Selenium is a tool for Web application testing. Selenium tests run directly in the browser, just as real users in the same operation.
(End of this article there is a complete code)
0. installation selenium library
pip install selenium
1. Download the corresponding browser browser driver
Here I use the Google browser
Driver Download Chrome browser
to download directly to extract the good of the directory to python
2. Import libraries and sets a headless browser (optional)
Headless browser, which is no interface of the browser.
from time import sleep
from selenium import webdriver
# 无头浏览器设置
co = webdriver.ChromeOptions()
co.headless = True
browser = webdriver.Chrome(options=co)
When co.headless = False when there is the interface of
3. Open the Baidu website
url = 'https://www.baidu.com'
browser.get(url)
Because our code execution speed faster than the speed of Baidu server response.
Baidu has not had time to return search results, we execute the following code
browser.implicitly_wait(3)
If no such element, every half a second to go once to see on screen until you find the element, or over 3 seconds maximum duration.
4. The use of chrome f12 find open id search box and search button
That is, find the program you need to enter or click on the location where
First press f12 to open the Developer Tools, select the label Elemes, and then click the arrow next to
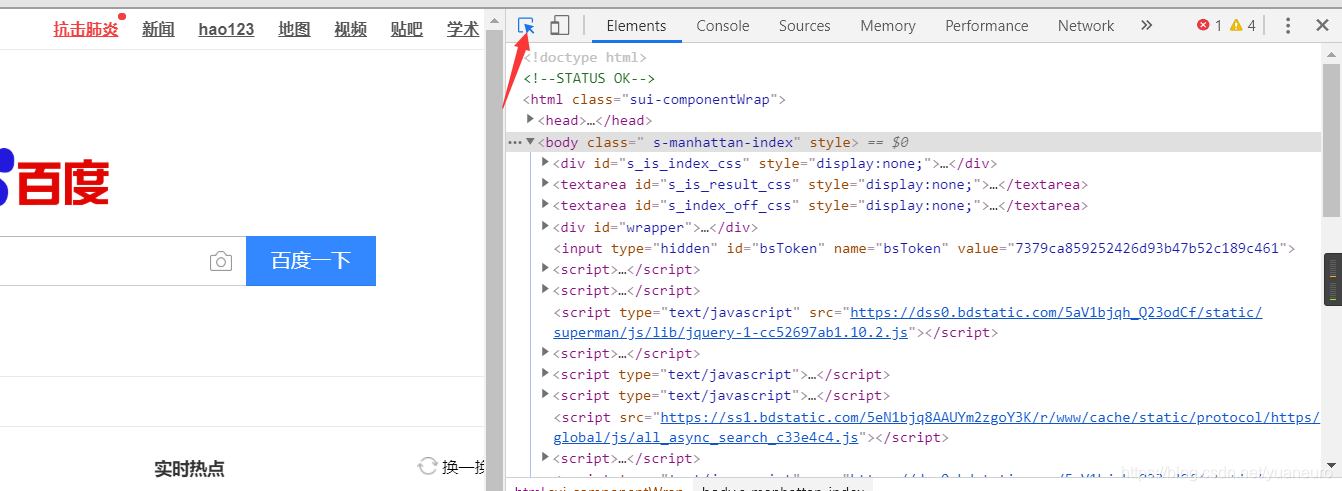
then put the mouse on the input box on the Elements will target tag id of the input box, the id is unique in this web page
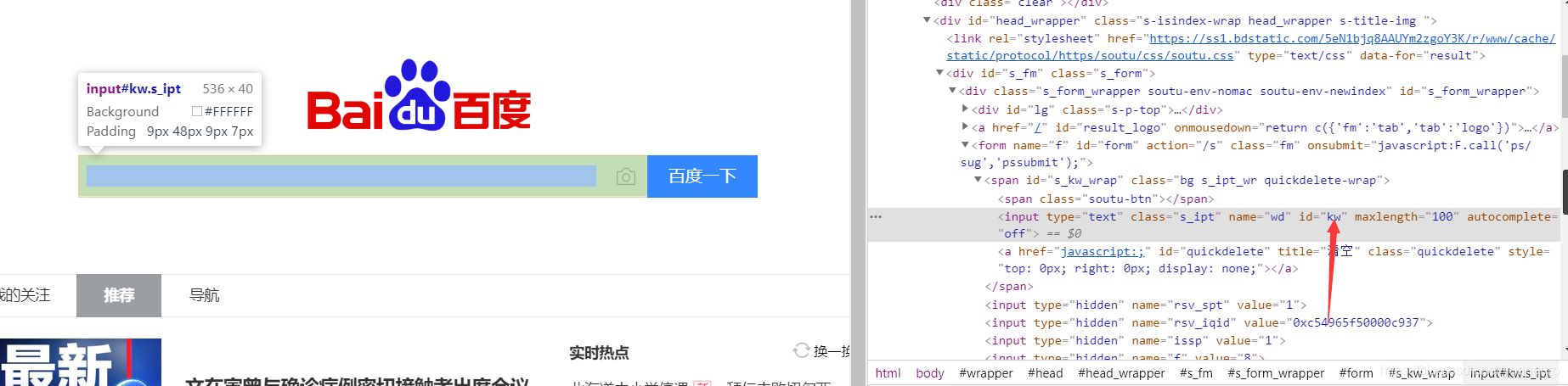
Similarly to obtain the search button mouse on the elements in the search box on the id

get this even a id that we can continue to write programs
browser.find_element_by_id('kw').send_keys('kali搭建钓鱼wifi csdn') # 输入框
browser.find_element_by_id('su').click() # 点击搜索按钮
among them
find_element_by_id () is to find the page elements id
send_keys () method can be a string in the corresponding element
