Sometimes when we need to use some of the article Baidu library, but found the need for Members to download, very hard to accept, in fact, we can get to the text we need by way of reptiles.
Tools: python3.7 the Selenium + a + any editor
Preparation: You can use a normal browser, here recommend chrome, a browser version of the same drive, here is a link to download the driver https://chromedriver.storage.googleapis.com/77.0.3865.40/chromedriver_win32.zip
First we look at Baidu library this article https://wenku.baidu.com/view/5b1ef2cfbf23482fb4daa58da0116c175e0e1e0a.html
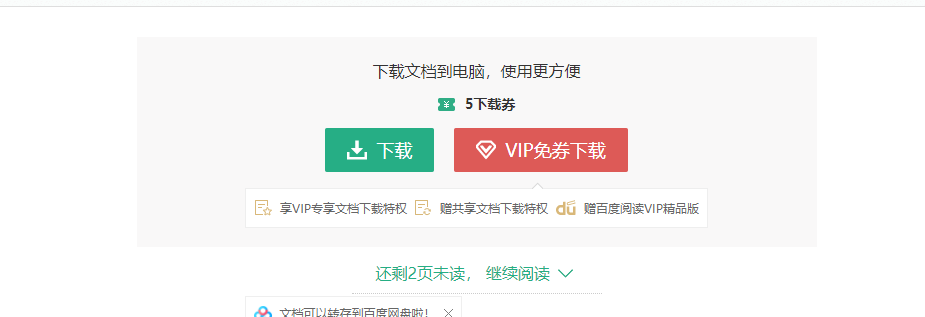
You can see, we need at the end of most articles Click to continue reading in order to climb to get all of the text, or we can get to a part of the text. This gives us reptiles brought some problems. Therefore, we need the help of selenium that an automated tool to help our program this is done.
from selenium import webdriver from selenium.webdriver.common.keys import Keys import time from bs4 import BeautifulSoup import re driver = webdriver.Chrome('D:/chromedriver.exe') driver.get("https://wenku.baidu.com/view/5b1ef2cfbf23482fb4daa58da0116c175e0e1e0a.html")
Let's take a drive through the page request,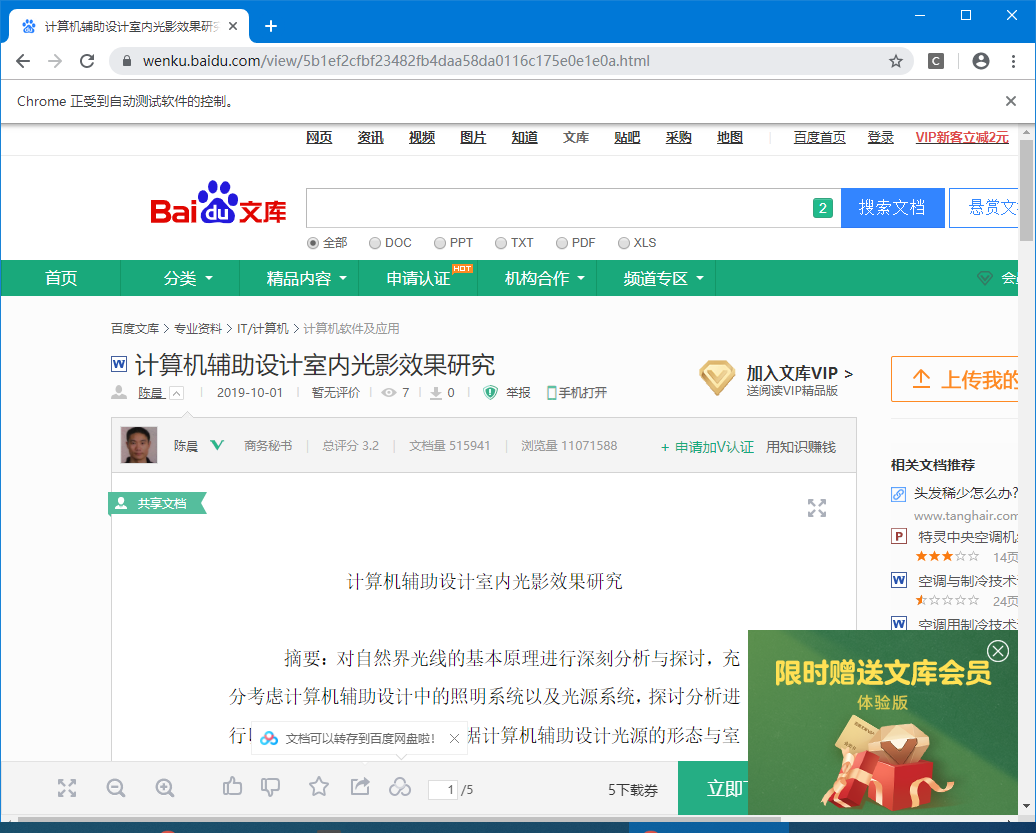
