Yarn Scheduler Scheduler
Ideally, we applied a request for Yarn resources should immediately be met, but the reality resources are often limited, especially in a very busy cluster, request an application resource often need to wait for some time before to the appropriate resources . In Yarn, the application is responsible for allocating resources is the Scheduler . In fact, the scheduling itself is a problem, it is difficult to find a perfect strategy can solve all scenarios. For this purpose, Yarn offers a variety of scheduling and configurable strategy for us to choose.
Three scheduler may select the Yarn: FIFO Scheduler, Capacity Scheduler, Fair Scheduler.
FIFO Scheduler
After the FIFO Scheduler to submit the application in the order arranged in a queue, which is a FIFO queue, during the time of the allocation of resources, give the head of the queue in most applications allocate resources, to be the head of the most satisfying application requirements give the next assignment, and so on.
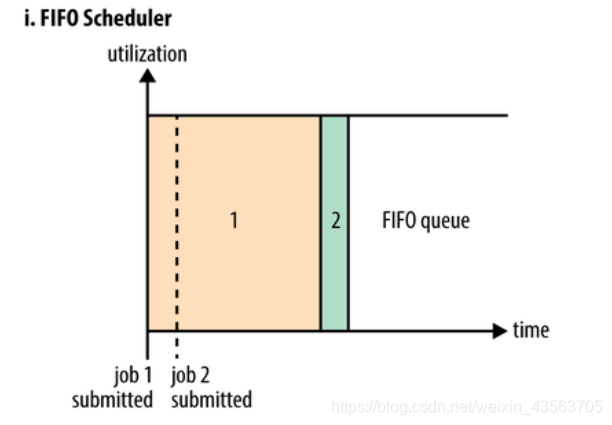
FIFO Scheduler is the simplest and most easily understood scheduler does not require any configuration, but it does not apply to shared clusters. Large applications may consume all cluster resources, which led to other applications are blocked. In a shared cluster, more suitable Capacity Scheduler or Fair Scheduler, both big task scheduler allow access to certain small tasks and system resources at the same time submitted.
Capacity Capacity Scheduler scheduler
Capacity Scheduler allow multiple organizations to share the entire cluster, each cluster computing part tissue can be obtained. By assigning a dedicated queue for each organization, then the entire cluster can provide services to multiple organizations and then assign each queue certain cluster resources, so by way of a plurality of queues. In addition, the internal queue and can be divided vertically, so that more members of an organization's internal resources can share this queue, in an internal queue, scheduling of resources is to use a first in first out (FIFO) policy
Configuring the cluster resource queue to get forms, each queue can preempt other queues available resources. Multiple queues can perform tasks at the same time. However, a FIFO queue or internal
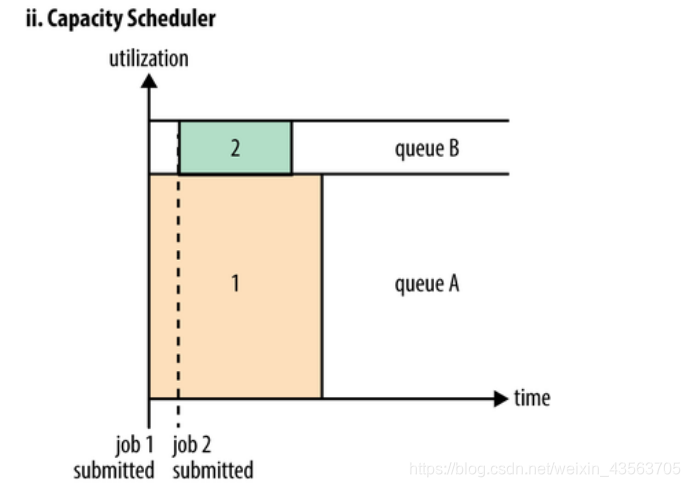
capacity scheduler Capacity Scheduler initially originally developed by Yahoo Hadoop applications to be designed so that the multi-user, and the resources to maximize throughput of the entire cluster, is now being used by IBM BigInsights and Hortonworks HDP.
Capacity Scheduler is designed to allow applications to share cluster resources in a predictable and simple way, the "job queue." Capacity Scheduler is an application of the existing resources allocated to the operation according to the tenant's needs and requirements. Capacity Scheduler while allowing applications to access resources not yet being used to ensure that the share of other queues are allowed to use the resource queues. Administrators can control the capacity of each queue, Capacity Scheduler is responsible for submitting jobs to the queue.
Fair Scheduler Fair Scheduler
In Fair scheduler, we do not need to pre-empt some system resources, Fair scheduler will run for the job dynamic adjustment of all system resources. As shown below, when the first big job submission, only this one job is running, this time it obtained all cluster resources; when the second small job submission, Fair scheduler will allocate resources to this small task half so that these two tasks fair share cluster resources.
