2. Yarn resource scheduler
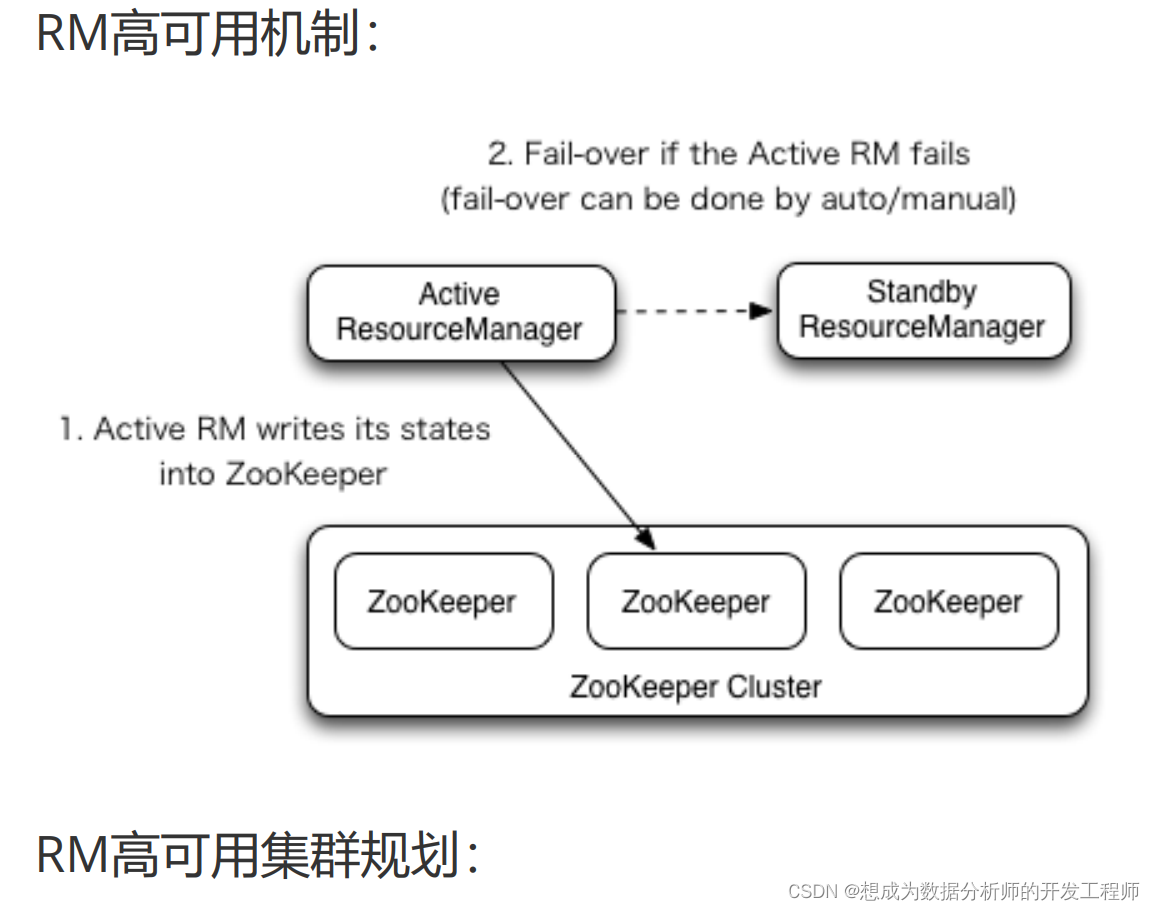
2.3 YARN resourcemanager-HA construction
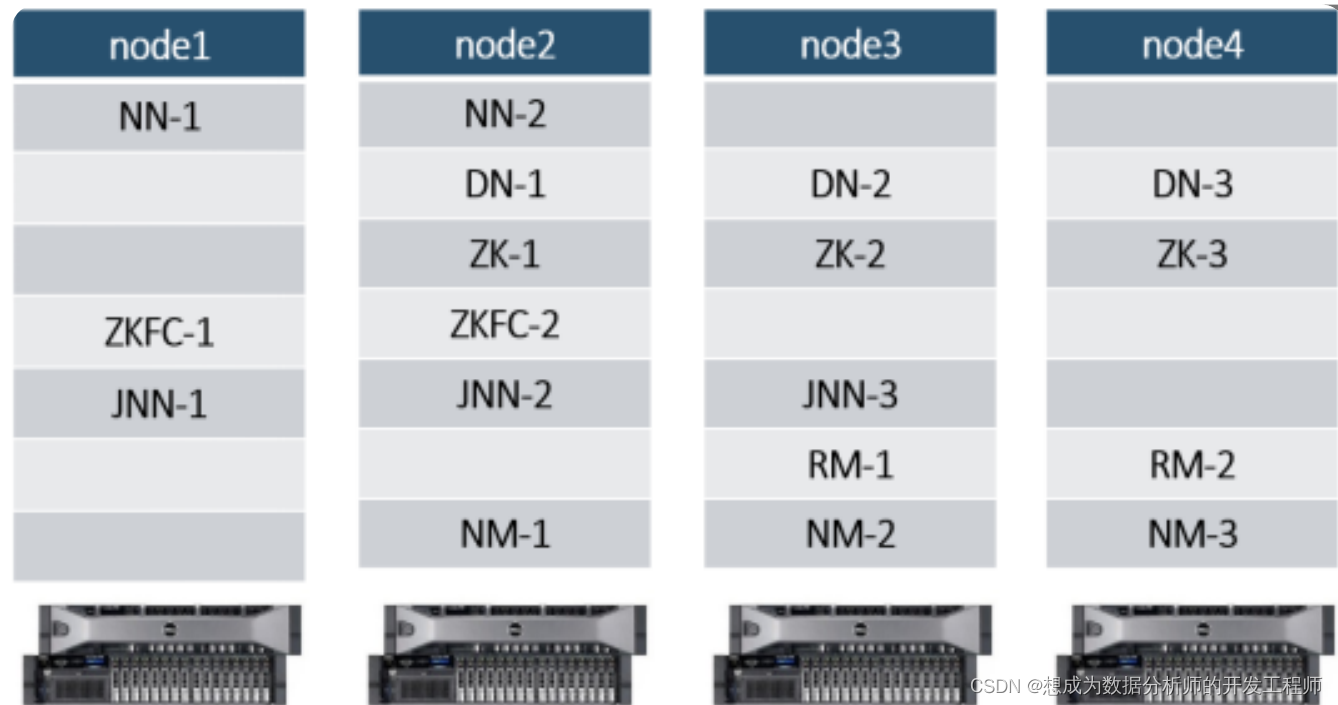
2.3.1 Document viewing and cluster planning
RM High Availability official website:
http://hadoop.apache.org/docs/r3.1.3/hadoopyarn/hadoop-yarn-site/ResourceManagerHA.html
Locally enter the document home page:
2.3.2 Related file configuration
- mapred-site.xml
local/classic/yarn
specifies the framework for the mr job to run: either run locally (local), or use
MRv1 (classic) (rarely used), or use yarn
[root@node1 ~]# cd /opt/hadoop-3.1.3/etc/hadoop/
[root@node1 hadoop]# vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- yarn-site.xml
[root@node1 hadoop]# pwd
/opt/hadoop-3.1.3/etc/hadoop
[root@node1 hadoop]# vim yarn-site.xml
<configuration>
<!-- 让yarn的容器支持mapreduce的洗牌,开启shuffle服务 -->
<property>
<name>yarn.nodemanager.auxservices</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 启用resourcemanager ha -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定zookeeper集群的各个节点地址和端口号 -->
<property>
<name>yarn.resourcemanager.zkaddress</name>
<value>node2:2181,node3:2181,node4:2181</value
>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</n
ame>
<value>true</value>
</property>
<!-- 指定RM的状态信息存储在zookeeper集群 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcema
nager.recovery.ZKRMStateStore</value>
</property>
<!-- 声明两台resourcemanager的地址 -->
<property>
<name>yarn.resourcemanager.clusterid</name>
<value>cluster-yarn1</value>
</property>
<!--指定resourcemanager的逻辑列表-->
<property>
<name>yarn.resourcemanager.ha.rmids</name>
<value>rm1,rm2</value>
</property>
<!-- rm1的配置 -->
<!-- 指定rm1的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node3</value>
</property>
<!-- 指定rm1的web端地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</
name>
<value>node3:8088</value>
</property>