You can see, this page has been requested by the successful. Next you need to load all of our text to this article by clicking the drive to continue reading. We review the elements by f12, and see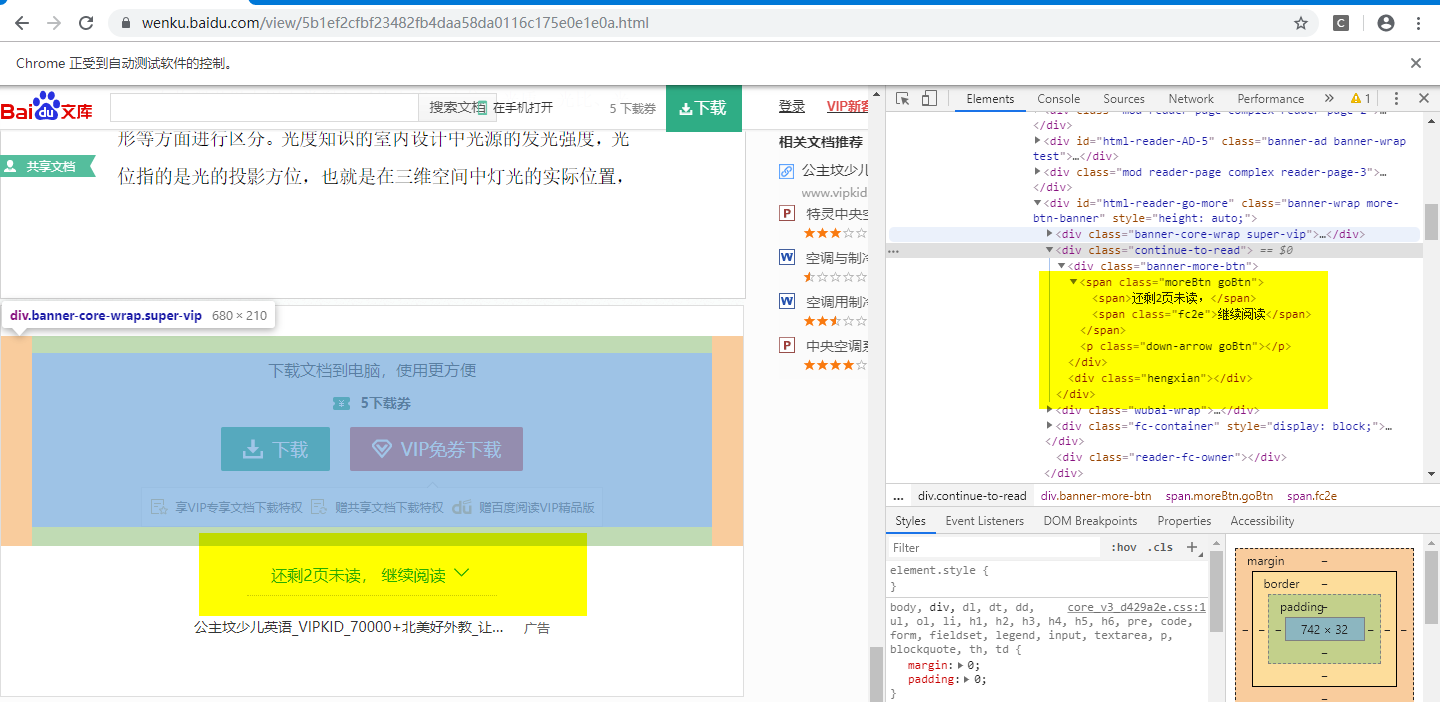
Then by positioning selenium, and navigate to the location where the yellow area on the left, click to call drives
driver = webdriver.Chrome('D:/chromedriver.exe') driver.get("https://wenku.baidu.com/view/5b1ef2cfbf23482fb4daa58da0116c175e0e1e0a.html") driver.find_element_by_xpath("//*[@id='html-reader-go-more']/div[2]/div[1]/p").click()
Then look at the implementation
 Huang word is information being given, it shows there is another element to accept the call clicks. Probably not slide to the bottom of the screen, just click covered up. So we have to first browser to slide in the end part via the drive, and then click Continue reading
Huang word is information being given, it shows there is another element to accept the call clicks. Probably not slide to the bottom of the screen, just click covered up. So we have to first browser to slide in the end part via the drive, and then click Continue reading