Note that, in the figure Fair scheduler, task submission from the second to the availability of resources there will be some delay, because it needs to wait for the release of the first task occupied Container. Small task execution will release the resources they occupied after the completion of a large task and get all of the system resources. The final effect is that Fair Scheduler to obtain a high resource utilization but also to ensure the timely completion of small tasks.
Also configure a cluster resources to the column was in the form of, each queue can preempt other queues available resources. When the queue is preempted have a mission to seize the resources have to queue your money back. Resource money back will take some time.
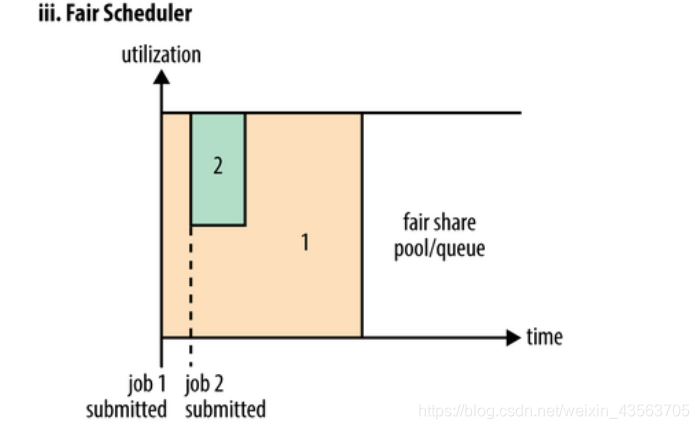
Fair Scheduler Fair Scheduler originally developed by Facebook design makes Hadoop application can be fairly shared by multiple users across a cluster resource, it is now being used by Cloudera CDH.
Fair Scheduler not need to keep cluster resources because it will dynamically balance resources among all running jobs.
Capacity scheduler is configured to use
Use scheduler by yarn-site.xml configuration file
configuring yarn.resourcemanager.scheduler.class parameters, defaults Capacity Scheduler scheduler.
Suppose we have the following levels of queues:
the root
├── Prod
└── dev
├── MapReduce
└── Spark
following is a simple scheduler Capacity configuration file named capacity-scheduler.xml. In this configuration, we define two sub-queues and prod dev in root queue below, respectively, 40% and 60% of capacity. Note that a queue configuration is specified by attribute yarn.sheduler.capacity .., represents the inheritance tree of queue, such as queue root.prod, generally refers to the capacity and maximum-capacity.
<configuration>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>prod,dev</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.queues</name>
<value>mapreduce,spark</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.prod.capacity</name>
<value>40</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.capacity</name>
<value>60</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.maximum-capacity</name>
<value>75</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.mapreduce.capacity</name>
<value>50</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.spark.capacity</name>
<value>50</value>
</property>
</configuration>
We can see, dev mapreduce the queue and is further divided into two sub-queues spark same capacity. dev's maximum-capacity property is set to become 75%, so even prod dev queue completely free and will not take up all cluster resources, that is to say, prod queue is still 25% of the available resources for emergency response. We note, mapreduce and two spark queue is not set maximum-capacity property, that is to say mapreduce or spark queue job could use all the resources of the entire dev queue (up to 75% of the cluster). While similar, prod because there is no set maximum-capacity property, it may take all cluster resources.
About setting up the queue, depending on our specific application. For example, MapReduce, we can use the designated queue by mapreduce.job.queuename property. If the queue does not exist, we will receive an error when submitting the task. If we do not define any queue, all applications will be placed in a default queue.
Note: For the Capacity Scheduler, our queue name must be the last part of the queue tree, if we use the Queue tree is not recognized. For example, in the configuration above, we use the prod and mapreduce as the queue name is possible, but if we use root.dev.mapreduce or dev. Mapreduce is invalid.
yarn multi-tenant resource isolation
In an internal company Hadoop Yarn cluster, it will certainly be more traffic, multiple users simultaneously, sharing Yarn resources, resource management and planning if not, then the entire Yarn resources can easily be submitted to one of the user's Application filled, can only wait for other tasks, this course is very unreasonable, we hope that each business has its own specific resources to run MapReduce tasks, Hadoop provides a fair scheduler -Fair scheduler, to meet this demand .
Yarn Fair Scheduler entire available resources into a plurality of resource pools, each pool of resources can be configured minimum and maximum available resources (memory and the CPU), the maximum number of simultaneous running Application, weight, and may be submitted to the Application Manager and users.
Fair Scheduler In addition to the need to enable and configure the yarn-site.xml file, you also need a fair-scheduler.xml XML file to configure resource pools and quota, and the quota for each XML resource pool can be dynamically updated after use the command: yarn rmadmin -refreshQueues to make its entry into force can be, without restarting Yarn cluster.
Note that: only supports dynamic updates modify the resource pool allocations, if it is to add or reduce resource pool, you need to restart Yarn cluster.
