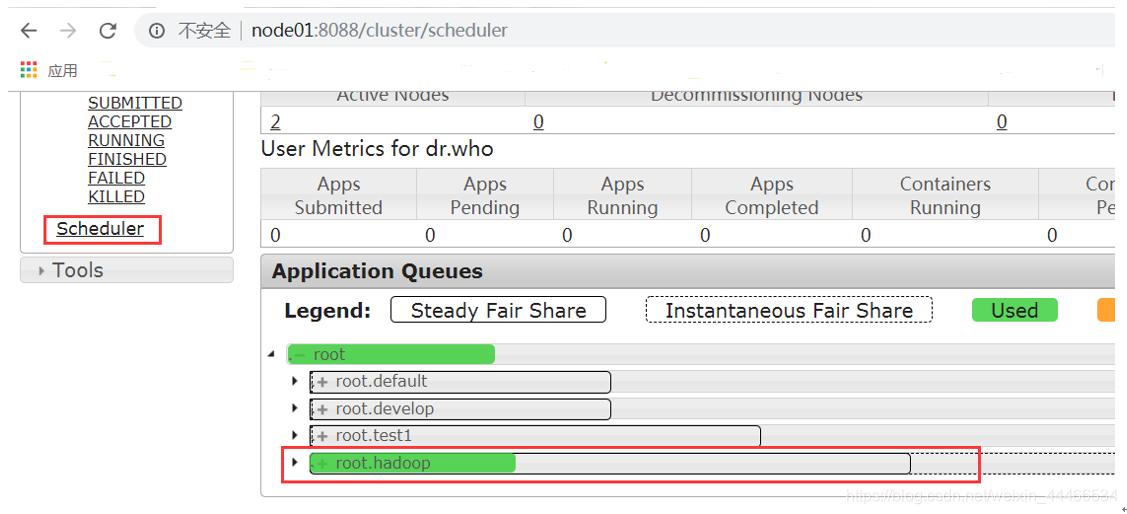
Yarn Scheduler Profile Scheduler
Ideally, we applied a request for Yarn resources should immediately be met, but the reality resources are often limited, especially in a very busy cluster, request an application resource often need to wait for some time before to the appropriate resources . In Yarn, the application is responsible for allocating resources is Scheduler. In fact, the scheduling itself is a problem, it is difficult to find a perfect strategy can solve all scenarios. For this purpose, Yarn offers a variety of scheduling and configurable strategy for us to choose.
Three scheduler may select the Yarn: FIFO Scheduler, Capacity Scheduler, Fair Scheduler.
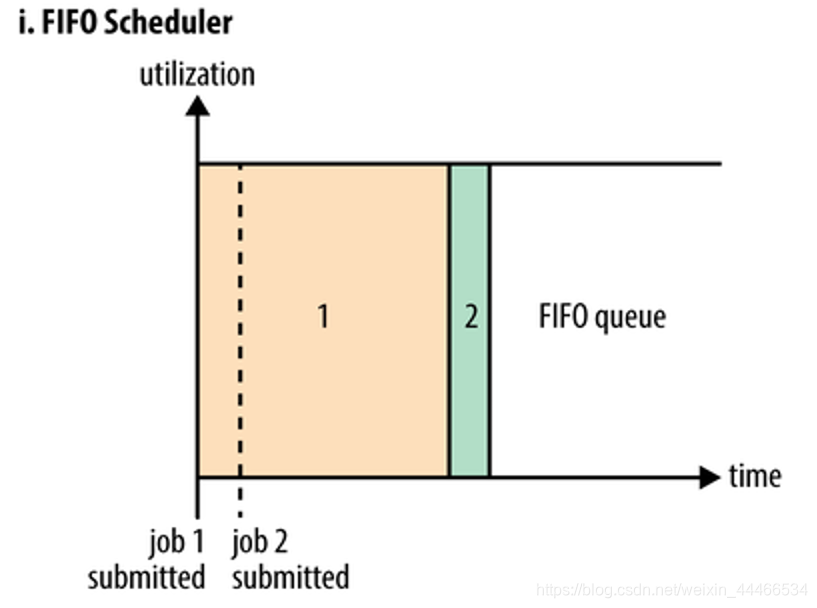
1、FIFO Scheduler: FIFO Scheduler把应用按提交的顺序排成一个队列,这是一个先进先出队列,在进行资源分配的时候,先给队列中最头上的应用进行分配资源,待最头上的应用需求满足后再给下一个分配,以此类推。
FIFO Scheduler是最简单也是最容易理解的调度器,也不需要任何配置,但它并不适用于共享集群。大的应用可能会占用所有集群资源,这就导致其它应用被阻塞。在共享集群中,更适合采用Capacity Scheduler或Fair Scheduler,这两个调度器都允许大任务和小任务在提交的同时获得一定的系统资源。
FIFO Scheduler :先进先出,谁先提交谁先执行(先来后到)。
For example FiFo child: Dafan the cafeteria line up, line up to buy tickets, hospital,