from selenium import webdriver from selenium.webdriver.common.keys import Keys import time from bs4 import BeautifulSoup import re driver = webdriver.Chrome('D:/chromedriver.exe') driver.get("https://wenku.baidu.com/view/5b1ef2cfbf23482fb4daa58da0116c175e0e1e0a.html") page=driver.find_element_by_xpath("//*[@id='html-reader-go-more']/div[2]/div[1]/p") driver.execute_script('arguments [0] .scrollIntoView (); ' , Page) # dragged to the visible elements to Page driver.find_element_by_xpath = ( " // * [@ ID =' HTML-Reader-More-Go '] / div [2] / div [. 1] / P " ) .click ()
Continue reading to get to the page where the location, and then use
driver.execute_script ( 'arguments [0] .scrollIntoView ();', page) # drag element method visible to scroll to the page can click on the position
thus acquired to complete the entire page is parsed using beautifulsoup
html=driver.page_source bf1 = BeautifulSoup(html, 'lxml') result=bf1.find_all(class_='page-count') num=BeautifulSoup(str(result),'lxml').span.string count=eval(repr(num).replace('/', '')) page_count=int(count) for i in range(1,page_count+1): result=bf1.find_all(id="pageNo-%d"%(i)) for each_result in result: bf2 = BeautifulSoup(str(each_result), 'lxml') texts = bf2.find_all('p') for each_text in texts: main_body = BeautifulSoup(str(each_text), 'lxml') s=main_body.get_text()
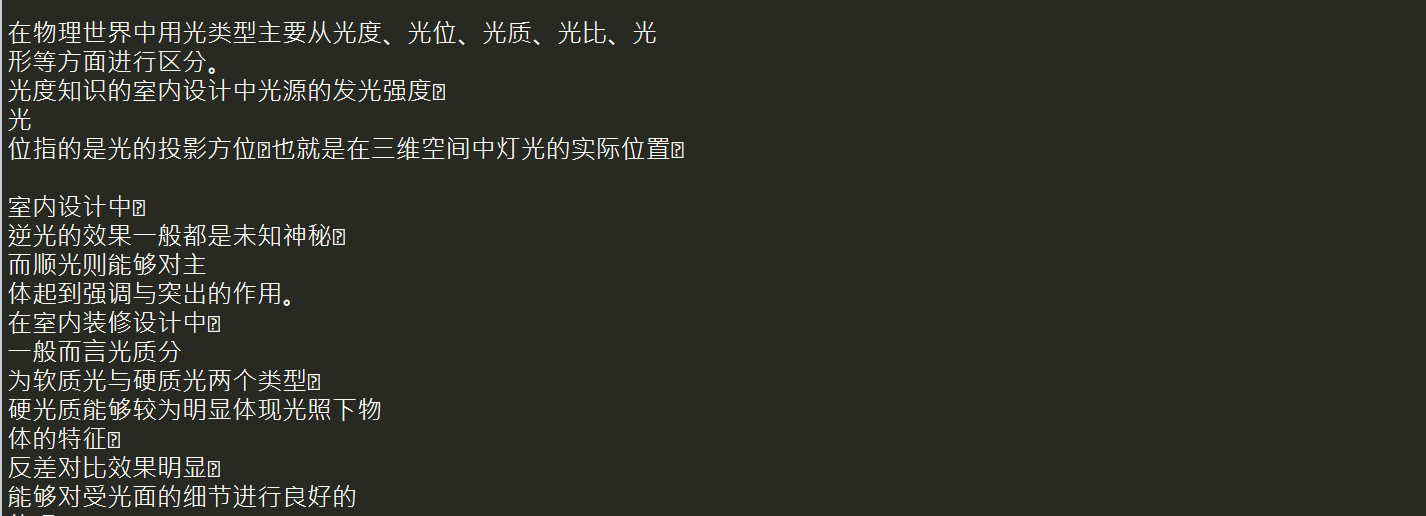
Finally, write txt document
f=open("baiduwenku.txt","a",encoding="utf-8") f.write(s) f.flush() f.close()