before we have the developer tools as the primary audience, now began to study for the operations staff to partners, deploying / operating system works. We designed a tool that allows developers to add standardized metadata package to its micro-services Docker containers, such as configuration and expansion characteristics required. This brings progress, operators can adopt a more standardized way to understand the required service configuration and deployment features, and reduce reliance on developers in their daily operations.
In this case, the failure rate and local partners to operate the site, the event rate and additional downtime has improved, but we are still experiencing frequent deployment and operational failures that could have been avoided.
Try applications and environments of mode 4-Riot
We finally adopted a new approach, the focus will shift from personal services to the entire product. We have created a high-level declarative specification, and a set of tools for performing actions, norms and tools to make something special. Before details, let's look at the three previous attempts in what the problem is.
Reflection wrong with
Deployment and operation of the product, rather than the service
Despite the embrace DevOps and micro service has brought us many benefits, but it creates a dangerous feedback loop. Development team to create a micro-services, its deployment, operation, and is responsible for its performance. This means that they are optimized for himself logs, metrics and processes, and usually with little regard for their ability to service other people understand, including the development background who do not even engineering capabilities.
With more and more developers to create micro-service operators overall product becomes very difficult and lead to more and more failures. The most important thing is, Riot of flow team structure, the ownership of some micro-services become clear, it is difficult to figure out who should I contact in the shunt, causing a lot of property the wrong page. More and more heterogeneous micro-services, the deployment process and organizational changes, regional partners operating team at a loss.
Find out "why"
We examined the failure Riot Riot operational and non-operational areas of the region, and refining the difference frequency of failures is a key observation:
Allow discontinuous change flow into the distributed system will eventually lead to preventable events.
When a team wants to cross-border coordination, it will begin to fail, because the dependency needs to be released bundled with several changes. Team or use manual processes to create the publication cycle to coordinate the launch ceremony by project management, release or temporary release smaller changes, leading the team into chaos in the process to find a compatible version of.
Both have their advantages and disadvantages, but tend to collapse in a large organization. Imagine dozens of teams need a coordinated manner, continuous delivery of goods on behalf of hundreds of micro-sharing service, and allow different services use these micro-development practices. To make matters worse, for the partner, it is very difficult to try to apply these processes, their personnel do not have the context of how the various parts are combined.
New solutions: Riot application and environment model
Given the results of previous attempts failed to produce the expected, we decided to create (opinionated) a declarative specification for personal use inherent part of the state to eliminate the manipulation of the declarative specification can capture the entire distributed product - environment. Environment includes fully specified, deploy, configure, run and operate a set of distributed all declarative metadata required for micro-services, these micro-services together represent a product, and are complete and unchanged version. We chose the "environment" that name, because it is not a word Riot of the most overused. Naming it is a difficult task.
With the release of the game LOR "the land of Rune Legend", we can prove that the entire description of the micro-game backend services (including gaming server), and make it operational in the autonomous region and Riot data centers worldwide partners, as the product deployment, operations, and operations. We have also demonstrated the ability to achieve this goal while improving DevOps approach has the advantage of much loved.
What were the provisions described in (OPINIONATED ON WHAT)
This specification describes the hierarchical relationship between the service bundle or the environment.
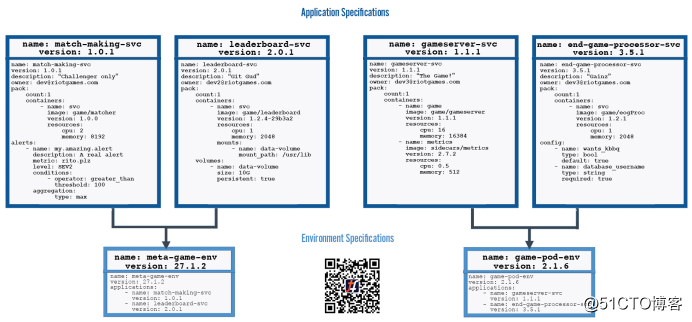
Bundled into the application environment specification specification
And high-level declarative
One of the benefits of declarative specification is that it is easy to operate. For operations staff partners, one of their difficulty, just can not understand, adjust and deployment potentially automate the entire game backend. Declarative nature of the specification, which means it does not need engineers scripting or programming expertise, you can make changes to most of the content specification.
To maintain a high level of specification, it helps to define and achieve decoupling of the rear end of the base game. This allows us to minimize the impact of the situation in the studio for the next game, from internal organizer / scheduler called Admiral, migration to Mesos based scheduler, as well as consider migrating to Kubernetes. It also enables our partners ops can exchange their infrastructure components when needed. For example, it allows operations personnel can use different metrics aggregation system, without the need to change the micro-service tools.
Immutable versioned
We found that to be effective in deploying and operating DevOps world of rapid development, the use of a shared language to refer to services and environment is essential. Version control and environmental services and their associated metadata, so that we can ensure that all locations have deployed the correct version. It makes our operator partners can know for sure which version is running, and back to us. In addition, when applied to the entire environment, it provides a set of well-known service can be checked and marked as "good" its quality. This bundling eliminates any possibility of missing new version when communicating to partners dependencies.