<!-- 指定rm1的内部通信地址 -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>node3:8032</value>
</property>
<!-- 指定AM向rm1申请资源的地址 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm
1</name>
<value>node3:8030</value>
</property>
<!-- 指定供NM连接的地址 -->
<property>
<name>yarn.resourcemanager.resourcetracker.address.rm1</name>
<value>node3:8031</value>
</property>
<!-- rm2的配置 -->
<!-- 指定rm2的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node4</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</
name>
<value>node4:8088</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>node4:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm
2</name>
<value>node4:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resourcetracker.address.rm2</name>
<value>node4:8031</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.envwhitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDF
S_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCA
CHE,HADOOP_MAPRED_HOME,HADOOP_YARN_HOME</value>
</property>
<!-- yarn容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimumallocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximumallocation-mb</name>
<value>1024</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
<property>
<name>yarn.nodemanager.resource.memorymb</name>
<value>1024</value>
</property>
<!-- 关闭yarn对物理内存的限制检查 -->
<property>
<name>yarn.nodemanager.pmem-checkenabled</name>
<value>false</value>
</property>
<!-- 关闭yarn对虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.vmem-checkenabled</name>
<value>false</value>
</property>
</configuration>
Synchronize configuration files on four servers
[root@node1 hadoop]# pwd
/opt/hadoop-3.1.3/etc/hadoop
[root@node1 hadoop]#scp mapred-site.xml yarnsite.xml node[234]:`pwd`
2.3.3 Startup and testing
- Start:
Start HDFS cluster first on node1
[root@node1 ~]# starthdfs.sh
Execute the command on node3 and node4 to start ResourceManager:
#Node3:(只能启动本机上的ResourceManager和其他节点的NodeManager)
[root@node3 ~]# start-yarn.sh
Starting resourcemanagers on [ node3 node4]
ERROR: Attempting to operate on yarn
resourcemanager as root
ERROR: but there is no
YARN_RESOURCEMANAGER_USER defined. Aborting
operation.
Starting nodemanagers
ERROR: Attempting to operate on yarn
nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER
defined. Aborting operation.
#需要在start-yarn.sh和stop-yarn.sh中配置
YARN_RESOURCEMANAGER_USER和
YARN_NODEMANAGER_USER
[root@node3 sbin]# vim start-yarn.sh
#添加一下两条配置
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
[root@node3 sbin]# vim stop-yarn.sh
#添加一下两条配置
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
[root@node3 sbin]# start-yarn.sh
Starting resourcemanagers on [ node3 node4]
上一次登录:一 10月 25 18:00:49 CST 2021pts/1 上
Starting nodemanagers
上一次登录:一 10月 25 18:01:52 CST 2021pts/1 上
#注意:hadoop2.x版本中还需要在Node4启动另外一个RM
yarn-daemon.sh start resourcemanager
#可以通过jps查看,也可以调用node1上的allJps.sh脚本查
看:发现node3和node4上分别多一个RM进程,node2、
node3、node4上分别多出一个NodeManager进程。
#查看服务 arn rmadmin -getServiceState rm1
[root@node3 sbin]# yarn rmadmin -getServiceState rm1
standby
[root@node3 sbin]# yarn rmadmin -getServiceState rm2
active
#说明node4上ResourceManager为Active状态。
- Test:
Go to the zk cluster node to check:
[root@node4 ~]# zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
[hadoop-ha, itbaizhan, registry, rmstore, wzyy,yarn-leader-election, zk001, zookeeper]
[zk: localhost:2181(CONNECTED) 2] ls /rmstore
[ZKRMStateRoot]
[zk: localhost:2181(CONNECTED) 3] ls /yarnleader-election
[cluster-yarn1]
[zk: localhost:2181(CONNECTED) 4] get -s
/rmstore/ZKRMStateRoot
null
cZxid = 0x900000014
ctime = Mon Oct 25 18:00:34 CST 2021
mZxid = 0x900000014
mtime = Mon Oct 25 18:00:34 CST 2021
pZxid = 0x90000003e
cversion = 22
dataVersion = 0
aclVersion = 2
ephemeralOwner = 0x0
dataLength = 0
numChildren = 6
[zk: localhost:2181(CONNECTED) 5] ls /yarnleader-election/cluster-yarn1