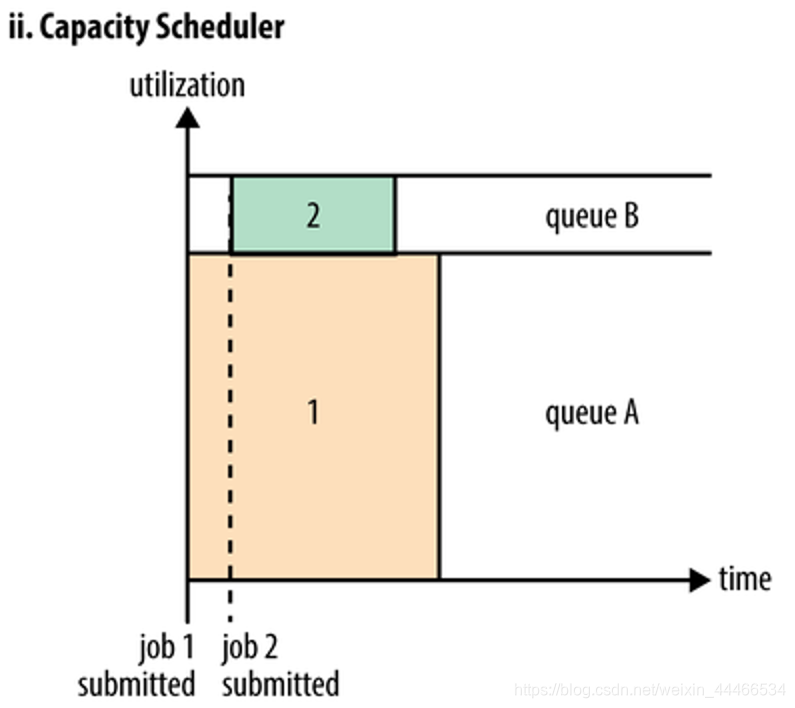
2、Capacity 调度器允许多个组织共享整个集群,每个组织可以获得集群的一部分计算能力。通过为每个组织分配专门的队列,然后再为每个队列分配一定的集群资源,这样整个集群就可以通过设置多个队列的方式给多个组织提供服务了。除此之外,队列内部又可以垂直划分,这样一个组织内部的多个成员就可以共享这个队列资源了,在一个队列内部,资源的调度是采用的是先进先出(FIFO)策略。
容量调度器 Capacity Scheduler 最初是由 Yahoo 最初开发设计使得 Hadoop 应用能够被多用户使用,且最大化整个集群资源的吞吐量,现被 IBM BigInsights 和 Hortonworks HDP 所采用。
Capacity Scheduler 被设计为允许应用程序在一个可预见的和简单的方式共享集群资源,即"作业队列"。Capacity Scheduler 是根据租户的需要和要求把现有的资源分配给运行的应用程序。Capacity Scheduler 同时允许应用程序访问还没有被使用的资源,以确保队列之间共享其它队列被允许的使用资源。管理员可以控制每个队列的容量,Capacity Scheduler 负责把作业提交到队列中。
Capacity Scheduler:容量调度器。以列得形式配置集群资源,每个队列可以抢占其他队列得资源。多个队列可以同时执行任务。但是一个队列内部还是FIFO。
Capacity of the child scheduler example: buy train tickets multi-window, multi-window Dafan the cafeteria line, multi-window bank counter service, high-speed toll gate
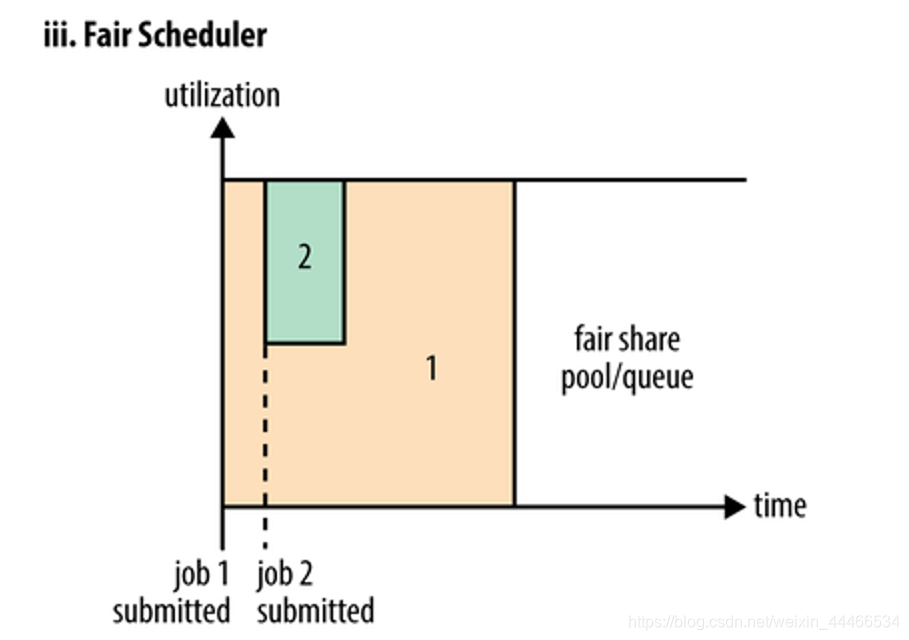
3、在Fair调度器中,我们不需要预先占用一定的系统资源,Fair调度器会为所有运行的job动态的调整系统资源。如下图所示,当第一个大job提交时,只有这一个job在运行,此时它获得了所有集群资源;当第二个小任务提交后,Fair调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。