So that these versions can not be changed, it can ensure that we maintain this common language. When the same version of the service is deployed in two different slice, we can now also be sure they are identical.
Focus on operations
Given our goal is to improve partner operations staff service level players, we quickly realized that the deployment of the software is only the first step. Find out how to classify, operation and maintenance of real-time systems, it is equally important thing.
Historically, we are very dependent on the operations manual. Manual maintenance by the developer, with varying degrees of success, they recorded everything from the necessary configuration values to high-level architecture. In order to enable partners have operations staff to configure and operate all the knowledge required for each service, we decided to run as much information as those contained in the manual to the service specifications first. This greatly reduces the time regional partners into new services, and to ensure that they were told that all the important changes in the micro-updating service.
Today, partner operators can use this specification to learn about the operation of metadata, including required / optional, extended features, maintenance operations, an important indicator / alert definition, deployment strategies, dependencies between services, as well as increasingly the more other useful information.
Fragments difference
Of course, fragments are not identical copies of each other. While we want to make them as close as possible, but there are some configuration must be different. Database password, language support, extended parameter, as well as specific adjustment parameters must change with each slice. To support this mode, the tools we use to cover environmental norms hierarchical system deployment, allowing operators can deploy a particular specialization, while still know that they are derived from a known good version. Let's see how it works!
Applications
A simple game backend may include two environments, one for the game server and one for the dollar gaming service (rankings, matching system, etc.). Yuan game environment from a variety of services: list, matching system, game history, and so on. Each service comprises one or more images Docker, conceptually, they are equivalent to Kubernetes container. For all environments, the same hierarchy are correct, and from a philosophical perspective, every environment without exception encapsulates deployed on any supported cloud or infrastructure required to run the game and back-end operations everything, and all of its dependencies.
The specification also includes all metadata required to run and operate the environment. Growing collection of modules including configuration, confidential, indicators, alarms, documentation, deployment and rollout strategy, inbound network restrictions, as well as storage, database and cache requirements.
Here we have an example that demonstrates the game for two hypothetical slice deployed in both regions. You can see them by the dollar and the game environment game server environment component. In Europe slice of game server production environment, behind the United States similar slice of gaming environment. This provides a common language for describing and comparing different game for game patch deployment and operations teams. The number of services each environment can keep increasing simplicity, which can reliably deploy dozens of fragments. 
Game exemplary deployment fragment
Our next step: Delay aware scheduling
We hope to be able to describe the expected and acceptable delay between services, and tools optimized for the basis of regional and lower-level PaaS service to enable it to meet these needs. This will lead to some services in the same rack, the host or cloud area, rather than allowing their distribution in other services.
Since the performance characteristics of the game server and support services, it is highly correlated with us. Riot cloudy already is a company with our own data center, but also the AWS cloud and partners, but we rely on static design topology. Card games and shooting games have a different profile, do not have a manual for topology optimization, in both cases, which saves engineers time so they can focus on the game above.
Last words
We are faced with the problem of decreased stability in the run game, mainly from business partners slice of the game. Tools development team bundled with open source deployment tools, and add metadata to the container, and the game is the team implemented a centralized publishing process. These methods can solve the symptoms, but fail to address the root causes of the problem, which means that we could not achieve the target level.
Our solutions finally adopted the introduction of a new specification that captures all of the back-end topology of the entire game, hierarchies, and metadata and all of its dependencies. This approach is effective because it provides a consistent release of version binding container, dependency interaction between them, and all metadata support needed to start and operate the entire game. The immutability brought deploying deterministic and predictable operation.
As a platform team, our goal is to pick a system capable of generating a virtuous cycle and building blocks, in a virtuous cycle, functional development work will naturally bring easy-to-operate products. The DevOps agility and ease of operation mode of the combination product is the key to long-term organizational agility. Our environment is directly tied method improves operational metrics, is more important is to improve the quality of the player experience. We are very pleased to see how others in our industry to solve similar problems. We've seen a large cloud providers and from CNCF (native cloud computing Foundation) (such as the Microsoft Open Specification Application Mode) ideas and projects. Some of these projects hope to be able to replace the norms of our own making, and moving towards industry-wide solutions.
In a future article, we will explore in more detail Riot specification describes examples and a discussion of the design tradeoffs and Riot specific shortcuts.
thanks for reading! If you have any questions, welcome to contact us.
More "Secret LOL" series
Secret Shu LOL IT infrastructure behind the deployment of diversity set foot on the journey
Secret behind LOL IT infrastructure Shu key role of "scheduling"
Secret behind LOL IT infrastructure Shu SDN unlock new infrastructure
Secret IT infrastructure Shu infrastructure LOL that is the code behind the
Secret service IT infrastructure Shu micro ecosystem LOL behind
what Secret behind LOL IT infrastructure Shu developers "playing field" tool do?