[ActiveBreadCrumb, ActiveStandbyElectorLock]
[zk: localhost:2181(CONNECTED) 6] get -s /yarnleader-election/cluster-yarn1/Active
ActiveBreadCrumb
ActiveStandbyElectorLock
[zk: localhost:2181(CONNECTED) 6] get -s /yarnleader-election/cluster-yarn1/ActiveBreadCrumb
cluster-yarn1rm2
cZxid = 0x90000003a
ctime = Mon Oct 25 18:02:07 CST 2021
mZxid = 0x90000003a
mtime = Mon Oct 25 18:02:07 CST 2021
pZxid = 0x90000003a
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 20
numChildren = 0
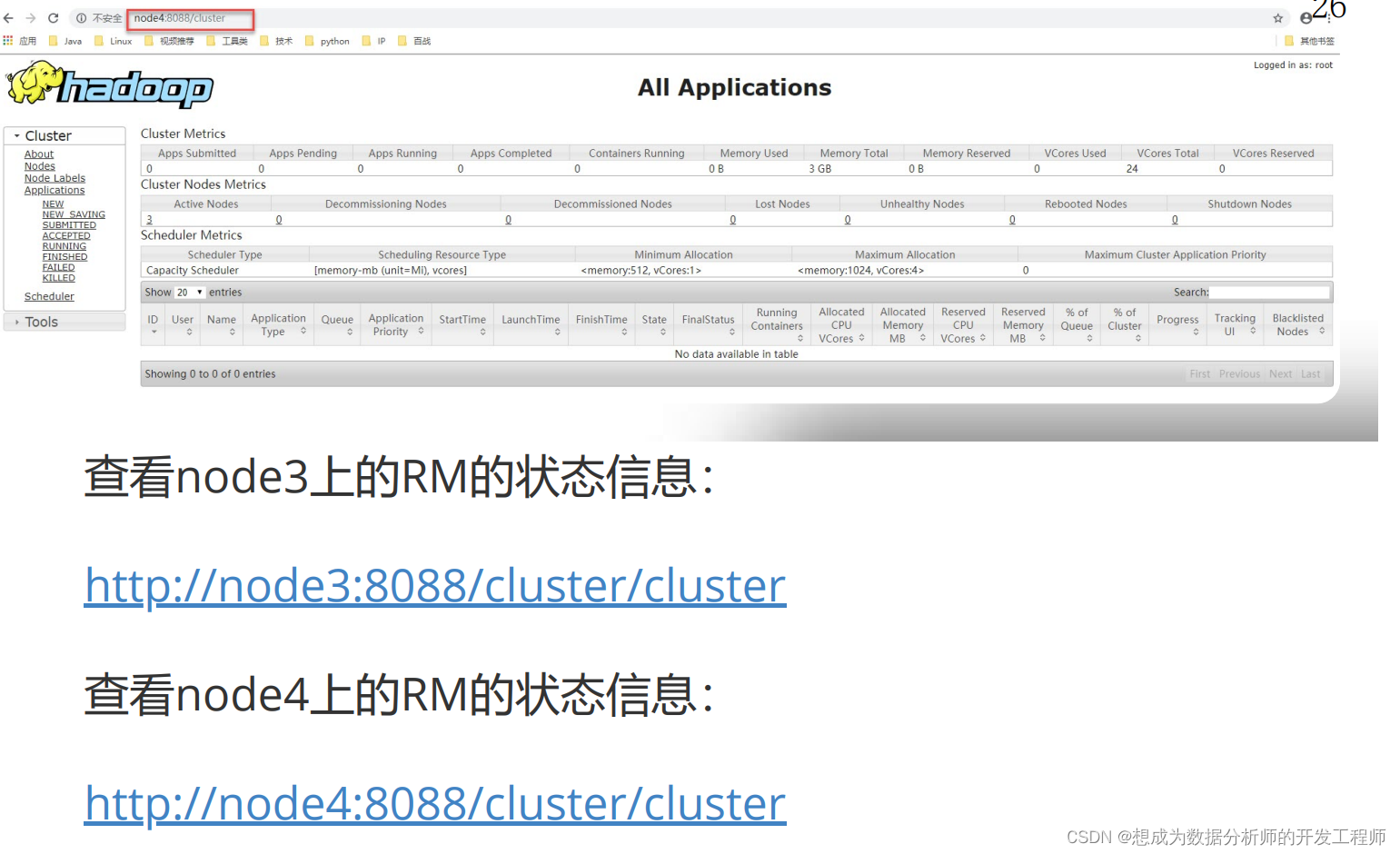
Test through the browser:
http://node3:8088 or http://node4:8088 will be redirected to the information page of the Active node. Currently, the RM on my node4 is Active:
2.3.4 Start script and stop script:
Hadoop cluster startup script: startha.sh (version 3.x)
[root@node1 ~]# cd bin/
[root@node1 bin]# vim startha.sh
#!/bin/bash
#启动zk集群
for node in node2 node3 node4
do
ssh $node "source /etc/profile;zkServer.sh start"
done
# 休眠1s
sleep 1
# 启动hdfs集群
start-dfs.sh
# 启动yarn_会自动起node4的rm
ssh node3 "source /etc/profile;start-yarn.sh"
# 查看四个节点上的java进程
allJps.sh
[root@node1 bin]# chmod +x startha.sh
Shutdown script of Hadoop cluster: startha.sh (version 3.x)
[root@node1 ~]# cd bin/
[root@node1 bin]# vim stopha.sh
[root@node1 bin]# chmod 755 stopha.sh
[root@node1 bin]# ll
总用量 20
-rwxr-xr-x 1 root root 217 3月 29 19:37 allJps.sh
-rwxr-xr-x 1 root root 293 4月 3 01:25 startha.sh
-rwxr-xr-x 1 root root 187 3月 29 19:36 starthdfs.sh
-rwxr-xr-x 1 root root 233 4月 3 01:32 stopha.sh
-rwxr-xr-x 1 root root 209 3月 29 19:39 stophdfs.sh
[root@node1 bin]# cat stopha.sh
#!/bin/bash
# 先关闭yarn
ssh node3 "source /etc/profile;stop-yarn.sh"
# 关闭hdfs
stop-dfs.sh
# 关闭zk集群
for node in node2 node3 node4
do
ssh $node "source /etc/profile;zkServer.sh stop"
done
# 查看java进程
allJps.sh
2.4.5 Yarn RM HA Construction - Resource Scheduler Introduction