click () method of the element by clicking
5. Find the search interface element id
If you and I do together in front of the right, now the page should have it jump to the search results,
then download and as before, to find the id of each element of the result
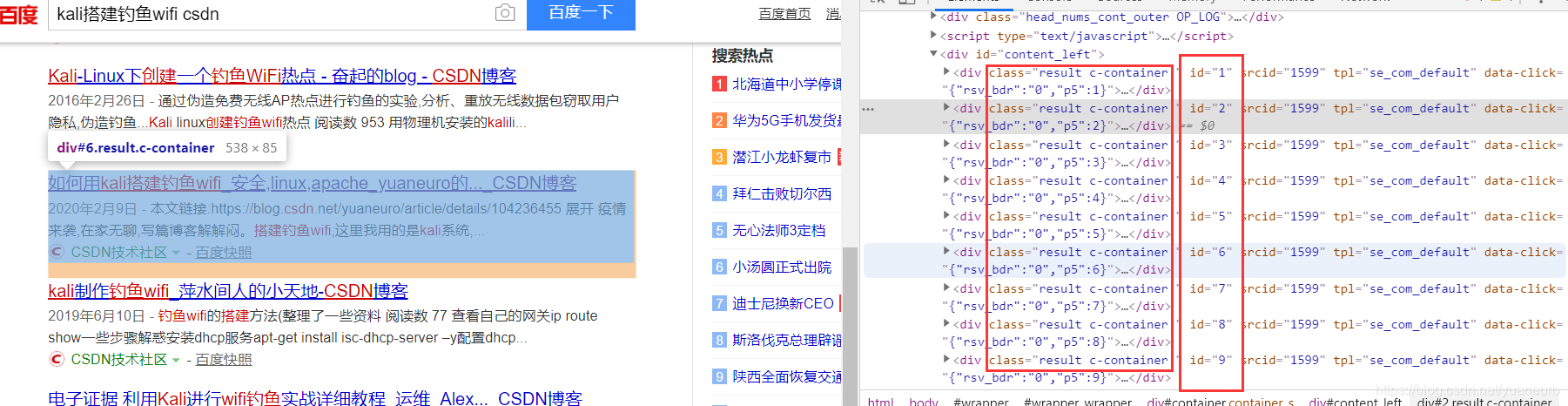
we found, id each result is regular, id from 1-10 corresponding respectively 10 search results, and they belong to the c-container class
so we directly find all the c-container class
elements = browser.find_elements_by_class_name('c-container') # 查找到所有c-container类
note
Here is find_elements_by_class_name (), id find more than the previous one s, which is in line with the conditions of return found in all elements (there are three elements), in a list in return.
And if we use find_element_by_class_name (note one less s) method will only return the first element.
6. The for loop output
Here we see that the search results are placed on a label in the

so we element.find_element_by_tag_name () to find a label in the text that the search results.
for element in elements:
span = element.find_element_by_tag_name('a')
print(span.text)
7. crawling finished, quit the browser
sleep(2)
browser.quit()
Is not very simple, only a short two dozen lines of code to get!
The complete code
"""
用selenium百度搜索结果显示
"""
from time import sleep
from selenium import webdriver
# 无头浏览器设置
co = webdriver.ChromeOptions()
co.headless = True
browser = webdriver.Chrome(options=co)
browser.implicitly_wait(3)
url = 'https://www.baidu.com'
browser.get(url)
browser.find_element_by_id('kw').send_keys('kali搭建钓鱼wifi csdn') # 输入框
browser.find_element_by_id('su').click() # 点击搜索按钮
elements = browser.find_elements_by_class_name('c-container') # 查找到所有c-container类
for element in elements:
span = element.find_element_by_tag_name('a')
print(span.text)
# print(span.get_attribute('innerHTML'))
sleep(2)
browser.quit()
If you liked this article, I want to leave your praise
![]()