需要注意的是,在下图Fair调度器中,从第二个任务提交到获得资源会有一定的延迟,因为它需要等待第一个任务释放占用的Container。小任务执行完成之后也会释放自己占用的资源,大任务又获得了全部的系统资源。最终效果就是Fair调度器即得到了高的资源利用率又能保证小任务及时完成。
公平调度器 Fair Scheduler 最初是由 Facebook 开发设计使得 Hadoop 应用能够被多用户公平地共享整个集群资源,现被 Cloudera CDH 所采用。
Fair Scheduler 不需要保留集群的资源,因为它会动态在所有正在运行的作业之间平衡资源。
Fair Scheduler :公平调度器,同样以列得形式配置集群资源,每个队列可以抢占其他队列得资源。当被抢占得队列有任务时,抢占得队列奉还资源。不知指出在与奉还资源需要一段时间。
Fair Scheduler for example sub-: priority to buy tickets soldier, ride the bus for the elderly
1, Capacity Scheduler (CDH default scheduler)
Use scheduler by yarn-site.xml configuration file
configuring yarn.resourcemanager.scheduler.class parameters,Defaults Capacity Scheduler scheduler.
假设我们有如下层次的队列:
Root
├── prod(生产环境) 40 %
└── dev(开发环境) 60 %
├── mapreduce 60 %的50%
└── spark 60 % 的50%
The following is a simple scheduler Capacity profile,File called capacity-scheduler.xml. In this configuration, we define two sub-queues and prod dev in root queue below, respectively, 40% and 60% of capacity. Note that a queue configuration is specified by attribute yarn.sheduler.capacity .., represents the inheritance tree of queue, such as queue root.prod, generally refers to the capacity and maximum-capacity.