Currently, Hadoop job schedulers are not good or bad, only suitable or not. Therefore, Hadoop provides three schedulers for users to choose from: FIFO, Capacity Scheduler, and Fair Scheduler. Hadoop3.1.3 default resource scheduler is Capacity Scheduler. For specific settings, see: yarn-default.xml file
<!-- 修改自己搭建集群的调度器,修改yarn-site.xml文件 -->
<property>
<description>The class to use as the resource scheduler.</description>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
2.4.6 Yarn RM HA builds a resource scheduler - first-in-first-out scheduler (FIFO)
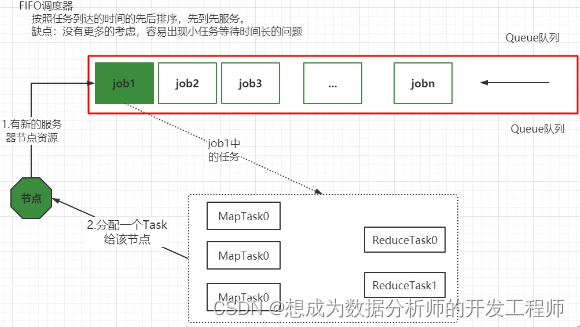
Hadoop was originally designed to support big data batch processing jobs, such as log mining, web indexing and other jobs. For this reason, Hadoop only provides a very simple scheduling mechanism: FIFO, that is, first come, first served. Under this scheduling mechanism, all Jobs are uniformly submitted to a queue, and Hadoop runs these jobs sequentially in the order they are submitted.
However, with the popularity of Hadoop, the task processing capacity of a single Hadoop cluster is increasing, and the applications submitted by different users often have different service quality requirements. Typical applications are as follows:
- Batch jobs: This kind of job often takes a long time and generally has no strict requirements on time completion, such as data mining, machine learning and other applications.
- Interactive job: This kind of job is expected to return results in time, such as HQL query (Hive), etc.
- Real-time statistics operation: This operation requires a certain amount of resource guarantee, such as the large screen of Taobao's transaction volume.
In addition, these applications have different requirements for hardware resources. Therefore, a simple FIFO scheduling strategy can not meet the diverse requirements, nor can it make full use of hardware resources.
