Reptile process
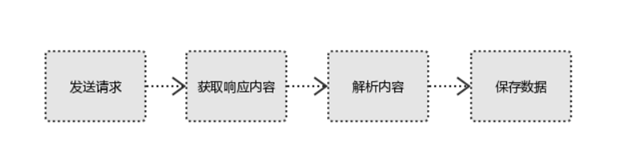
- Initiate a request to initiate a request to the target site by using the HTTP library, that sends a Request, the request may contain additional information such as headers, and wait for the server response.
- If the server response content can get a normal response, you'll get a Response, page content Response content is to be acquired, which will include: html, json, pictures, videos and so on.
- The resulting analytical content may be content html data, you can use regular expressions, such as third-party parsing library Beautifulsoup, etree and other data can be used to parse json json module, binary data, or can be stored for further processing.
- Save more pluralistic way of saving data can be stored in the database you can also use the file to be saved.
Regular Expressions
Regex (regular expression), also called regular expressions, often used to retrieve, replace the text in line with those of a model (rule) is. A regular expression is a logical formula of string operations, is to use some combination of a particular pre-defined characters, and these particular character, form a "string rule", this "rule string" is used to express characters Some filtering logic string. Expression is achieved by Chiang Kai-shek in the Python re module.
Regular expression matching rules
| symbol |
Explanation |
| . |
Used to match any one character, such as ac matches abc, aac, akc etc. |
| ^ |
For matches ... leading character, such as ^ abc matches abcde, abcc, abcak etc. |
| $ |
For the match ends with the character ... such as abc $ matches xxxabc, 123abc etc. |
| * |
Matches the preceding character zero or more times, such as abc * matches ab, abc, abcccc etc. |
| + |
Before a matching one or more characters, such as match abc + abc, abcc, abcccc etc. |
| ? |
A character zero or one time, such as abc before the match? Only to match ab and abc |
| \ |
Escape character, for example, I want to match ac, should be written as a \ .c, otherwise. Will be treated as matching character |
| | |
Any expression represents about a match, such as aaa | bbb matches aaa bbb can also match |
| [ ] |
Brackets match any one character, such as a [bc] d abd match and ACD, a range can be written as [0-9], [az] etc. |
| ( ) |
Bracketed expression as a packet, such as the (abc) {2} matches abcabc, a (123 | 456) b match a123b or a456b |
| {m} |
It represents a matching prior character m times as ab {2} c matches abbc |
| {m,n} |
M represents a character n times prior to the match, such as ab {1,2} c matches abc or abbc |
| \d |
Match numbers, such as a \ dc match a1c, a2c, a3c, etc. |
| \D |
Matching non-digital, i.e. in addition to any numeric characters or symbols, such as a \ Dc match abc, aac, ac, etc. |
| \s |
Whitespace match, i.e. matches a space, line breaks, tabs, etc., such as a \ sc match 'ac', a \ nc, a \ tc etc. |
| \S |
Matching non-whitespace character, i.e. matches a space, line breaks, any other characters or symbols other than the tab, such as a \ Sc represents addition 'ac' can match, abc, a3c, ac, etc. |
| \w |
Match case letters and numbers, i.e. matching [a-zA-Z0-9] characters, such as a \ wc match abc, aBc, a2c, etc. |
| \W |
Non-case letters and numbers match, i.e. any other characters or symbols other than letters and numbers match the case of such a \ Wc match ac, a # c, a + c, etc. |
Real 1: ppt crawled pages a picture page
import re,requests
#参数设置
page_num=2#页面数
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}#请求头信息,模拟浏览器进行请求
#开始爬取
for n in range(page_num):
url='http://www.1ppt.com/beijing/ppt_beijing_{}.html'.format(n+1)
response=requests.get(url,headers=headers)#发送请求
if response.status_code==200:
response.encoding=response.apparent_encoding#字符编码设置为网页本来所属编码
html=response.text#获取网页代码
pattern= re.compile(r'img src="(.*?jpg)" alt')#编译正则表达式
image_url= pattern.findall(html)#解析图片链接
for i,link in enumerate(image_url):
print('第{}页第{}张图片下载中......'.format(n+1,i+1))
resp=requests.get(link,headers=headers)#请求图片链接
content=resp.content#获取二进制内容
with open('./图片/{}-{}.jpg'.format(n+1,i+1),'wb') as f:
f.write(content)#下载图片
else:
print('请求失败!')Combat 2: ppt crawled pages two pages pictures
import requests,re
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'}#请求头,模拟浏览器进行请求
page_num=2
for i in range(page_num):
url='http://www.1ppt.com/beijing/ppt_beijing_{}.html'.format(i+1)
print('第{}页爬取中......'.format(i+1))
response=requests.get(url,headers=headers)#向一级网页发送请求
if response.status_code==200:
response.encoding=response.apparent_encoding#字符编码设置为网页本来所属编码
html=response.text#获取网页代码
pattern=re.compile(r'<li> <a href="(.*?)" target="_blank">')#编译正则表达式
url_sub=pattern.findall(html)#解析二级页面链接
url_sub=['http://www.1ppt.com'+x for x in url_sub]#拼接成完整链接
for j,link in enumerate(url_sub):
print('第{}页第{}个ppt爬取中......'.format(i+1,j+1))
resp=requests.get(link,headers=headers)#向二级网页发送请求
if resp.status_code==200:
resp.encoding=resp.apparent_encoding#字符编码设置为网页本来所属编码
html_sub=resp.text#获取网页代码
pattern=re.compile(r'img src="(.*?)" width="700"')#编译正则表达式
image_link=pattern.findall(html_sub)#解析图片链接
for k,li in enumerate(image_link):
response_image=requests.get(li,headers=headers)#请求图片链接
content=response_image.content#获取图片二进制内容
with open('./图片/{}-{}-{}.jpg'.format(i+1,j+1,k+1),'wb') as f:
f.write(content)#下载图片
else:
print('第{}页第{}个ppt链接请求失败!'.format(i+1,j+1))
else:
print('第{}页一级页面请求失败!'.format(i+1))