1、编辑集群内的capacity-scheduler.xml 配置文件,输入一下内容
<configuration>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>prod,dev</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.queues</name>
<value>mapreduce,spark</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.prod.capacity</name>
<value>40</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.capacity</name>
<value>60</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.maximum-capacity</name>
<value>75</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.mapreduce.capacity</name>
<value>50</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.spark.capacity</name>
<value>50</value>
</property>
</configuration>
我们可以看到,dev队列又被分成了mapreduce和spark两个相同容量的子队列。dev的maximum-capacity属性被设置成了75%,所以即使prod队列完全空闲dev也不会占用全部集群资源,也就是说,prod队列仍有25%的可用资源用来应急。我们注意到,mapreduce和spark两个队列没有设置maximum-capacity属性,也就是说mapreduce或spark队列中的job可能会用到整个dev队列的所有资源(最多为集群的75%)。而类似的,prod由于没有设置maximum-capacity属性,它有可能会占用集群全部资源。
关于队列的设置,这取决于我们具体的应用。比如,在MapReduce中,我们可以通过mapreduce.job.queuename属性指定要用的队列。如果队列不存在,我们在提交任务时就会收到错误。如果我们没有定义任何队列,所有的应用将会放在一个default队列中。
注意:对于Capacity调度器,我们的队列名必须是队列树中的最后一部分,如果我们使用队列树则不会被识别。比如,在上面配置中,我们使用prod和mapreduce作为队列名是可以的,但是如果我们用root.dev.mapreduce或者dev. mapreduce是无效的。
The updated configuration is distributed to all nodes in the cluster
scp capacity-scheduler.xml node02:/$ PWD
scp capacity-scheduler.xml node03:/$ PWD
(The $ PWD and intermediate spaces removed)
Restart Yarn cluster
./stop-all.sh
./start-all.sh
验证上面创建的对列
通过mapreduce.job.queuename指定对列的名字
mapreduce.job.queuename=mapreduce
hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.14.0.jar pi -D mapreduce.job.queuename=mapreduce 10 10
Demonstration Figure

Renderings
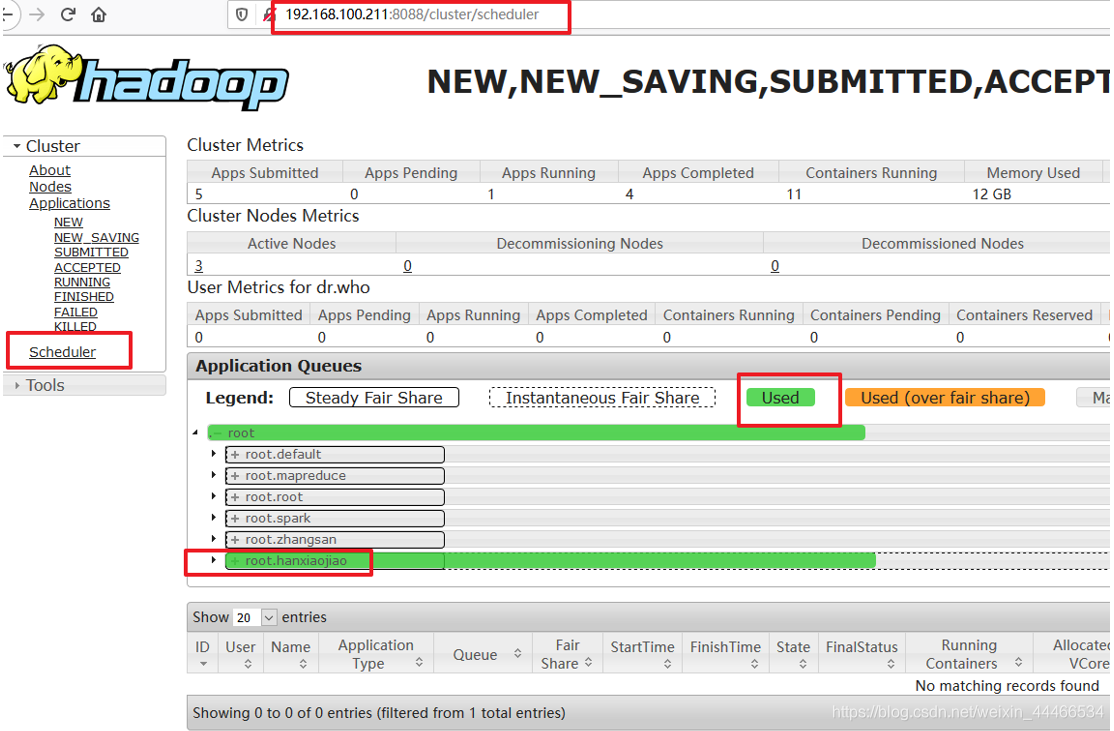
2, yarn multi-tenant resource isolation
In an internal company Hadoop Yarn cluster, it will certainly be more traffic, multiple users simultaneously, sharing Yarn resources, resource management and planning if not, then the entire Yarn resources can easily be submitted to one of the user's Application filled, can only wait for other tasks, this course is very unreasonable, we hope that each business has its own specific resources to run MapReduce tasks, Hadoop provides a fair scheduler -Fair scheduler, to meet this demand .