2.4.7 Yarn RM HA build resource scheduler - capacity scheduler (Capacity Scheduler)
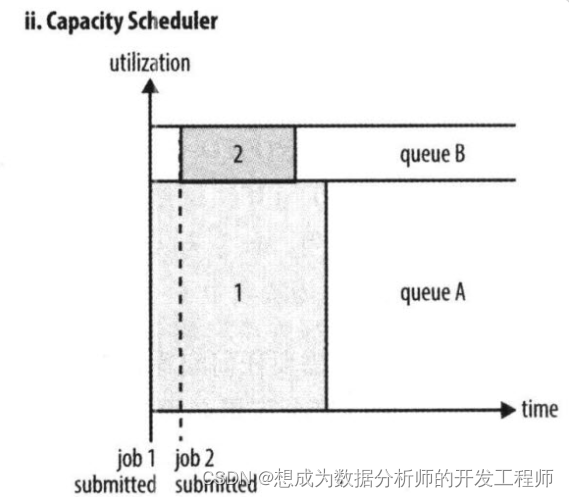
Capacity Scheduler is a multi-user scheduler developed by Yahoo.
- It divides resources in units of queues, supports multiple queues, and each queue can set a certain percentage of resource minimum guarantees and upper usage limits.
- Each queue adopts a FIFO scheduling strategy.
- In order to prevent the jobs of the same user from monopolizing the resources in the queue, the scheduler will limit the amount of resources occupied by the jobs submitted by the same user.
- When a task is submitted, calculate the ratio of the number of running tasks in each queue/the computing resources that should be allocated to the corresponding task, and assign the task to the queue with the smallest ratio (the most idle).
- The jobs at the front of each queue can run in parallel.
In short, Capacity Scheduler mainly has the following characteristics:
- Capacity guaranteed. Administrators can set resource minimum guarantees and resource usage caps for each queue, and all applications submitted to that queue share these resources.
- Flexibility, if there are remaining resources in a queue, they can be temporarily shared with those queues that need resources, and once a new application is submitted to this queue, the resources seconded by other queues will be returned to this queue. This flexible allocation of resources can significantly improve resource utilization.
- Multiple leases. Support multi-user shared cluster and multi-application running simultaneously. To prevent a single application, user, or queue from monopolizing resources in the cluster, administrators can add multiple constraints (such as the number of tasks that a single application can run at the same time, etc.).
- ASD. Each queue has a strict ACL list to specify its access users, and each user can specify which users are allowed to view the running status of their own application or control the application (such as killing the application). In addition, administrators can designate queue administrators and cluster system administrators.
- Dynamically update configuration files. Administrators can dynamically modify various configuration parameters as needed to realize online cluster management.
2.4.8 Yarn RM HA to build a resource scheduler - Fair Scheduler (Fair Scheduler)

Fair Scheduler is a multi-user scheduler developed by Facebook.
The goal of a fair scheduler is to have all jobs get an equal share of shared resources over time. When a job is submitted, the system will allocate idle resources to the new job, and each task will roughly get an equal amount of resources. Unlike traditional scheduling strategies, it will allow small tasks to be completed in a reasonable time, while not starving long-running, resource-intensive tasks!
Similar to the Capacity Scheduler, it divides resources in units of queues, and each queue can set a certain percentage of resource minimum guarantees and usage upper limits. At the same time, each user can also set a certain resource usage upper limit to prevent resource abuse; when a When there are surplus resources in the queue, the remaining resources can be temporarily shared with other queues.
Of course, Fair Scheduler also has many differences from Capacity Scheduler, which are mainly reflected in the following aspects:
① Fair sharing of resources. Within each queue, Fair Scheduler can choose to allocate resources to applications according to FIFO, Fair or DRF policies. in:
FIFO strategy
If FIFO is selected as the resource allocation strategy for each queue of the fair scheduler, the task shared queue resources in each queue is disabled. At this time, the fair scheduler is equivalent to the capacity scheduler mentioned above.
Fair strategy
The Fair strategy (default) is a resource multiplexing method based on the maximum-minimum fairness algorithm. By default, each queue uses this method to allocate resources internally. This means that if two applications are running simultaneously in a queue, each application will get 1/2 of the resources; if three applications are running simultaneously, each application will get 1/3 of the resources.