Edit yarn-site.xml
cluster master node yarn yarn-site.xml add the following configuration
CD /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
Vim yarn-site.xml
<!-- 指定使用fairScheduler的调度方式 -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<!-- 指定配置文件路径 -->
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/fair-scheduler.xml</value>
</property>
<!-- 是否启用资源抢占,如果启用,那么当该队列资源使用
yarn.scheduler.fair.preemption.cluster-utilization-threshold 这么多比例的时候,就从其他空闲队列抢占资源
-->
<property>
<name>yarn.scheduler.fair.preemption</name>
<value>true</value>
</property>
<property>
<name>yarn.scheduler.fair.preemption.cluster-utilization-threshold</name>
<value>0.8f</value>
</property>
<!-- 默认提交到default队列 -->
<property>
<name>yarn.scheduler.fair.user-as-default-queue</name>
<value>true</value>
</property>
<!-- 如果提交一个任务没有到任何的队列,是否允许创建一个新的队列,设置false不允许 -->
<property>
<name>yarn.scheduler.fair.allow-undeclared-pools</name>
<value>false</value>
</property>
Add fair-scheduler.xml profile
yarn master node performs the following command to add faie-scheduler.xml profile
CD /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
Vim Fair-scheduler.xml
<?xml version="1.0"?>
<allocations>
<!-- users max running apps -->
<userMaxAppsDefault>30</userMaxAppsDefault>
<!-- 定义队列 -->
<queue name="root">
<minResources>512mb,4vcores</minResources>
<maxResources>102400mb,100vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<weight>1.0</weight>
<schedulingMode>fair</schedulingMode>
<aclSubmitApps> </aclSubmitApps>
<aclAdministerApps> </aclAdministerApps>
<queue name="default">
<minResources>512mb,4vcores</minResources>
<maxResources>30720mb,30vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>1.0</weight>
<!-- 所有的任务如果不指定任务队列,都提交到default队列里面来 -->
<aclSubmitApps>*</aclSubmitApps>
</queue>
<!--
weight
资源池权重
aclSubmitApps
允许提交任务的用户名和组;
格式为: 用户名 用户组
当有多个用户时候,格式为:用户名1,用户名2 用户名1所属组,用户名2所属组
aclAdministerApps
允许管理任务的用户名和组;
格式同上。
-->
<queue name="hadoop">
<minResources>512mb,4vcores</minResources>
<maxResources>20480mb,20vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>2.0</weight>
<aclSubmitApps>hadoop hadoop</aclSubmitApps>
<aclAdministerApps>hadoop hadoop</aclAdministerApps>
</queue>
<queue name="develop">
<minResources>512mb,4vcores</minResources>
<maxResources>20480mb,20vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>1</weight>
<aclSubmitApps>develop develop</aclSubmitApps>
<aclAdministerApps>develop develop</aclAdministerApps>
</queue>
<queue name="test1">
<minResources>512mb,4vcores</minResources>
<maxResources>20480mb,20vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>1.5</weight>
<aclSubmitApps>test1,hadoop,develop test1</aclSubmitApps>
<aclAdministerApps>test1 group_businessC,supergroup</aclAdministerApps>
</queue>
</queue>
</allocations>
scp distribute the configuration file, restart the cluster yarn
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
scp yarn-site.xml fair-scheduler.xml node02:
PWD
stop-yarn.sh
start-yarn.sh
Create a regular user hadoop
node-1 following a normal user command to add
the useradd Hadoop
the passwd Hadoop
Gives hadoop user rights
Modify permission hdfs above tmp folder, or when the average user to perform tasks will throw an exception insufficient privileges. The following command in root user.
Supergroup groupadd
the usermod -a -G Supergroup hadoop modify additional user belongs to the main group
su - root -s / bin / bash -c "hdfs dfsadmin -refreshUserToGroupsMappings"
to refresh the user group information
Use hadoop user submitted program
Hadoop the su
Hadoop pi is the jar exportservershadoop260cdh5140sharehadoopmapreducehadoopmapreduceexamples260cdh5140jar 10 20
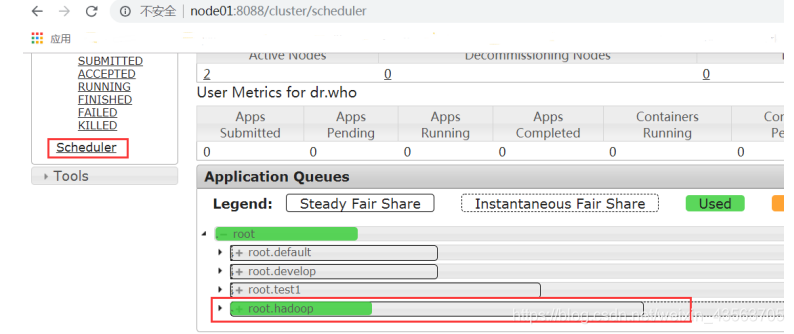
Browser View Results
http: // node-1: 8088 / cluster / scheduler
browser interface to access, view Scheduler, you can clearly see hadoop job submission to the queue to go inside.