Yarn Fair Scheduler entire available resources into a plurality of resource pools, each pool of resources can be configured minimum and maximum available resources (memory and the CPU), the maximum number of simultaneous running Application, weight, and may be submitted to the Application Manager and users.
Fair Scheduler addition to the need to enable the yarn-site.xml file and configurationBut also need an XML filefair-scheduler.xmlTo configure resource pools and quota, and the quota for each XML resource pool can be updated dynamically, then use the command: yarn rmadmin -refreshQueues to make to its entry into force, without restarting Yarn cluster.
Note that: only supports dynamic updates modify the resource pool allocations, if it is to add or reduce resource pool, you need to restart Yarn cluster.
Edit yarn-site.xml
yarn集群主节点中yarn-site.xml添加以下配置
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim yarn-site.xml
<!-- 指定使用fairScheduler的调度方式 -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<!-- 指定配置文件路径 -->
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/fair-scheduler.xml</value>
</property>
<!-- 是否启用资源抢占,如果启用,那么当该队列资源使用
yarn.scheduler.fair.preemption.cluster-utilization-threshold 这么多比例的时候,就从其他空闲队列抢占资源
-->
<property>
<name>yarn.scheduler.fair.preemption</name>
<value>true</value>
</property>
<property>
<name>yarn.scheduler.fair.preemption.cluster-utilization-threshold</name>
<value>0.8f</value>
</property>
<!-- 默认提交到default队列 -->
<property>
<name>yarn.scheduler.fair.user-as-default-queue</name>
<value>true</value>
</property>
<!-- 如果提交一个任务没有到任何的队列,是否允许创建一个新的队列,设置false不允许 -->
<property>
<name>yarn.scheduler.fair.allow-undeclared-pools</name>
<value>false</value>
</property>
Add fair-scheduler.xml profile
<?xml version="1.0"?>
<allocations>
<!-- users max running apps -->
<userMaxAppsDefault>30</userMaxAppsDefault>
<!-- 定义队列 -->
<queue name="root">
<minResources>512mb,4vcores</minResources>
<maxResources>102400mb,100vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<weight>1.0</weight>
<schedulingMode>fair</schedulingMode>
<aclSubmitApps> </aclSubmitApps>
<aclAdministerApps> </aclAdministerApps>
<queue name="default">
<minResources>512mb,4vcores</minResources>
<maxResources>30720mb,30vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>1.0</weight>
<!-- 所有的任务如果不指定任务队列,都提交到default队列里面来 -->
<aclSubmitApps>*</aclSubmitApps>
</queue>
注释:
weight
资源池权重
aclSubmitApps
允许提交任务的用户名和组;
格式为: 用户名 用户组
当有多个用户时候,格式为:用户名1,用户名2 用户名1所属组,用户名2所属组
aclAdministerApps
允许管理任务的用户名和组;
All nodes distribute newly added to the cluster configuration file
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
scp yarn-site.xml fair-scheduler.xml node02:/$ PWD
scp yarn-site.xml fair-scheduler.xml node03:/$ PWD
(The $ PWD and intermediate spaces removed)
Restart Yarn cluster
stop-yarn.sh
start-yarn.sh
verification
a) adding user authentication required (disposed in the queue)
useradd hadoop
passwd hadoop
Gives hadoop user rights
Modify permission hdfs above tmp folder, or when the average user to perform tasks will throw an exception insufficient privileges. The following command in root user.
groupadd supergroup 添加组
usermod -a -G supergroup hadoop 修改用户所属的附加群主
su - root -s /bin/bash -c "hdfs dfsadmin -refreshUserToGroupsMappings"
刷新用户组信息
b) submit the task, view the browser to verify
su hadoop 使用hadoop用户提交程序
hadoop jar /export/servers/hadoop-2.6.0-cdh5.14.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.14.0.jar pi 10 20 查看界面
Demonstration Figure

Interface map