【Extension:】Example of max-min fairness algorithm:
1.不加权(关注点是job的个数):
有一条队列总资源12个, 有4个job,对资源的需求分别是:
job1->1, job2->2 , job3->6, job4->5
第一次算: 12 / 4 = 3
job1: 分3 --> 多2个
job2: 分3 --> 多1个
job3: 分3 --> 差3个
job4: 分3 --> 差2个
第二次算: 3 / 2 = 1.5
job1: 分1
job2: 分2
job3: 分3 --> 差3个 --> 分1.5 --> 最终: 4.5
job4: 分3 --> 差2个 --> 分1.5 --> 最终: 4.5
第n次算: 一直算到没有空闲资源
2.加权(关注点是job的权重):
有一条队列总资源16,有4个job
对资源的需求分别是: job1->4 job2->2 job3->10 job4->4
每个job的权重为: job1->5 job2->8 job3->1 job4->2
第一次算: 16 / (5+8+1+2) = 1
job1: 分5 --> 多1
job2: 分8 --> 多6
job3: 分1 --> 少9
job4: 分2 --> 少2
第二次算: 7 / (1+2) = 7/3
job1: 分4
job2: 分2
job3: 分1 --> 分7/3 --> 少
job4: 分2 --> 分14/3(4.66) -->多2.66
第三次算:
job1: 分4
job2: 分2
job3: 分1 --> 分7/3 --> 分2.66
job4: 分4
第n次算: 一直算到没有空闲资源
DRF strategy
DRF (Dominant Resource Fairness), the resource we mentioned before, is a single standard, for example, only memory is considered (also the default situation of yarn). But many times we have many kinds of resources, such as memory, CPU, network bandwidth, etc., so it is difficult for us to measure the proportion of resources that two applications should allocate.
Then in YARN, we use DRF to decide how to schedule: Suppose the cluster has a total of 100 CPUs and 10T memory, and application A needs (2 CPUs, 300GB), and application B needs (6 CPUs, 100GB). Then the two applications need the resources of A (2% CPU, 3% memory) and B (6% CPU, 1% memory) respectively, which means that A is memory-oriented and B is CPU-oriented. In this case , we can choose the DRF strategy to limit different resources (CPU and memory) in different proportions for different applications.
② Support resource preemption. When there are remaining resources in a queue, the scheduler will share these resources with other queues, and when a new application program is submitted in the queue, the scheduler will reclaim resources for it. In order to reduce unnecessary computing waste as much as possible, the scheduler adopts the strategy of waiting first and then forcing recycling, that is, if there are unreturned resources after waiting for a period of time, resource preemption will be performed: kill resources from those queues that overuse resources. Dead part of the task, and then release resources.
yarn.scheduler.fair.preemption=true Enable resource preemption through this configuration.
③Improve the response time of applets. Due to the use of the maximum and minimum fairness algorithm, small jobs can quickly obtain resources and run to completion,
3. Actual case of counting the number of words
3.1 Run the built-in wordcount
3.1.1 The command to run:
[root@node1 ~]# cd /opt/hadoop-3.1.3/share/hadoop/mapreduce/
[root@node1 mapreduce]# pwd
/opt/hadoop-3.1.3/share/hadoop/mapreduce
[root@node1 mapreduce]# ll *examples-3.1.3.jar
-rw-r--r-- 1 itbaizhan itbaizhan 316382 9月 12 2019 hadoop-mapreduce-examples-3.1.3.jar
[root@node1 ~]# cd
[root@node1 ~]# vim wc.txt
hello tom
andy joy
hello rose
hello joy
mark andy
hello tom
andy rose
hello joy
[root@node1 ~]# hdfs dfs -mkdir -p /wordcount/input
[root@node1 ~]# hdfs dfs -put wc.txt /wordcount/input
[root@node1 ~]# hdfs dfs -ls /wordcount/input
Found 1 items
-rw-r--r-- 3 root supergroup 80 2021-10-28 09:53 /wordcount/input/wc.txt
[root@node1 ~]# ll
-rw-r--r-- 1 root root 80 10月 28 09:52 wc.txt
[root@node1 ~]# cd -
/opt/hadoop-3.1.3/share/hadoop/mapreduce
[root@node1 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.1.3.jar wordcount /wordcount/input /wordcount/output
#出现如下bug:
Requested resource=<memory:1536, vCores:1>, maximum allowed allocation=<memory:1024, vCores:4>
By default, AM requests 1.5G of memory, so reduce the resource request configuration items of am to within the allocated physical memory limit.
Modify the configuration mapred-site.xml (must be modified on all four platforms), restart the hadoop cluster after the modification, and restart the execution
[root@node1 mapreduce] stopha.sh
[root@node1 mapreduce]# cd /opt/hadoop-3.1.3/etc/hadoop/
[root@node1 hadoop]# vim mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- job作业运行的资源管理使用Yarn -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>256</value>
</property>
<!-- 默认对mapred的内存请求都是1G,也降低和合适的值。-->
<property>
<name>mapreduce.map.memory.mb</name>
<value>256</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>256</value>
</property>
</configuration>
But if it is too low, there will be OOM problems. ERROR [main] org.apache.hadoop.mapred.YarnChild: Error running child : java.lang.OutOfMemoryError: Java heap space
[root@node1 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.1.3.jar wordcount /wordcount/input /wordcount/output
2021-10-28 10:33:10,194 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
2021-10-28 10:33:10,635 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1635388346175_0001
2021-10-28 10:33:10,837 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2021-10-28 10:33:11,853 INFO input.FileInputFormat: Total input files to process : 1
2021-10-28 10:33:11,927 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2021-10-28 10:33:12,042 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2021-10-28 10:33:12,092 INFO mapreduce.JobSubmitter: number of splits:1
2021-10-28 10:33:12,299 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2021-10-28 10:33:12,364 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1635388346175_0001
2021-10-28 10:33:12,364 INFO mapreduce.JobSubmitter: Executing with tokens: []
2021-10-28 10:33:12,662 INFO conf.Configuration: resource-types.xml not found
2021-10-28 10:33:12,663 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2021-10-28 10:33:13,177 INFO impl.YarnClientImpl: Submitted application application_1635388346175_0001
2021-10-28 10:33:13,235 INFO mapreduce.Job: The url to track the job: http://node4:8088/proxy/application_1635388346175_0001/
2021-10-28 10:33:13,235 INFO mapreduce.Job: Running job: job_1635388346175_0001
2021-10-28 10:33:22,435 INFO mapreduce.Job: Job job_1635388346175_0001 running in uber mode : false
2021-10-28 10:33:22,438 INFO mapreduce.Job: map 0% reduce 0%
2021-10-28 10:33:30,575 INFO mapreduce.Job: map 100% reduce 0%
2021-10-28 10:33:36,661 INFO mapreduce.Job: map 100% reduce 100%
2021-10-28 10:33:37,685 INFO mapreduce.Job: Job job_1635388346175_0001 completed successfully
2021-10-28 10:33:37,827 INFO mapreduce.Job: Counters: 53
File System Counters
FILE: Number of bytes read=71
FILE: Number of bytes written=442495
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=184
HDFS: Number of bytes written=41
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=5238
Total time spent by all reduces in occupied slots (ms)=3935
Total time spent by all map tasks (ms)=5238
Total time spent by all reduce tasks (ms)=3935
Total vcore-milliseconds taken by all map tasks=5238
Total vcore-milliseconds taken by all reduce tasks=3935
Total megabyte-milliseconds taken by all map tasks=2681856
Total megabyte-milliseconds taken by all reduce tasks=2014720
Map-Reduce Framework
Map input records=8
Map output records=16
Map output bytes=144
Map output materialized bytes=71
Input split bytes=104
Combine input records=16
Combine output records=6
Reduce input groups=6
Reduce shuffle bytes=71
Reduce input records=6
Reduce output records=6
Spilled Records=12
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=411
CPU time spent (ms)=1930
Physical memory (bytes) snapshot=375353344
Virtual memory (bytes) snapshot=3779186688
Total committed heap usage (bytes)=210911232
Peak Map Physical memory (bytes)=203862016
Peak Map Virtual memory (bytes)=1874542592
Peak Reduce Physical memory (bytes)=171491328
Peak Reduce Virtual memory (bytes)=1904644096
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=80
File Output Format Counters
Bytes Written=41
*input: is the directory where the data in the hdfs file system is located
*ouput: It is a directory that does not exist in hdfs, and the result of running the mr program will be output to this directory
3.1.2 Output directory contents:
[root@node1 mapreduce]# hdfs dfs -ls /wordcount/output
Found 2 items
-rw-r--r-- 3 root supergroup 0 2021-10-28 10:33 /wordcount/output/_SUCCESS
-rw-r--r-- 3 root supergroup 41 2021-10-28 10:33 /wordcount/output/part-r-00000
[root@node1 mapreduce]# hdfs dfs -cat /wordcount/output/part-r-00000
andy 3
hello 5
joy 3
mark 1
rose 2
tom 2
/_SUCCESS: is a signal/flags file
/part-r-00000: is the data file output by reduce
r: the meaning of reduce, 00000 is the corresponding reduce number, multiple reduce will have multiple data files